一种知识融合方法、装置、电子设备及存储介质与流程
本技术涉及知识图谱,尤其是涉及一种知识融合方法、装置、电子设备及存储介质。
背景技术:
1、知识融合技术是在知识图谱构建和应用中的一项关键技术。在现代信息时代,知识来源广泛且结构各异,包括结构化数据库、半结构化文本、非结构化文本等多种形式。然而,这些知识源之间存在着差异和异构性,导致知识的分布和不一致性。构建完善而准确的知识图谱需要不断收集来自不同知识源并且对知识图谱中的存储信息进行更新和补充。因此,知识融合算法在图谱更新阶段至关重要,直接影响到知识图谱的内容质量和存储效率。
2、现有的知识融合方法往往基于简单的逻辑规则、统计方法或传统的机器学习技术进行。然而,现有的融合方法在处理大规模、异构和高度动态的知识时往往表现不佳,无法有效地将不同来源的知识进行集成,导致融合结果的准确性和完整性受到限制。其次,由于知识和数据的来源多样性,不同来源之间可能存在冲突和不一致性;而现有的融合方法无法很好地解决复杂的冲突和不一致性情况,导致融合结果的可靠性受到威胁。最后,现有的融合方法通常是基于静态的规则和模型进行,但静态方法缺乏自适应和可扩展性。随着知识和数据的不断增长和变化,计算和存储需求会变得非常庞大,难以适应新的情况和挑战,导致效率低下。
技术实现思路
1、有鉴于此,本技术的目的在于提供一种知识融合方法、装置、电子设备及存储介质,首先基于相似度匹配粗筛得到潜在匹配序列对,进一步结合词向量建模技术并使用双塔神经网络模型精筛确定重复的实体结构数据,进而融合得到更新知识图谱。这样,通过结合前沿双塔神经网络和传统的自然语言技术,能够更准确地匹配实体结构数据,从而实现知识的准确高效融合,更新得到更准确的知识图谱。
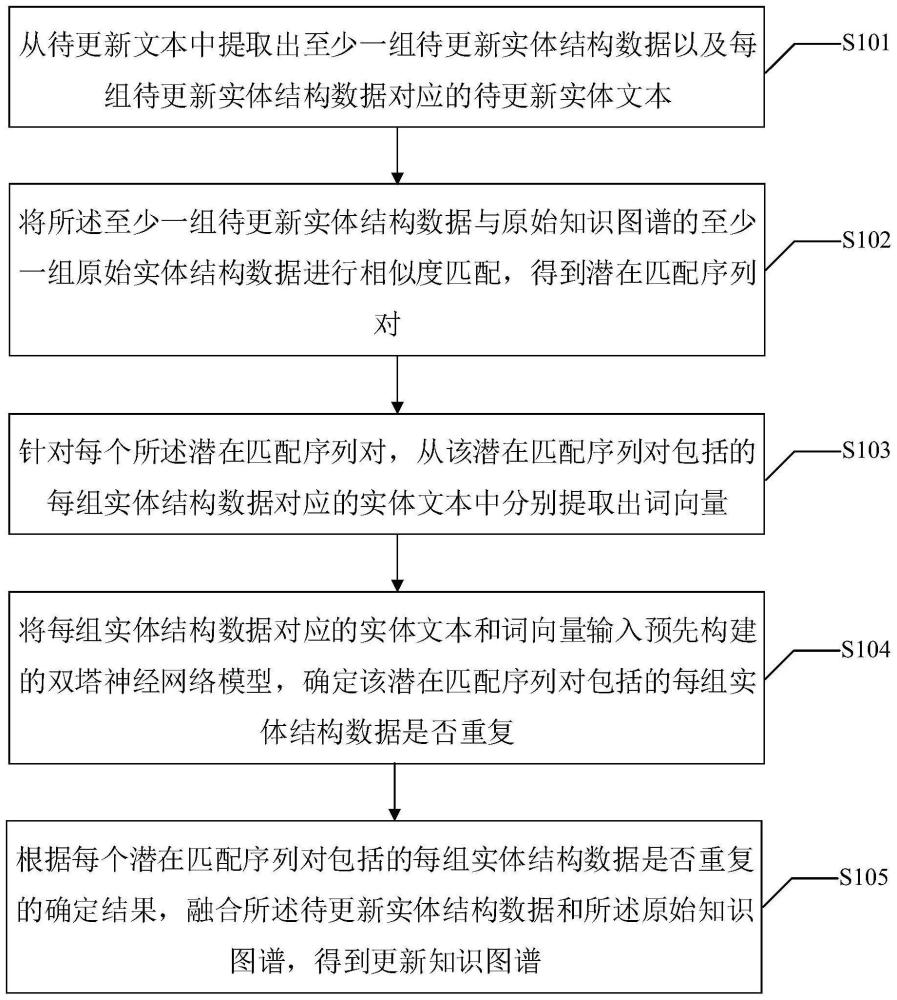
2、本技术实施例提供了一种知识融合方法,所述方法包括:
3、从待更新文本中提取出至少一组待更新实体结构数据以及每组待更新实体结构数据对应的待更新实体文本;
4、将所述至少一组待更新实体结构数据与原始知识图谱的至少一组原始实体结构数据进行相似度匹配,得到潜在匹配序列对;
5、针对每个所述潜在匹配序列对,从该潜在匹配序列对包括的每组实体结构数据对应的实体文本中分别提取出词向量;
6、将每组实体结构数据对应的实体文本和词向量输入预先构建的双塔神经网络模型,确定该潜在匹配序列对包括的每组实体结构数据是否重复;
7、根据每个潜在匹配序列对包括的每组实体结构数据是否重复的确定结果,融合所述待更新实体结构数据和所述原始知识图谱,得到更新知识图谱。
8、进一步的,所述将每组实体结构数据对应的实体文本和词向量输入预先构建的双塔神经网络模型,确定该潜在匹配序列对包括的每组实体结构数据是否重复,包括:
9、将该潜在匹配序列对包括的每组实体结构数据对应的实体文本输入所述双塔神经网络模型,提取每组实体结构数据对应的实体文本的语义向量;
