一种基于框架语义场景图的零形式填充方法
本发明涉及自然语言处理领域,更具体地说,涉及一种基于框架语义场景图的零形式填充方法。
背景技术:
1、汉语框架网(chinese framenet,cfn)是以fillmore的框架语义学为理论基础,以汉语真实语料为依据,参照伯克利大学的框架语义网(framenet,fn)构建的汉语框架语义知识库,包括框架库、句子库和词元库。汉语框架语义分析是基于汉语框架语义知识库提出的任务,零形式填充(null instantiation filling,以下简称nif)是汉语框架语义分析的子任务之一,它旨在将句子中目标词所触发的特定框架下的隐式语义角色与其在篇章上下文中的填充内容(若存在)联系在一起。nif有助于机器对篇章的正确理解,对多跳阅读理解、篇章级语义分析等任务具有重要意义。
2、传统的框架语义角色标注是基于句子级的,只能为句子中显式表达的语义论元分配语义角色,而忽略了一些隐含在篇章上下文中未显式表达的语义论元,这些未显式表达的语义论元对应的核心框架元素被称为零形式框架元素,简称为零形式(nullinstantiation,ni)。按照缺失的核心框架元素在语义理解上的不同解释类型,零形式被分为无定的零形式(indefinite null instantiation,ini)和有定的零形式(definite nullinstantiation,dni)。ini指缺失的核心框架元素不影响人们对语篇的正确理解,且在上下文中没有特定的填充内容。dni是指句子范围内缺失的核心框架元素在上下文中能够明确找到对应的填充内容。
3、nif是已知零形式框架元素所属框架以及该框架在句子中的显式框架元素及其填充内容,为有定的零形式框架元素在上下文中找到相应的填充内容。零形式填充任务的形式化表示如下所示:
4、
5、其中,ni指的是目标词触发的框架中所有核心框架元素集合e减去句子中显式核心框架元素集合eh剩下的部分,ex是句子中所有显式框架元素集合,ec是显式框架元素填充内容集合,c为零形式框架元素ni的候选填充项集合,简称为候选语集合。若某个零形式框架元素在上下文中找不到填充内容,则认为该零形式框架元素为ini。
6、国际语言学会议acl在2010年举办了关于“linking event and theirparticipants in discourse”的语义评测,该任务要求参赛者在已标注语义角色的语料上识别出有定的零形式并在上下文中为其找到相应的填充内容,使得零形式填充任务受到了广泛关注。现有的零形式填充方法主要分为基于规则与统计的方法以及基于词嵌入模型的机器学习方法。
7、早期对于零形式填充的研究结合规则与统计的方法,借助外部系统工具进行零形式填充实验。tonelli等人借助文本蕴涵识别系统venses得到每个词元不同的标注模式,在训练语料中查找与其相似的谓词论元结构,找到后与其对比得出缺失的论元,最后通过计算缺失框架元素与候选语的相似度寻找其填充内容。chen等人融入统计方法,扩展了semafor1.0工具,利用语义角色与候选语的相关性与相似性得分完成零形式填充任务,但其性能仍然较低。
