基于多源公开数据的企业专利推荐系统
本发明属于企业专利推荐,具体为基于多源公开数据的企业专利推荐系统。
背景技术:
1、企业专利推荐系统利用机器学习等技术对专利文本内容和专利数据指标进行分析,全面挖掘和提取企业技术偏好,客观识别核心专利。因此,这些系统可以帮助企业用户获得符合其技术偏好的高质量专利,并为专利布局、专利监测、专利评估和专利规避等战略决策提供重要参考。同时,也便于企业将专利数据作为研发活动的产出指标,用于商业应用和实证研究。多种数据源的融合有望成为企业专利推荐领域的一种有前途的方法,从而提高推荐的准确性和相关性。通过结合各种数据源,如专利文本特征、公司偏好和技术趋势,多源数据融合方法提供了对专利相关性的全面洞察,并使推荐符合企业的特定需求和偏好。
2、但是常见的专利推荐系统不能强调使用公开数据和非敏感信息,对于企业的隐私不能进行很好的保护。
技术实现思路
1、本发明的目的在于:为了解决上述提出的问题,提供基于多源公开数据的企业专利推荐系统。
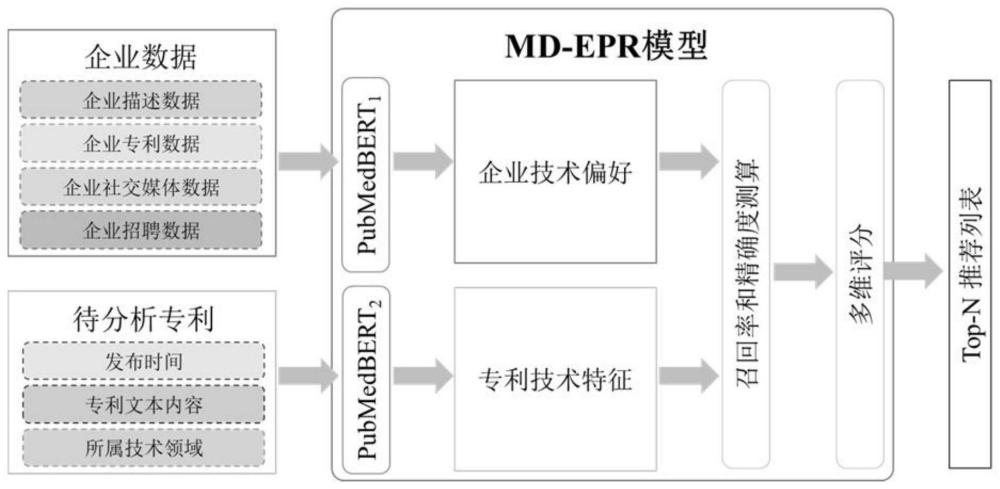
2、本发明采用的技术方案如下:基于多源公开数据的企业专利推荐系统,其特征在于:所述基于多源公开数据的企业专利推荐系统包括:定义和收集多源企业数据、对多源数据进行预处理、从不同数据源中提取和合并技术偏好、专利召回和排序、分析和评估多源数据融合专利推荐的结果。
3、在一优选的实施方式中,所述定义和收集多源企业数据首先检索处理后的专利数据,然后应用tf-idf、doc2vec(dbow、dm)、pubmedbert模型等多种特征提取技术提取专利特征,构建企业技术偏好特征;随后,对每个企业进行专利推荐;收集实验结果,分析不同模型的精度、召回率和f-score;最后,生成趋势图对性能指标进行可视化分析;
4、在本研究中,精确度表示推荐的专利中符合企业技术偏好的专利所占的比例,召回率表示成功推荐的所有相关专利所占的比例。
5、在一优选的实施方式中,所述精确度表示推荐的专利中符合企业技术偏好的专利所占的比例,召回率表示成功推荐的所有相关专利所占的比例;企业专利推荐的精确度和召回率的计算公式如下:
6、
7、
8、这里r(u)表示推荐名单中该企业专利的ipc字段集合,而t(u)表示企业专利的ipc字段集合;
9、f-measure是精确度和召回率的加权调和平均值,用于综合评估推荐系统的性能;f-measure越高,说明模型的推荐性能越好;f-measure的计算公式如下:
10、
11、实验结果表明,pubmedbert模型在所测试的模型中精度最高,平均推荐精度达到88.15%,令人印象深刻;当考虑召回率指标时,pubmedbert模型的表现同样显著;当考虑固定推荐数(top-n)时,pubmedbert模型的召回率始终优于其他模型;这表明,与tf-idf和doc2vec模型相比,pubmedbert模型在提取企业技术偏好信息方面表现出色,使得专利推荐更符合企业的偏好。
12、在一优选的实施方式中,所述专利召回和排序分为"召回阶段"和"排名阶段";在召回阶段,采用低复杂度的召回规则、算法或模型,从候选项目池中有效地检索出符合用户偏好的项目子集;然后,这些检索到的项目进入排序阶段,排序指标、算法或模型被用于对检索到的项目列表进行进一步排序,并生成最终的推荐列表。
13、在一优选的实施方式中,所述回顾阶段应用召回公式计算相似度得分、sij企业的技术偏好特征与专利特征之间的相似度得分;其中,i代表第i家企业,j代表候选专利库中的第j项专利;通过精确排序,提炼出相似度得分最高的前500件专利sij。
