一种基于VIVADO平台的SM2椭圆曲线素数域模乘器的FPGA实现方法与流程
本发明涉及信息安全及信息对抗,具体涉及一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法。
背景技术:
1、密码算法实现作为密码工程学中一项富有技巧性和艺术性的工作,包含了硬件平台、软件平台、算法描述、吞吐量、密码资源、可靠性等诸多现实中需要考虑的问题。近年来,随着fpga工艺的发展,为了满足实际使用中高速率和低功耗的要求,越来越多的密码算法有了相应的硬件实现和优化方法。和cpu实现不同,fpga实现除了关注密码算法的高速实现和资源优化,还需要考虑如何将密码运算拆解成不同的子模块,并将可以同时进行计算的部分放在同一个时钟进行,而且还要规划每个时钟内的计算量,因为这些影响了运算所需的时钟数、fpga运行的最大时钟频率和实现面积,从而也影响了算法实现的吞吐量和可靠性。
2、vivado是xilinx公司的一款fpga开发软件,支持了包括k7、v7等许多不同系列和型号的芯片。sm2椭圆曲线公钥密码算法是国家密码管理局于2010年提出的一套商用密码算法标准,包含了数字签名算法、密钥交换协议和公钥加密算法,满足了多种密码应用中的数据机密性、数据完整性、身份认证和真实性的安全需求。素数域上模乘作为sm2算法中计算开销最大的一个子模块,对sm2的计算性能影响最大,因此模乘器的实现好坏对sm2的实现效果就起到了至关重要的作用。
3、目前,针对sm2素数域模乘器,密码学者已经提出了多种不同的fpga实现方法,然而这些实现仍然存在一些改进空间,比如模乘器运行的最大时钟频率和模乘计算所需的时钟数。现有sm2模乘器主要有以下不足之处:
4、(1)可靠性低。可靠性主要受最大时钟频率的影响,最大时钟频率越高,时序余量越大,fpga可靠性越高。现有大多数sm2模乘器的fpga最大时钟频率只有几十兆赫兹,和实际中使用最多的100mhz时钟相比还有一些差距。
5、(2)模乘计算所需时钟数没有达到最优。在进行模乘计算时,有些工作将模乘器分成了两个模块,一个进行乘法操作,一个进行模约减操作,然而两个模块交互的时候,通过控制信号跳转有时会额外占用时钟数。另外,在实现乘法操作时,对于累加操作,时钟数也没有得到很好的精简。
6、(3)实现面积大。fpga的实现面积主要会影响芯片功耗,fpga的实现面积越大,功耗越高。现有模乘器的实现面积主要体现在使用的查找表个数。通过减少lut(查找表)、ff(触发器)或者其他部件的使用,可以降低芯片功耗。
7、文献g.yang,f.kong and q.xu,optimized fpga implementation of ellipticcurve cryptosystem over prime fields,2020ieee trustcom,guangzhou,2020,pp.243-249中使用6701个lut得到sm2素数域模乘的结果,运算时间较长。
8、因此,需要一个将现有模乘器优化的方法。
技术实现思路
1、本发明是为了解决由于硬件实现代码不够精简优化和软件配置造成的sm2模乘器可靠性低、时钟数冗余和实现面积大的问题,提供一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,对模乘的计算采用了单独模块来完成,和使用多个模块的实现方式相比,减少了模块交互额外占用的时钟;并将可以同时计算且互不影响的部分尽量放在一个时钟,将并行尽可能最大化;通过优化加减法的运算过程和运算中的wire变量,一方面可以将许多操作并行计算,减少时钟数;另一方面,wire变量由组合逻辑电路实现,如果wire变量的表达式足够精简,那么组合逻辑电路的复杂度也会降低,从而提高时序可靠性,降低lut数量和实现面积;本发明一次模乘计算只需要5个时钟,按照最大时钟频率106.2925mhz,吞吐量可达5442.176mbps,实现后模块的逻辑资源仅使用5694个lut,达到了在vivado平台下sm2模乘器的可靠、快速和低功耗的实现效果。