8、随着机器学习的发展,gerber等人在nombank语料库中,使用实体指代方法,结合句法、语义特征,完成零形式填充任务。silberer等人将该问题看作一个指代消解任务,将实体链作为候选填充项,结合语义角色标注和共指消解的特征,构建了有监督的机器学习模型。wang等人在传统的零形式填充特征上引入中心词信息和框架信息。laparra等人总结研究了传统指代消解所使用的特征,并尝试着将其应用到零形式的填充任务中。wu等人首先利用规则与过滤的方法进行零形式识别,再选取相关的语义特征,建立最大熵分类模型,实现了零形式的分类和填充。li等人提出了基于svm的零形式分类并结合框架关系与框架语义特征,提升了零形式填充任务的效果。zhang等人从数据非平衡的角度出发,对非平衡数据进行平衡化处理,融入语义相似性特征及框架元素间的映射关系,提升零形式填充效果。但是,上述通过构造分类特征对零形式框架元素进行填充的方法,需要人工构造分类特征,效率低下且性能较低。
9、现有的零形式填充方法采用pipeline模型,先对零形式类型分类,之后通过手动设计与dni框架元素候选语关联的信息作为特征,学习候选语的表示。这些方法存在以下不足:1)零形式分类的结果会影响零形式填充的效果,造成错误传播。2)在学习候选语表示时没有考虑到显式框架元素及其填充内容的信息以及他们之间的框架语义关系。
技术实现思路
1、针对上述问题,本发明针对上述问题提供了一种基于框架语义场景图的零形式填充方法,研究融合框架语义场景图的零形式填充方法,为篇章级框架语义分析、多跳阅读理解等任务提供技术支撑。
2、为达到上述目的本发明采用了以下技术方案:
3、步骤1,获取文本并进行数据标注,进行数据预处理,将纯文本处理为json格式的数据;
4、步骤2,构建基于框架语义场景图的零形式填充模型,包括:
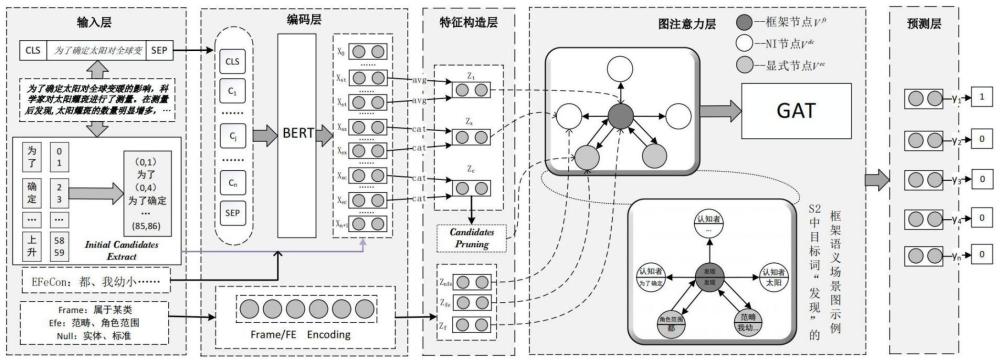
5、1)输入层:获取零形式填充模型所需的输入文本、框架语义信息以及零形式框架元素的候选语集合;
6、2)编码层:利用bert对上下文序列编码,并对每个框架和框架元素进行唯一编码;
7、3)特征构造层:在编码层输出的基础上得到目标词、显式框架元素及其填充内容、候选语三者的上下文表示;设计候选语剪枝得分函数,选取前top-k个作为候选语集合;
8、4)图注意力层:根据框架语义信息构造框架语义场景图,并使用gat对框架语义场景图建模;
9、5)预测层:将gat学习到的候选语表示通过分类器分类,为有定的零形框架元素找到它的填充内容。
10、进一步地,步骤1中文本从阅读理解、报纸中获取,数据标注使用cfn人机协同标注系统。
11、进一步地,输入层具体为:输入文本为原始的文本数据,框架语义信息包括目标词所属框架名称、显式框架元素名称以及零形式框架元素名称;
12、采用基于词汇级跨度的方法选取零形式框架元素的候选语集合,即以词为基本单位枚举出句子中所有的跨度c={c1,c2,……,cn},在枚举出的跨度集合中,删除目标词所在跨度以及已经是显式框架元素填充内容的跨度不可能是零形式框架元素的填充内容,同时还把候选语长度限制在max_length以内,最后得到零形式框架元素候选语集合为c={c1,c2,……,cm,φ}。
13、进一步地,编码层具体为:利用bert来进行上下文编码,将[cls]+{e1,...,ei,...,en}+[sep]作为bert模型输入,编码层将输入中的每一个字符编码成字符嵌入etoken(ti),分段嵌入eseg(ti)和位置嵌入epos(ti)三个向量,将三个向量相加输入bert预训练模型得到输出向量x,如下式所示:
14、ei=etoken(ti)+eseg(ti)+epos(ti)
15、x=bert(e0,...,ei,...,en+1)
16、对目标词所属框架、显式框架元素以及零形式框架元素进行唯一编码,如下式所示:
