面向离线强化学习的在线自适应方法、系统、装置及介质
本发明涉及离线强化学习策略部署领域,尤其涉及一种面向离线强化学习的在线自适应方法、系统、装置及介质。
背景技术:
1、在现实中,由于样本收集困难、或者交互模拟成本高等原因,让机器人(agent)实时地与环境进行交互并获取数据十分困难。因此,离线强化学习方法利用事先收集的离线数据进行策略学习,将训练好的策略部署到实际应用场景中。比如自动驾驶等安全要求较高场景问题,一般先离线收集一批数据去训练一个较好的自动驾驶策略,再将这个策略部署到在线环境中。
2、由于离线数据集和在线环境之间可能存在分布偏移,导致训练号的离线策略不能很好地适应在线环境。存在分布偏移的原因是离线数据集用其他未知行为策略收集的,并不能确保收集到的状态动作对(s,a)能覆盖状态-动作空间中的所有可能。在测试时,面对没见过的状态动作对(s,a),离线策略可能会给出不好的评估。
3、为了解决这个问题,现有的方法主要分为两类,保守估计和不确定性评估方法。保守估计方法核心思想是通过添加kl divergence约束或者策略值惩罚来使得训练好的策略偏向于选择数据集中存在的(s,a),从而避免策略对未见过的(s,a)过估计,主要有conservative q-learning(cql)、td3+bc和mildly conservative q-learning(mcql)等。不确定性评估方法的核心思想是通过某个具体指标来衡量(s,a)的不确定性,对评估的结果进行一个不确定量化,从而权衡未见过的(s,a)带来的风险和收益,主要有uncertaintyweighted actor critic(uwac)、ensemble-diversified actor critic(edac)等。
4、然而,不管时保守估计方法,还是不确定性估计方法,他们都只利用训练数据去调整模型策略变得保守或者对策略进行不确定惩罚,并没有直接利用测试状态数据s来进一步去微调离线策略。
技术实现思路
1、为至少一定程度上解决现有技术中存在的技术问题之一,本发明的目的在于提供一种面向离线强化学习的在线自适应方法、系统、装置及介质。
2、本发明所采用的技术方案是:
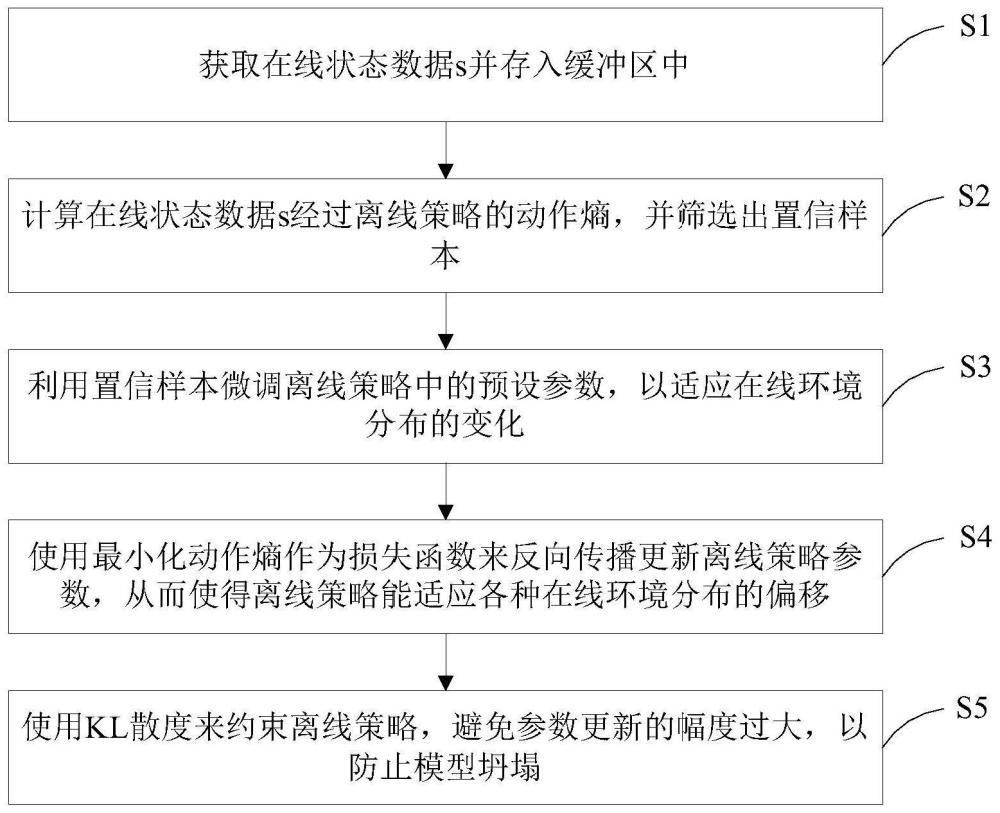
3、一种面向离线强化学习的在线自适应方法,包括以下步骤:
4、获取在线状态数据s(如rgb图片)并存入缓冲区(replay buffer)中;
5、计算在线状态数据s经过离线策略(如自动驾驶策略)的动作熵,并判断动作熵是否为置信样本;
6、利用置信样本微调离线策略中的预设参数,以适应在线环境分布的变化,比如layernorm层的参数;
7、使用最小化动作熵作为损失函数来反向传播更新离线策略参数,从而使得离线策略能适应各种在线环境分布的偏移;
8、使用kl散度来约束离线策略,避免参数更新的幅度过大,以防止模型坍塌。
9、进一步地,所述获取在线状态数据s并存入缓冲区中,包括:
10、机器人(agent)和在线环境进行交互,获取状态数据s,并将状态数据s存入一个缓冲区(replay buffer)中;
11、其中,对于自动驾驶场景和游戏场景来说,状态数据s为图片数据;对于sim-to-real以及离线能源策略迁移场景来说,状态数据s为向量数据。