2、本发明提供一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,包括以下步骤:
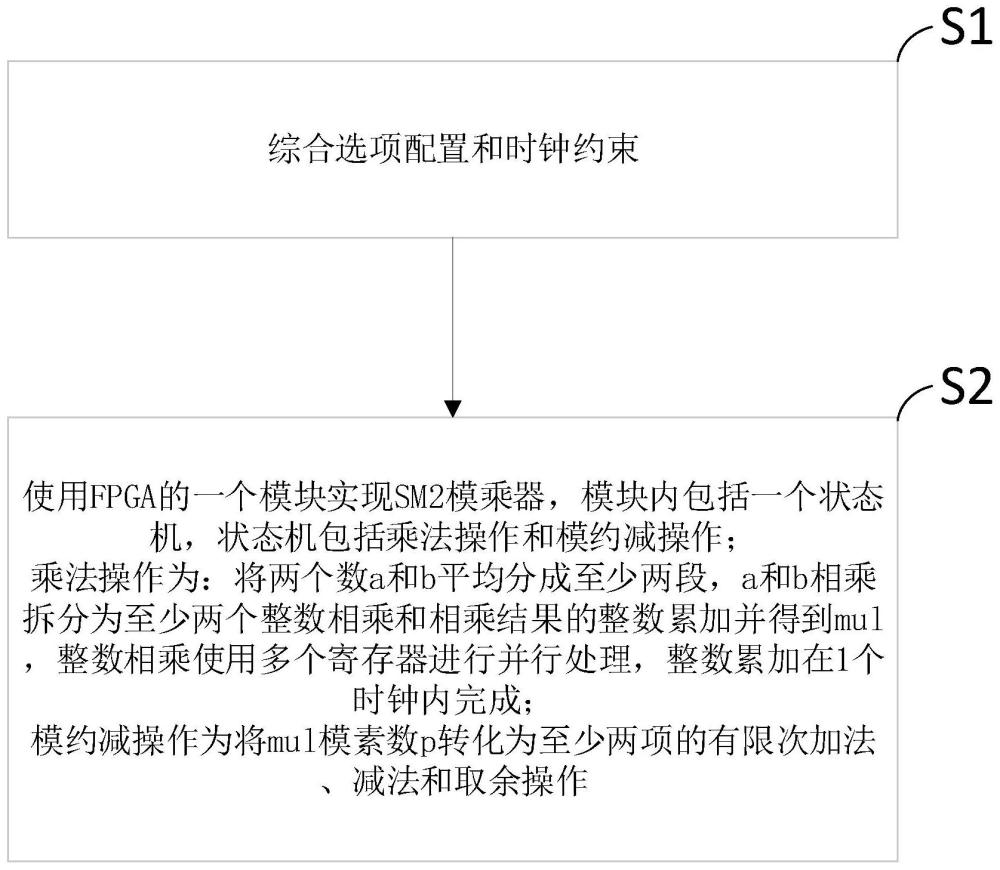
3、s1、综合选项配置和时钟约束;
4、s2、使用fpga的一个模块实现sm2模乘器,模块内包括一个状态机,状态机包括乘法操作和模约减操作;
5、乘法操作为:将两个数a和b平均分成至少两段,a和b相乘拆分为至少两个整数相乘和相乘结果的整数累加并得到mul,整数相乘使用多个寄存器进行并行处理,整数累加在1个时钟内完成;
6、模约减操作为将mul模素数p转化为至少两项的有限次加法、减法和取余操作。
7、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,步骤s1中,使用vivado作为软件平台,综合选项配置过程为:在综合设置选项卡中设置为ooc综合方式,时钟约束为:设置一个时钟周期的大小为10纳秒。
8、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,步骤s2中,乘法操作为2个时钟,其中整数相乘为1个时钟,整数累加为1个时钟;
9、模约减操作为3个时钟,加法操作和减法操作为2个时钟,取余操作为1个时钟。
10、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,步骤s2中,a和b均为256比特,将a和b分别平均分成4段、每段64比特;
11、a=2192*a+2128*b+264*c+d;
12、b=2192*e+2128*f+264*g+h;
13、a*b=2384*(a*e)+2320*(a*f+b*e)+2256*(a*g+c*e+b*f)+2192*(a*h+e*d+b*g+c*f)+2128*(b*h+d*f+c*g)+264*(c*h+d*g)+d*h。
14、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,设置1个512比特寄存器mul和7个130比特寄存器gi,0≤i≤6,在第一个时钟内并行计算:
15、g0=a*e;
16、g1=a*f+b*e;
17、g2=a*g+c*e+b*f;
18、g3=a*h+e*d+b*g+c*f;
19、g4=b*h+d*f+c*g;
20、g5=c*h+d*g;
21、g6=d*h;
22、在第二个时钟内,计算mul=2384*g0+2320*g1+2256*g2+2192*g3+2128*g4+264*g5+g6,得到a*b的值。
23、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,步骤s2中,将mul模p的计算转化为对若干个数值不超过3*2256的项进行的有限次加法和减法操作,定义wire变量,使模约减过程用3个时钟来完成。
24、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,模约减操作为:先在第一个时钟并行地计算t1和t2,然后在第二个时钟计算f=t1+e1+e2-{t2,64'd0},最后一个时钟计算f mod p,其中,t1和t2为加法操作,fmodp为取余操作;
25、f=(e1+e2+e3+e4+e5+e6+2*(e7+e8
26、+e9+e10)-e11-e12-e13-e14),
27、t1=e3+e4+e5+e6+2*(e7+e8+e9+e10),
28、t2=d8+d9+d13+d14。
29、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,
