一种基于对比学习的序列推荐方法及系统
本发明涉及序列推荐领域,尤其涉及一种基于对比学习的序列推荐方法及系统。
背景技术:
1、推荐系统作为现在社会重要的信息过滤方式受到了极高的关注度,推荐系统的本质是通过矩阵分解、深度学习、自编码器等各种方法来实现用户与项目特征的匹配,根据用户的兴趣分类标签、历史行为记录以及其他用户个人信息等来挖掘其个性化的喜好与需求,对其进行定制化服务。
2、序列推荐系统需要收集、处理和存储大量的用户和项目数据,这些数据必定包括时间戳信息,可能包括其他如用户的历史行为、兴趣偏好等信息,以及项目的属性、类别、标签等信;推荐系统需要对这些数据进行预处理、特征提取和表示学习,以便后续的推荐模型使用。推荐模型是推荐系统的核心,它可以挖掘数据所隐含的信息,预测用户对不同项目的喜好程度或评分。然而,现有的序列推荐方法仍然存在一些问题和挑战:首先,在序列推荐算法中,需要获得足够多的训练数据以支持模型训练,而用户行为数据通常呈现稀疏性,即大多数项目缺乏用户行为记录,这导致在模型的训练过程中可能面临数据不足的问题,从而对模型的准确性和泛化性能造成影响。其次,现有的序列推荐模型中常使用自注意力层堆叠,过多的自注意力层可能导致模型参数过多,以及对原始数据中存在的噪声信息过度敏感,这可能导致模型出现过拟合和不稳定性问题。
3、因此,亟需解决现有序列推荐方法中推荐模型训练数据不足和推价模型出现过拟合及不稳定情况的技术问题。
技术实现思路
1、本发明提供了一种基于对比学习的序列推荐方法及系统,用以解决现有序列推荐方法中推荐模型训练数据不足和推荐模型出现过拟合及不稳定情况的技术问题。
2、为实现上述目的,本发明提供了一种基于对比学习的序列推荐方法,包括以下步骤:
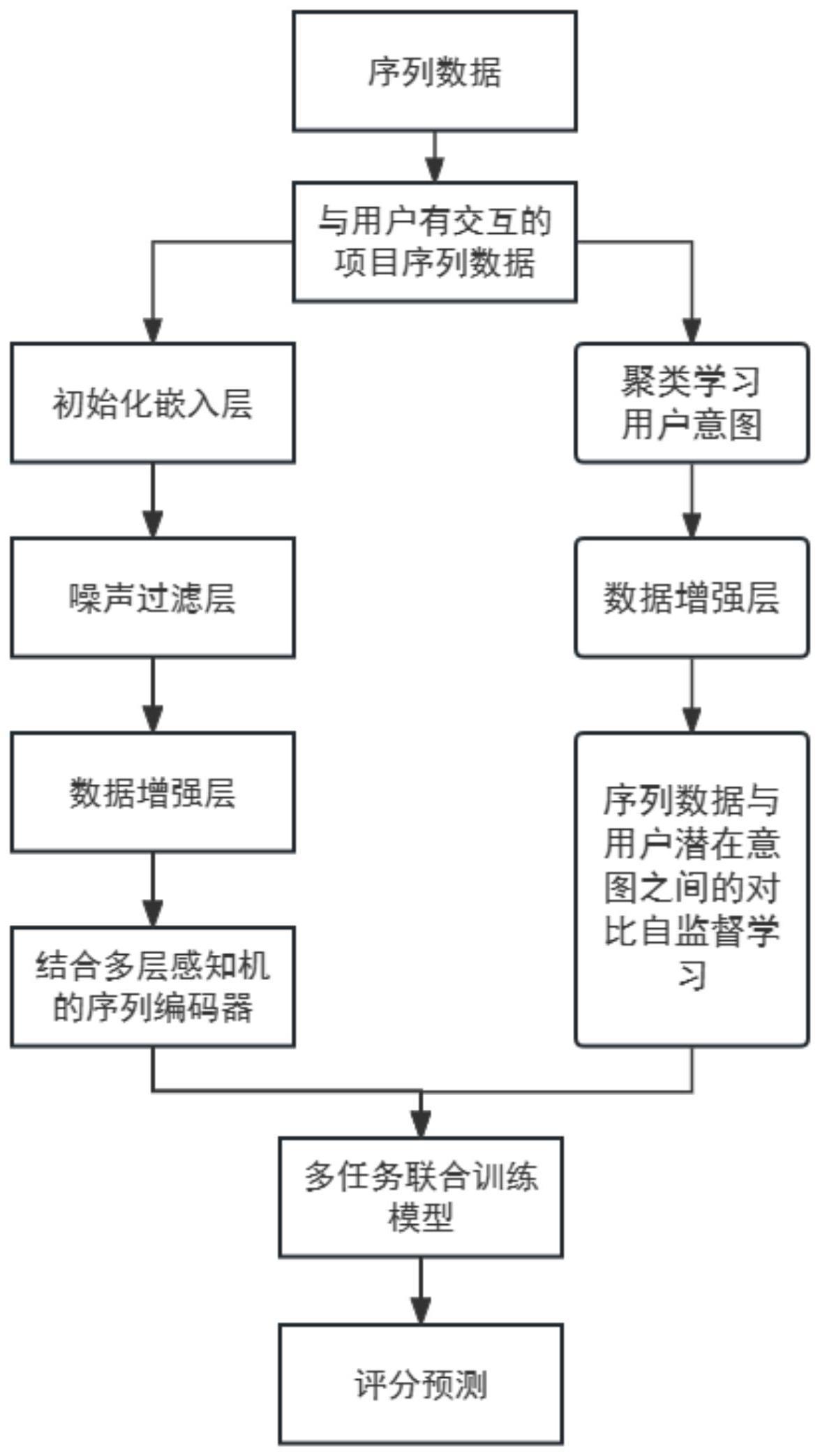
3、s1、收集用户与项目的历史交互行为序列数据,根据嵌入层进行编码,得到用户和与用户有交互记录的项目的初始嵌入表示;
4、s2、将初始嵌入表示输入滤波器组进行滤波,得到去噪嵌入表示;根据行为序列数据通过聚类算法得到用户意图信息;
5、s3、使用以前馈神经网络为主体的序列编码器结合去噪嵌入表示作为第一训练输入;通过对比自监督算法将用户意图信息与序列编码器的输出序列表征相结合作为第二训练输入;将第一训练输入和第二训练输入同时用于序列推荐模型的训练;得到预测评分,最终进行序列预测。
6、优选的,在s1中包括:收集用户与项目的历史交互行为序列数据,通过预训练过的嵌入层进行编码,将用户和项目的高维表示映射成低维稠密的向量表示,从而将每个历史行为转换成一个向量表示,再通过拼接操作得到用户和与用户有交互记录的项目的初始嵌入表示。
