基于渐进自适应模态增强注意力网络的多模态人格特质分析方法
本发明属于深度学习,具体来说涉及一种基于渐进自适应模态增强注意力网络的多模态人格特质分析方法。
背景技术:
1、多模态人格特质分析(multimodal personality traits analysis)旨在利用多种模态序列数据的组合来推断出个体的人格特征。早期的人格特质分析大多是从文本数据分析的角度进行的,近年来音频数据和视频数据也被广泛用于人格特质分析。然而,使用单一模态并不能提供足够的信息来预测人格特征,因为突然中断或背景噪音等环境因素会影响一些模态,如文本、音频等模态数据的缺失。此外,人格特质的外在表现也具有多模态的特点;例如,一个人的行为、言语、情绪表达、身体姿态甚至是外貌都能反映出一个人的人格特质。
2、多模态人格特质分析一般包含两个关键的步骤:特征提取、多模态信息融合。特征提取是指从原始数据中提取出具有辨别能力和人格表达相关的特征。多模态信息融合是指将来自不同模态(如图像、文本、音频等)的信息进行融合,以提取更丰富、更全面的特征用于后续的多模态的人格分析任务。在多模态信息融合中,通过对来自不同模态的数据进行联合处理和分析,能够获得比单个模态更好的多模态人格分析性能。
3、特征提取是多模态人格特质分析的一个关键步骤。近年来,各种基于深度学习的预训练模型被广泛用于多模态人格分析的特征提取任务:例如,面向视觉方面的vgg_face模型通过多个卷积层和池化层提取人脸图像的特征;面向文本信息处理的bert模型是一种基于transformer的预训练模型,能够提取文本中丰富的语义和上下文信息;面向音频信号处理的wav2vec模型是一种基于wavenet和卷积神经网络的语音识别模型,能够从原始音频信号中提取语音信号相关的高层次音频特征。
4、在获得不同模态的特征数据之后,如何有效地进行多模态信息融合是多模态人格分析中的另一个关键步骤。早期的多模态信息融合工作主要集中在将视频片段中提取的多模态特征进行特征级联(称为特征层融合)或根据不同模态的预测结果进行决策融合(称为决策层融合),但这些工作都没有考虑不同模态序列数据之间的内在关系。为了更好地实现多模态信息融合用于人格特质分析,非常有必要考虑不同模态序列数据之间的内在依赖性。然而,由于不同模态序列数据采样率的不同,实际采集的多模态数据流通常是异步的。针对此问题,早期工作采用人工对齐的方法(见文献:p.p.liang,z.liu,a.bagher zadeh,and l.-p.morency,“multimodal language analysis with recurrent multistagefusion,”emnlp.2018,pp.150-161),即在单词级别(word-level)上分别将文本单词与视觉和音频序列进行手工对齐,然后进行多模态信息融合。然而,这种人工对齐的过程需要大量的人力资源。此外,单词级别的融合忽略了来自不同模态序列数据之间的上下文依赖关系。
5、近年来,随着深度学习模型的发展,多模态transformer(见文献:yao-hunghubert tsai,shaojie bai,paul pu liang,j.zico kolter,louis-philippe morency,and ruslan salakhutdinov.“multimodal transformer for unaligned multimodallanguage sequences,”acl,pp.6558-6569,2019)为解决人工对齐的问题提供了可能的解决方案。该多模态transformer能够很好地处理异步的多模态序列数据,并能够建模多模态数据之间的长期依赖关系。然而,其是通过学习源模态和目标模态之间的定向成对注意力,反复地用源模态的数据来增强目标模态,此时的源模态并没有得到及时的更新;此外,对模态之间的融合与增强,也只是出现在固定方向的模态对之间,而不是涉及到的所有相关模态。