30、mul=d15*2480+d14*2448+d13*2416+d12*2384+d11*2352+d10*2320+…+d2*264+d1*232+d0;
31、d15~d0均为32比特;
32、mul mod p=(e1+e2+e3+e4+e5+e6+2*(e7+e8+e9+e10)-e11-e12-e13-e14)mod p;
33、其中,wire变量为:e1={d7,d6,d5,d4,d3,d2,d1,d0};
34、e2={d8,d11,d10,d9,d8,32'd0,d9,d8};
35、e3={d9,d14,d13,d12,d11,32'd0,d10,d9};
36、e4={d10,d15,d14,d13,d12,32'd0,d11,d10};
37、e5={d11,32'd0,32'd0,d15,d14,32'd0,d12,d11};
38、e6={d15,32'd0,32'd0,32'd0,d15,32'd0,d13,d12};
39、e7={d12,32'd0,32'd0,32'd0,32'd0,32'd0,32'd0,32'd0};
40、e8={d13,32'd0,32'd0,32'd0,d13,32'd0,32'd0,d13};
41、e9={d14,32'd0,32'd0,d14,32'd0,32'd0,d14,d14};
42、e10={d15,32'd0,d15,32'd0,32'd0,32'd0,d15,d15};
43、e11={32'd0,32'd0,32'd0,32'd0,32'd0,d8,32'd0,32'd0};
44、e12={32'd0,32'd0,32'd0,32'd0,32'd0,d9,32'd0,32'd0};
45、e13={32'd0,32'd0,32'd0,32'd0,32'd0,d13,32'd0,32'd0};
46、e14={32'd0,32'd0,32'd0,32'd0,32'd0,d14,32'd0,32'd0};
47、在sm2素数域上采用256比特模数p,p=2256-2224-296+264-1;
48、根据同余规则,
49、
50、本发明所述的一种基于vivado平台的sm2椭圆曲线素数域模乘器的fpga实现方法,作为优选方式,
51、最后一个时钟计算f mod p的方法为:
52、mul mod p=f mod p=(g1+g2-g3)mod p;
53、如果r2借位比特为1,即r2<0,那么mul mod p=r1,否则mul mod p=r2;
54、其中,r1=g1+g2-g3,r2=g1+g2-g3-p;
55、f={f8,f7,f6,f5,f4,f3,f2,f1,f0};
56、g1={f7,f6,f5,f4,f3,f2,f1,f0},
57、g2={f8,32'd0,32'd0,32'd0,f8,32'd0,32'd0,f8},
58、g3={32'd0,32'd0,32'd0,32'd0,32'd0,f8,32'd0,32'd0}。
59、本发明具有以下优点:
60、(1)可靠性高。本方法尽可能将操作进行简化,避免使用过多的组合逻辑,减少不必要中间操作。按照上述步骤,对最终的verilog代码进行综合与实现,实现后的最大时钟频率为106.2925mhz,满足了大多数工程应用的需求,保证了时序可靠性。
61、(2)功耗低。通过对代码进行综合与实现,实现后模块的资源占用情况是,使用了5694个lut和2276个ff。与现有技术使用了6701个lut相比,本方法少用了1000多个lut。
62、(3)吞吐量大。本方法对模乘的计算采用了单独模块来完成,和使用多个模块的实现方式相比,减少了模块交互额外占用的时钟。并将可以同时计算且互不影响的部分尽量放在一个时钟,将并行尽可能最大化。一次模乘计算需要5个时钟,和现有技术相比,少用了2个时钟。按照最大时钟频率106.2925mhz,吞吐量可达5442.176mbps。
- 还没有人留言评论。精彩留言会获得点赞!