任务处理方法、装置、计算机设备及存储介质与流程
本技术涉及大数据与金融科技领域,尤其涉及任务处理方法、装置、计算机设备及存储介质。
背景技术:
1、随着大数据领域的不断发展,数据湖技术在大数据领域的发展逐渐兴起,使得数据湖技术在金融科技企业,例如保险企业、银行中的应用越来越广泛。目前,数据湖的组件技术也在不断迭代,从apache hive逐渐发展至今日的apache hudi、apache iceberg等,用户对数据的要求也在不断变高,业务数据的时效从原来的t+1的要求逐步提高到实时或者准实时,这给保存基础数据的数据湖来说带来了更大的挑战,即同步源端数据的时效要求接近实时。
2、在数据湖朝着数据实时化的方向发展演进的过程中,数据湖文件的并发写入冲突成为业界普遍存在的问题,其问题背景如下:数据湖以实时技术从数据源端同步一份数据表的数据,其实时同步进程以短作业任务的方式不断向该数据表写入最新的数据,而不断生成的短作业任务会以“时间短,频次高”的特点来申请并占用该数据表的写入锁,导致其他写入该数据表的任务无法申请获得写入锁,从而无法达到多任务并发写入同一数据表的目的,因而造成数据湖文件出现并发写入冲突的问题。存在的数据湖文件的并发写入冲突的问题会引起数据延迟或数据不一致,进而给生产带来不良影响。
技术实现思路
1、本技术实施例的目的在于提出一种任务处理方法、装置、计算机设备及存储介质,以解决现有存在的数据湖文件的并发写入冲突的问题,并且会引起数据延迟或数据不一致,进而给生产带来不良影响的技术问题。
2、为了解决上述技术问题,本技术实施例提供一种任务处理方法,采用了如下所述的技术方案:
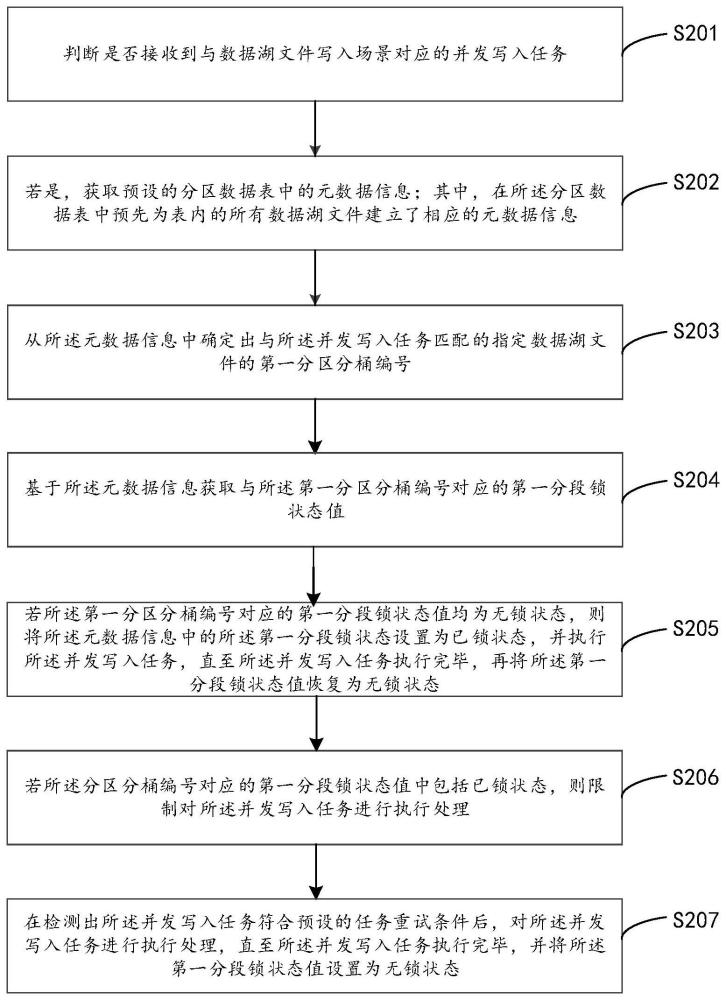
3、判断是否接收到与数据湖文件写入场景对应的并发写入任务;
4、若是,获取预设的分区数据表中的元数据信息;其中,在所述分区数据表中预先为表内的所有数据湖文件建立了相应的元数据信息;
5、从所述元数据信息中确定出与所述并发写入任务匹配的指定数据湖文件的第一分区分桶编号;
6、基于所述元数据信息获取与所述第一分区分桶编号对应的第一分段锁状态值;
7、若所述第一分区分桶编号对应的第一分段锁状态值均为无锁状态,则将所述元数据信息中的所述第一分段锁状态设置为已锁状态,并执行所述并发写入任务,直至所述并发写入任务执行完毕,再将所述第一分段锁状态值恢复为无锁状态;
8、若所述分区分桶编号对应的第一分段锁状态值中包括已锁状态,则限制对所述并发写入任务进行执行处理;
9、在检测出所述并发写入任务符合预设的任务重试条件后,对所述并发写入任务进行执行处理,直至所述并发写入任务执行完毕,并将所述第一分段锁状态值设置为无锁状态。
10、进一步的,所述从所述元数据信息中确定出与所述并发写入任务匹配的指定数据湖文件的第一分区分桶编号的步骤,具体包括:
11、对所述并发写入任务进行信息解析,得到对应的解析信息;
12、从所述解析信息中提取出所述并发写入任务中的文件分区描述信息;