针对该方法的不足之处,近年来新提出的渐进式模态增强(progressive modalityreinforcement,pmr)(见文献:f.lv,x.chen,y.huang,l.duan,g.lin,“progressivemodality reinforcement for human multimodal emotion recognition fromunaligned multimodal sequences,”cvpr,2021,pp.2554-2562)引入了一个消息中心(message hub)来增强和更新源模态,但是消息中心直接将所有模态级联在一起的方式,会导致每个源模态特定表示信息的丢失,使得该方法取得的性能比较有限。
技术实现思路
1、本发明的目的之一在于提供一种基于渐进自适应模态增强注意力网络的多模态人格特质分析方法,以解决背景技术中提出现有的多模态融合增强方法无法充分学习出不同模态序列数据之间的内在依赖性的问题。
2、为实现上述目的,本发明提供技术方案如下:
3、一种基于渐进自适应模态增强注意力网络的多模态人格特质分析方法,包括:
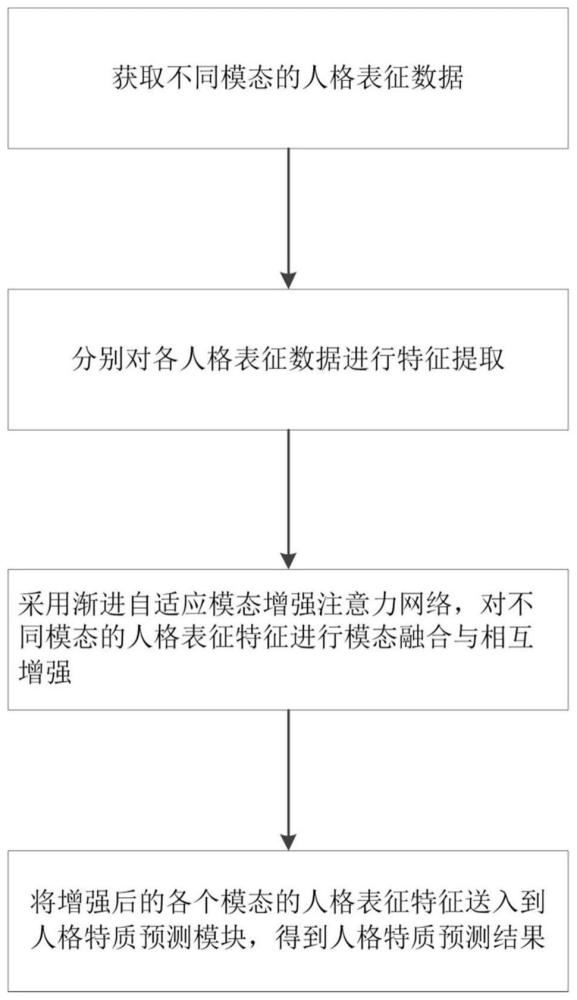
4、步骤1:获取不同模态的人格表征数据;
5、步骤2:分别对各人格表征数据进行特征提取;
6、步骤3:采用渐进自适应模态增强注意力网络,对不同模态的人格表征特征进行模态融合与相互增强;
7、步骤4:将增强后的各个模态的人格表征特征送入到人格特质预测模块,得到人格特质预测结果。
8、优选地,所述渐进自适应模态增强注意力网络包括多个依次连接的模态增强注意力层;任一模态增强注意力层中配合任一目标模态的人格表征特征zt,t∈[1,n]设置n-1个并行的自适应模态增强单元,用于使用n-1个源模态的人格表征特征zs,s={1,2,...,n}且s≠t分别进行特征增强,将n-1个增强结果级联后通过一全连接层降维,n表示人格表征特征的数量。
9、优选地,所述自适应模态增强单元中,对目标模态的人格表征特征使用自注意力机制进行特征增强,对源模态的人格表征特征使用跨模态注意力机制进行特征增强,并使用自适应融合机制进行增强特征的融合,对融合后的特征通过一个具有残差连接的位置级前馈层进行处理。
10、优选地,所述人格表征数据包括场景图像、人脸图像、音频以及音频对应的转录文本。
11、优选地,所述步骤1包括以下步骤:
12、步骤1.1,从多模态人格特质分析视频中提取连续的视频帧和相应的音频文件;
13、步骤1.2;选取视频的第一帧场景图像作为场景图像,并从第一帧场景图像中进行人脸检测,从而裁剪出包含人脸区域的图像作为人脸图像;
14、步骤1.3,根据音频文件,将其内容描述转录为文本。
15、优选地,所述步骤2包括:
16、步骤2.1,为不同模态的人格表征数据选择对应的深度学习模型进行特征提取,获得原始场景特征、人脸特征、语音特征及文本特征;
17、步骤2.2,将原始场景特征、人脸特征以及语音特征和文本特征的级联结果分别作为一人格表征特征;
18、步骤2.3,使用一维卷积神经网络将不同模态的人格表征特征映射到相同维度,并使用位置编码添加位置信息。
19、优选地,人格特质预测模块中,通过级联层将各增强后的人格表征特征级联,将级联结果输入至残差块,并将其输出结果通过多个全连接层处理得到人格预测结果;
20、该残差块中一个分支保留级联结果,另一分支为多层感知机。
21、与现有技术相比,本发明的有益效果为:
22、本发明方法提出的渐进自适应模态增强注意力网络(pamr)方法采用了一种渐进式增强的策略,能够实现不同模态之间的多层次信息交换,在增强目标模态的同时也能够增强源模态;自适应模态增强单元(amru)能够自适应地调整自我注意力和跨模态注意力的权重,以捕获不同层次水平的跨模态序列数据之间的人格特质相关性。
- 还没有人留言评论。精彩留言会获得点赞!