17、zf=embedding(fid)
18、zfe=embedding(feid)
19、
20、其中fid表示目标词所属框架f的id,feid表示某个显示框架元素fe的id,fnfeid表示某个零形式框架元素fnfe的id。
21、进一步地,特征构造层具体为:将目标词开始位置信息和结束位置信息分别记为xst和xet;显式框架元素填充内容的开始位置信息、结束位置信息和长度分别记为xsx,xex和widthx;零形式框架元素候选语的开始位置信息、结束位置信息以及长度信息分别记为xsc、xec和widthc;则目标词的上下文表示、显式框架元素填充内容的上下文表示和零形式框架元素候选语集合中某个候选语的上下文表示分别为zt、zx和zc:
22、
23、zx=cat[xsx;xex;widthx]
24、zc=cat[xsc;xec;widthc]
25、其中cat表示拼接函数;
26、并设置候选语剪枝得分函数,选取前top-k个跨度构成候选语集合,如下式所示:
27、
28、
29、
30、其中,fc、ft均为前馈神经网络,w、wc、wt为可学习的参数,φ(zt,zc)为某个候选语与目标词的距离特征。
31、进一步地,图注意力层具体为:采用框架语义场景图g=(v,e)来融合显式框架元素及其填充内容和框架语义信息;
32、框架语义场景图g共有三种类型的节点:框架节点、显式节点和候选语节点,其中框架节点表示融合框架与目标词信息的节点,显式节点表示融合显式框架元素及其填充内容信息的节点,候选语节点表示融合有定的零形式框架元素以及该框架元素的候选语信息的节点;
33、连接三种不同类型的节点形成三种不同类型的边:第一种为框架节点到显式节点的边,第二种为显式节点到框架节点的边,第三种为框架节点到候选语节点的边;
34、使用gat来更新框架语义场景图的节点信息,得到聚合显式框架元素及其填充内容信息、目标词与框架信息、零形式框架元素信息的候选语表示,如下所示:
35、rg=gat(z,a)
36、其中,a表示图的邻接矩阵,a∈{0,1}表示节点vi到节点vj之间是否存在有向边,z表示节点的初始特征矩阵,框架节点初始编码由框架编码与目标词编码拼接而成,显式节点初始编码由显式框架元素编码与显式框架元素填充内容编码拼接而成,候选语节点初始编码由零形式框架元素编码与候选语编码zc拼接而成。
37、进一步地,预测层具体为:将图编码层获取的候选语表示rg(ci)进行线性变换和非线性激活,得到该候选语作为零形式框架元素填充内容的概率pi,如下所示:
38、pi=sigmoid(l(rg(ci)))
39、其中l代表线性变换层,取概率最大的位置作为当前预测的结果类别;
40、并采用二分类交叉熵损失作为分类损失,如下所示:
41、
42、其中preal表示真实样本类别分布,pi表示模型预测出的样本类别分布。
43、基于上述描述内容,本技术方案主要解决三个方面的技术难点:
44、第一,本发明提出了一种端到端的模型结构,有效减少了零形式填充的错误传播;第二,构建出框架语义场景图并利用图注意力网络对该框架语义场景图建模,得到融合了句子中显式框架元素及其填充内容以及框架语义信息的候选语表示;第三,根据目标词与候选语的语义相关性提出了一种候选语剪枝方法。
45、与现有技术相比,本发明具有以下优点:
46、在零形式填充过程中充分考虑了显式框架元素及其填充内容的重要性,并提出了一种端到端的零形式填充方法,有效缓解了传统pipeline模型容易造成错误传播的问题。
- 还没有人留言评论。精彩留言会获得点赞!