7、优选的,在s2中还包括:得到去噪嵌入表示后,对去噪嵌入表示进行数据增强:在每个时间步和每个序列中采样一个负面项,将负面项与正面项进行比较;正面项为用户互动过的物品,负面项为用户未互动过的物品;
8、得到用户意图信息后,对用户意图信息对应的行为序列数据进行数据增强:利用自监督学习或插入或替换的数据增强手段对用户意图信息对应的行为序列数据进行处理,构造正样本和负样本,正样本为用户真实交互过的商品,负样本为用户没有交互的商品。
9、优选的,方法还包括:收集用户与项目的历史交互行为序列数据后,首先对数据进行预处理:
10、将用户和项目分别用u和i表示,u∈u表示一个用户,i∈i表示一个项目;每个用户u都有按时间顺序排列的与之交互的项目序列预处理时,若项目序列长度大于l,则考虑项目序列中最近的l个交互行为,将项目序列截断至长度l;若序列长度小于l,将预设填充项目添加到序列中,直到序列的长度达到l。
11、优选的,滤波器组由多个可自动学习的滤波器叠加组成,对于给定的第l层的输入项目表示矩阵fl,fl∈rn×d,先沿着项目的维度执行快速傅里叶变换,将fl转换为频域信号xl,然后通过相乘滤波器w,w∈cn×d来调制频谱:
12、
13、其中,⊙是元素级乘法,滤波器w表示可自动学习的滤波器,是去噪后得到的频域信号。
14、优选的,在s2中,根据行为序列数据通过聚类算法得到用户意图信息包括:
15、以用户对应的行为序列数据作为监督信号,通过序列编码器对所有序列进行编码,通过聚合方法输出用户的意图表征序列
16、利用聚类算法对输出的用户意图表征进行处理,得到用户的潜在意图分布函数q(c,):
17、
18、其中,pθ(c,|su)表示用户u在行为序列s的情况下,属于用户意图ci的概率;
19、得到用户意图分布函数q(c,)后再通过平均池化对簇中的表征求均值,进而得到聚类的中心即得到用户潜在意图的表征c,。
20、优选的,以前馈神经网络为主体的序列编码器中,针对第l层的序列编码器的输出表示可以表示为:
21、
22、
23、其中,w1、b1、w2、b2为训练的参数,w1表示序列混合器中第一个完全连接层的可学习权重,b1表示序列混合器中第一个完全连接层的可学习偏置,w2表示序列混合器中第二个完全连接层的可学习权重,b2表示序列混合器中第二个完全连接层的可学习偏置,ffn表示前馈神经网络;为经过滤波的第l层的输入项目表示矩阵;relu为非线性激活函数。layernorm表示层归一化操作;dropout表示退出操作。
24、优选的,得到用户潜在意图的表征c,后,再进行行为序列与其相应潜在意图之间的互信息最大化,推导得到用户与某个项目的交互概率表示pθ(su,ci)和优化目标函数为:
25、
26、