10、将每组实体结构数据对应的实体文本的语义向量与词向量进行拼接,得到每组实体结构数据对应的特征向量;
11、根据每组实体结构数据对应的特征向量提取深度表征向量;
12、根据每组实体结构数据对应的深度表征向量,确定每组实体结构数据之间的匹配度;
13、根据每组实体结构数据之间的匹配度,确定该潜在匹配序列对包括的每组实体结构数据是否重复。
14、进一步的,所述双塔神经网络模型包括两个分支结构和全连接层;每个分支结构包括词嵌入层、拼接层和表示层;所述双塔神经网络模型的两个分支结构的表示层之间共享权重;
15、所述将每组实体结构数据对应的实体文本和词向量输入预先构建的双塔神经网络模型,确定该潜在匹配序列对包括的每组实体结构数据是否重复,包括:
16、将一组实体结构数据对应的实体文本对应输入一个分支结构中的词嵌入层,以提取该组实体结构数据对应的实体文本的语义向量;
17、将该组实体结构数据对应的词向量和该组实体结构数据对应的实体文本的语义向量输入该分支结构中的拼接层,拼接得到该组实体结构数据对应的特征向量;
18、将该组实体结构数据对应的特征向量输入该分支结构中的表示层,提取该组实体结构数据对应的深度表征向量;
19、将两组实体结构数据对应的深度表征向量输入所述全连接层,确定两组实体结构数据之间的匹配度;
20、根据该潜在匹配序列对包括的两组实体结构数据之间的匹配度和预设匹配度阈值,确定该潜在匹配序列对包括的两组实体结构数据是否重复。
21、进一步的,所述根据每个潜在匹配序列对包括的每组实体结构数据是否重复的确定结果,融合所述待更新实体结构数据和所述原始知识图谱,得到更新知识图谱,包括:
22、根据每个潜在匹配序列对包括的每组实体结构数据是否重复的确定结果,确定所述至少一组待更新实体结构数据中的目标实体结构数据和/或所述至少一组原始实体结构数据中的去重实体结构数据;
23、基于所述目标实体结构数据和所述去重实体结构数据,更新所述原始知识图谱,得到更新知识图谱。
24、进一步的,所述根据每个潜在匹配序列对包括的每组实体结构数据是否重复的确定结果,确定所述至少一组待更新实体结构数据中的目标实体结构数据和/或所述至少一组原始实体结构数据中的去重实体结构数据,包括:
25、针对每个潜在匹配序列对,若该潜在匹配序列对包括的每组实体结构数据重复,且重复的实体结构数据分别为一组待更新实体结构数据和一组原始实体结构数据,则将该组待更新实体结构数据确定为一组重复实体结构数据;
26、若该潜在匹配序列对包括的每组实体结构数据重复,且重复的实体结构数据为两组待更新实体结构数据,则将其中一组待更新实体结构数据确定为一组重复实体结构数据;
27、若该潜在匹配序列对包括的每组实体结构数据重复,且重复的实体结构数据为两组原始实体结构数据,则将其中一组原始实体结构数据确定为一组去重实体结构数据;