13、从所述元数据信息中筛选出与所述文件分区描述信息匹配的指定分区分桶编号;
14、将所述指定分区分桶编号作为所述指定数据湖文件的第一分区分桶编号。
15、进一步的,在所述获取预设的分区数据表中的元数据信息的步骤之前,还包括:
16、对所有所述数据湖文件构建分区数据表;
17、在所述分区数据表中对所有所述数据湖文件的文件存储路径进行初始化处理;
18、基于预设的分段锁的映射机制与所述文件存储路径对所述分区数据表进行数据初始化处理,以对所述分区数据表中的所有所述数据湖文件构建对应的元数据信息。
19、进一步的,所述基于预设的分段锁的映射机制与所述文件存储路径对所述分区数据表进行数据初始化处理,以对所述分区数据表中的所有所述数据湖文件构建对应的元数据信息的步骤,具体包括:
20、基于所述文件存储路径确定出各所述数据湖文件在所述分区数据表中的第二分区分桶编号;
21、构建与所有所述数据湖文件对应的数据初始化写入任务;
22、执行所述数据初始化写入任务,将所有所述数据湖文件对应的所述第二分区分桶编号添加至预设的分段锁映射表内;
23、在所述分段锁映射表中将各所述第二分区分桶编号对应的第二分段锁状态值设置为无锁状态,得到修改后的分段锁映射表;
24、将所述修改后的分段锁映射表存储至预设的初始元数据文件内,得到所述元数据信息。
25、进一步的,在所述在检测出所述并发写入任务符合预设的任务重试条件后,对所述并发写入任务进行执行处理,直至所述并发写入任务执行完毕,并将所述第一分段锁状态值设置为无锁状态的步骤之前,还包括:
26、实时获取所述元数据信息中与所述指定数据湖文件的第一分区分桶编号匹配的第三分段锁状态值;
27、判断所述第三分段锁状态值是否均为无锁状态;
28、若是,判定所述并发写入任务符合所述任务重试条件,否则判定所述并发写入任务不符合所述任务重试条件。
29、进一步的,所述获取预设的分区数据表中的元数据信息的步骤,具体包括:
30、调用预设的任务校验规则;
31、基于所述任务校验规则对所述并发写入任务进行校验;
32、若所述并发写入任务通过校验,则执行所述获取预设的分区数据表中的元数据信息的步骤。
33、进一步的,在所述若所述第一分区分桶编号对应的第一分段锁状态值均为无锁状态,则将所述元数据信息中的所述第一分段锁状态设置为已锁状态,并执行所述并发写入任务,直至所述并发写入任务执行完毕,再将所述第一分段锁状态值恢复为无锁状态的步骤之后,还包括:
34、调用预设的无锁算法;
35、获取所述分区数据表的当前版本信息;
36、基于所述无锁算法与所述当前版本信息对所述分区数据表进行版本更新处理。
37、为了解决上述技术问题,本技术实施例还提供一种任务处理装置,采用了如下所述的技术方案:
38、第一判断模块,用于判断是否接收到与数据湖文件写入场景对应的并发写入任务;
39、第一获取模块,用于若是,获取预设的分区数据表中的元数据信息;其中,在所述分区数据表中预先为表内的所有数据湖文件建立了相应的元数据信息;