27、其中,sim表示内积操作;exp表示指数函数;pθ(ci)pθ(su|cu)表示用户u在同时发生行为序列s和属于用户意图ci的情况下的概率。
28、优选的,在推导得到用户与某个项目的交互概率表示和优化目标函数后,还包括:
29、根据对比自监督学习的原理,对每个batch-size中训练的序列进行数据增强,创建两个正视图和对模型进行优化,优化损失函数为:
30、
31、
32、
33、其中,c表示具有相同意图的用户集合;
34、随后,通过基于项目相似性的预计算方法,选取最相似的项目来进行插入或替换操作,实现数据增强;同时考虑到两个行为序列之间的关联性和在对比学习中的互信息最大化,对行为序列进行编码,构建另一组损失函数:
35、
36、
37、
38、其中,为负视图下生成的序列表征;
39、在模型的最后一层预测层中,计算第(t+1)步中用户对项目i的兴趣评分p:
40、
41、其中,ai是项目i的向量表示,ht是步骤t中序列编码器的输出;
42、最后,采用多任务联合损失函数对模型参数进行训练和优化:
43、
44、其中,参数β和d分别调控序列与意图对比学习任务、序列与序列对比学习任务的程度;其中是未加入用户意图的序列编码器的二元交叉熵损失函数。
45、本发明还提供了一种基于对比学习的序列推荐系统,包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,处理器执行计算机程序时实现本发明方法的步骤。
46、本发明具有以下有益效果:
47、本发明针对序列推荐中可能存在的如用户恶意行为噪声、物品噪声、上下文噪声等噪声信息的问题,通过自学习的滤波器组,进行滤波操作,得以降低初始嵌入表示中影响序列推荐模型性能的噪声,得到去噪后的嵌入表示,这样的处理提高了模型对噪声和冗余信息的鲁棒性。本发明利用所有用户对应的行为序列数据作为监督信号,通过聚类算法学习不同用户的潜在意图及其关联性。本发明采用的聚类算法可以帮助将用户分组为具有相似行为模式和兴趣偏好的群体,通过将用户聚类到不同的群体中,可以更好地理解用户的行为和兴趣的多样性。这种学习过程有助于更好地理解用户的行为模式和偏好,有助于进行个性化推荐。本发明改进了基于自注意力机制的序列编码器,通过使用多层感知机架构进行建模,结合去噪后的嵌入表示进行模型训练。通过优化模型参数,本发明能够更准确地捕捉时间动态和顺序模式。结合聚类算法学习到的用户潜在意图,引入语义感知的对比学习机制,通过比较正样本和负样本之间的差异,能够识别出正样本与负样本之间的关联性和相似性,从而提升对用户真实意图的理解和建模。
48、除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照附图,对本发明作进一步详细的说明。
- 还没有人留言评论。精彩留言会获得点赞!