14、在一优选的实施方式中,所述排名阶段为了考虑推荐专利的"时效性"、"创新性"和"新颖性"等指标,利用专利的发表日期、引用次数和ipc字段等属性分别计算出每件专利的时效性、创新性和新颖性得分;根据这些得分,对回收的专利进行精确排序;然后从重新排序的结果中选择前n项专利生成最终的企业推荐列表。
15、在一优选的实施方式中,所述排名阶段及时性"因素反映了专利公布日期的新旧程度,表明其所涉及技术的尖端性质;
16、及时性的计算公式如下t0的计算公式如下,其中α代表时间衰减因子;如果该领域的技术进步较快,导致专利时效变化较快,则α值宜较大;这里t0代表候选专利库中的最新公布日,t对应于推荐列表中专利的公布日:
17、
18、所述创新得分i0的计算公式如下,其中x表示专利在推荐列表中的引用次数:
19、
20、新颖性的计算公式为n0定义如下,其中set(p)代表候选专利的ipc领域集,而set(c)代表企业专利的ipc领域集:
21、
22、所述被召回专利的排名得分r用下式计算,其中η,μ和ζ分别为及时性、创新性和新颖性的加权系数:
23、r=s×(ηt0+μi0+ζn0)#(7)。
24、在一优选的实施方式中,所述分析和评估模块的内部设置有多维评分模型,通过对推荐列表中的专利进行评分来评价多源数据融合企业专利推荐模型的推荐效果;具体评分标准如下:
25、(1).领域相似度(d):表示推荐列表中专利的技术领域与企业技术领域集的相似度;计算方法如下:如果推荐专利的前3个ipc技术领域都在企业的ipc技术领域集d中,则得5分;如果有两个领域在d中,则得3分;如果没有一个领域在d中,则得分为1;
26、(2).专利创新表示被引用次数较少的专利得分较高,表明原创性较高;评分公式如下:
27、
28、(3).专利及时性(t):越接近现在公布的专利代表越尖端的技术;专利的时效性是根据专利的公布日期用时间衰减函数计算出来的,计算公式为:
29、
30、在一优选的实施方式中,所述分析和评估模块的内部如果推荐列表中某项专利的技术领域不在企业以往的技术领域范围内,但仍然符合企业的技术偏好,则表示该专利具有新颖性;它反映了推荐清单中专利的技术领域与企业技术领域集之间的差异;差异越大,新颖性得分越高;评分标准如下:如果推荐专利的第一个ipc主组(c02f9)不在企业的技术领域集中,则得5分;如果第一个ipc主组(c02f9)存在,但子组(c02f9/06)不存在,则得3分;如果第一个ipc子组(c02f9/06)在企业的技术领域集内,则得1分。
31、在一优选的实施方式中,所述分析和评估模块在计算出推荐列表中每项专利的单项得分后,使用欧氏距离公式计算出综合得分(分数),然后将得分分为三个等级:得分大于0.6的为"优秀",得分在0.4至0.6之间的为"良好",得分低于0.4的为"一般";然后分析这三类专利在推荐列表中的分布情况,综合得分的计算公式如下:
32、
33、综上所述,由于采用了上述技术方案,本发明的有益效果是:
34、本发明中,提出了一种三阶段实现的多源数据企业专利推荐(md-epr)模型。该模型旨在整合各种来源的数据,在不非法获取数据的情况下提供更准确、更全面的推荐。该过程包括以下步骤:定义和收集多源企业数据、对多源数据进行预处理、从不同数据源中提取和合并技术偏好、专利召回和排序、分析和评估多源数据融合专利推荐的结果;通过使用自然语言处理技术、机器学习算法和数据集成方法,我们提出了一个分析专利文本内容、提取相关特征并为企业提供专利推荐的框架。我们的方法通过利用非公开和公开披露的数据来确保透明度、公平性和问责制。本发明有助于在企业专利领域开发更有效、更注重隐私的推荐系统。总之,我们的研究结果和方法可以为研究人员、从业人员和政策制定者提供有价值的见解,从而推动负责任的推荐系统的发展,提高企业专利推荐的效率和有效性,同时维护道德原则和隐私标准。
- 还没有人留言评论。精彩留言会获得点赞!