40、确定模块,用于从所述元数据信息中确定出与所述并发写入任务匹配的指定数据湖文件的第一分区分桶编号;
41、第二获取模块,用于基于所述元数据信息获取与所述第一分区分桶编号对应的第一分段锁状态值;
42、第一处理模块,用于若所述第一分区分桶编号对应的第一分段锁状态值均为无锁状态,则将所述元数据信息中的所述第一分段锁状态设置为已锁状态,并执行所述并发写入任务,直至所述并发写入任务执行完毕,再将所述第一分段锁状态值恢复为无锁状态;
43、第二处理模块,用于若所述分区分桶编号对应的第一分段锁状态值中包括已锁状态,则限制对所述并发写入任务进行执行处理;
44、第三处理模块,用于在检测出所述并发写入任务符合预设的任务重试条件后,对所述并发写入任务进行执行处理,直至所述并发写入任务执行完毕,并将所述第一分段锁状态值设置为无锁状态。
45、为了解决上述技术问题,本技术实施例还提供一种计算机设备,其中,计算机设备包括存储器和处理器,存储器中存储有计算机可读指令,处理器执行计算机可读指令时实现如上述的任务处理方法的步骤。
46、为了解决上述技术问题,本技术实施例还提供一种计算机可读存储介质,计算机可读存储介质上存储有计算机可读指令,计算机可读指令被处理器执行时实现如上述的任务处理方法的步骤。
47、与现有技术相比,本技术实施例主要有以下有益效果:
48、首先判断是否接收到与数据湖文件写入场景对应的并发写入任务;若是,获取预设的分区数据表中的元数据信息;然后从所述元数据信息中确定出与所述并发写入任务匹配的指定数据湖文件的第一分区分桶编号;后续基于所述元数据信息获取与所述第一分区分桶编号对应的第一分段锁状态值;若所述第一分区分桶编号对应的第一分段锁状态值均为无锁状态,则将所述元数据信息中的所述第一分段锁状态设置为已锁状态,并执行所述并发写入任务,直至所述并发写入任务执行完毕,再将所述第一分段锁状态值恢复为无锁状态;而若所述分区分桶编号对应的第一分段锁状态值中包括已锁状态,则限制对所述并发写入任务进行执行处理;最后在检测出所述并发写入任务符合预设的任务重试条件后,对所述并发写入任务进行执行处理,直至所述并发写入任务执行完毕,并将所述第一分段锁状态值设置为无锁状态。本技术通过基于预先构建的分区数据表中的元数据信息的使用来优化与数据湖文件写入场景对应的并发写入任务的处理过程,通过从所述元数据信息中确定出与所述并发写入任务匹配的指定数据湖文件的第一分区分桶编号,并从所述元数据信息获取与所述第一分区分桶编号对应的第一分段锁状态值,进而对第一分段锁状态值进行内容分析,以根据得到的分析结果来进行对于并发写入任务的准确的相应处理,基于元数据信息中的分段锁状态的分析实现了快速准确地完成对于与分区数据表中的数据湖文件对应的并发写入任务的处理,有效地避免了分区数据表中的数据湖文件出现并发写入冲突的问题,有利于极大降低数据湖文件在并发写入场景下的冲突概率,以及极大降低因数据湖文件的并发写入冲突引起的数据延迟或数据不一致给生产带来的不良影响。
- 还没有人留言评论。精彩留言会获得点赞!