28、将所述至少一组待更新实体结构数据中除重复实体结构数据之外的实体结构数据确定为所述目标实体结构数据。
29、进一步的,所述将所述至少一组待更新实体结构数据与原始知识图谱的至少一组原始实体结构数据进行相似度匹配,得到潜在匹配序列对,包括:
30、将所述至少一组待更新实体结构数据和所述至少一组原始实体结构数据合并为实体结构数据集合;
31、遍历所述实体结构数据集合,将多组实体结构数据两两组合为一个序列对;
32、确定每个序列对中实体结构数据之间的相似度;
33、根据每个序列对中实体结构数据之间的相似度,从组合得到的序列对中筛选出潜在匹配序列对。
34、进一步的,所述方法还包括:
35、将每次融合过程中确定出的相互不重复的两组实体结构数据记录为一个过滤序列对,得到过滤序列对表;
36、在下一次融合过程中,在遍历所述实体结构数据集合,将多组实体结构数据两两组合为一个序列对时,根据所述过滤序列对表对组合出的所述序列对进行过滤。
37、本技术实施例还提供了一种知识融合装置,所述装置包括:
38、第一提取模块,用于从待更新文本中提取出至少一组待更新实体结构数据以及每组待更新实体结构数据对应的待更新实体文本;
39、第一匹配模块,用于将所述至少一组待更新实体结构数据与原始知识图谱的至少一组原始实体结构数据进行相似度匹配,得到潜在匹配序列对;
40、第二提取模块,用于针对每个所述潜在匹配序列对,从该潜在匹配序列对包括的每组实体结构数据对应的实体文本中分别提取出词向量;
41、第二匹配模块,用于将每组实体结构数据对应的实体文本和词向量输入预先构建的双塔神经网络模型,确定该潜在匹配序列对包括的实体结构数据是否重复;
42、融合模块,用于根据每个潜在匹配序列对包括的实体结构数据是否重复的确定结果,融合所述待更新实体结构数据和所述原始知识图谱,得到更新知识图谱。
43、本技术实施例还提供一种电子设备,包括:处理器、存储器和总线,所述存储器存储有所述处理器可执行的机器可读指令,当电子设备运行时,所述处理器与所述存储器之间通过总线通信,所述机器可读指令被所述处理器执行时执行如上述的一种知识融合方法的步骤。
44、本技术实施例还提供一种计算机可读存储介质,该计算机可读存储介质上存储有计算机程序,该计算机程序被处理器运行时执行如上述的一种知识融合方法的步骤。
45、本技术实施例提供的一种知识融合方法、装置、电子设备及存储介质,首先基于相似度匹配粗筛得到潜在匹配序列对,进一步结合词向量建模技术并使用双塔神经网络模型精筛确定重复的实体结构数据,进而融合得到更新知识图谱。这样,通过结合前沿双塔神经网络和传统的自然语言技术,能够更准确地匹配实体结构数据,从而实现知识的准确高效融合,更新得到更准确的知识图谱。
46、为使本技术的上述目的、特征和优点能更明显易懂,下文特举较佳实施例,并配合所附附图,作详细说明如下。
- 还没有人留言评论。精彩留言会获得点赞!