12、进一步地,所述计算在线状态数据s经过离线策略的动作熵,并筛选出置信样本,包括:
13、计算在线状态数据s经过离线策略的动作熵;
14、对于离散控制任务,小于预设阈值的状态数据s为置信样本;对于连续控制任务,缓冲区中阈值topk小的样本为置信样本。
15、进一步地,对于离散控制任务,采用以下公式进行筛选状态数据s:
16、
17、式中,θ表示要微调的离线策略参数,是指示函数,条件满足时为1,反之则为0,e0=α*lna是置信样本筛选阈值,小于该阈值的样本为置信样本,大于该阈值的样本则丢弃;
18、对于连续控制任务,则采用以下公式进行筛选状态数据s:
19、
20、式中,e′0表示缓冲区中的熵值第k小的值,通过将缓冲区topk小的状态数据筛选出来更新离线策略。
21、进一步地,所述预设参数为layernorm层中的仿射参数或者最后一层参数。
22、进一步地,所述利用置信样本微调离线策略中的预设参数,包括:
23、对于离散控制任务,采用以下优化目标去微调离线策略:
24、
25、式中,a表示动作,a表示动作空间,πθ表示要微调的离线策略;
26、结合筛选的置信样本,形成以下优化目标:
27、
28、对于连续控制任务,采用以下优化目标去微调离线策略:
29、
30、式中,σ表示连续动作的方差;
31、结合筛选的置信样本,形成以下优化目标:
32、
33、通过最小化无监督优化目标,微调离线策略中的layernorm层中的仿射参数或者最后一层参数;无监督优化目标的表达式为:
34、
35、进一步地,所述使用kl散度来约束离线策略,包括:
36、添加一个参数冻住的策略πbase,让微调之后的策略πoff和πbase之间添加一个kl-divergence损失函数,如下公式所示:
37、
38、总的损失函数如下:
39、
40、式中,λ为权重。
41、本发明所采用的另一技术方案是:
42、一种面向离线强化学习的在线自适应系统,包括:
43、数据获取模块,用于获取在线状态数据s并存入缓冲区中;
44、熵值计算模块,用于计算在线状态数据s经过离线策略的动作熵,并筛选出置信样本;
45、参数微调模块,用于利用置信样本微调离线策略中的预设参数,以适应在线环境分布的变化;
46、参数更新模块,用于使用最小化动作熵作为损失函数来反向传播更新离线策略参数,从而使得离线策略能适应各种在线环境分布的偏移;
47、幅度限制模块,用于使用kl散度来约束离线策略,避免参数更新的幅度过大,以防止模型坍塌。
48、本发明所采用的另一技术方案是:
49、一种面向离线强化学习的在线自适应装置,包括:
50、至少一个处理器;
51、至少一个存储器,用于存储至少一个程序;
52、当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现如上所述方法。
53、本发明所采用的另一技术方案是:
54、一种计算机可读存储介质,其中存储有处理器可执行的程序,所述处理器可执行的程序在由处理器执行时用于执行如上所述方法。
55、本发明的有益效果是:本发明在测试阶段,利用置信状态数据s来进一步微调离线强化学习策略,以适应在线环境分布的变化。另外,使用kl散度来约束离线策略,避免参数更新幅度过大。
- 还没有人留言评论。精彩留言会获得点赞!