一种面向代码相似性检测的跨编程语言迁移方法和系统
本发明涉及软件工程和深度学习领域,具体涉及一种面向代码相似性检测的跨编程语言迁移方法和系统。
背景技术:
1、代码克隆检测是软件工程中的一个重要任务,旨在从大型代码库中识别出功能上相似的源代码,这些相似的代码对称为代码克隆。识别出来的代码片段可以帮助程序员审查或重构代码。近年来,工业界和学术界已经针对代码克隆检测问题提出了许多新颖的神经网络模型,这些神经网络模型在代码克隆基准测试上取得了很好的性能,例如bigclonebench和poj-104。
2、根据相似代码的定义,代码克隆可以分为四种类型。我们专注于解决type-4类型的代码克隆,即功能相似的代码对,这是最具挑战性的类型,无法通过简单的文本匹配准确检测。学术界和工业界提出了几种用于检测type-4类型代码克隆的神经网络模型,这些模型利用通过编译器获取的抽象语法树或数据流信息来帮助理解代码功能。在训练阶段,代码片段被编码成低维稠密向量,并拉近代码克隆对在隐式空间中的向量距离,推远非克隆对的向量距离。然而,每种编程语言的抽象语法树的结构和节点属性都是独特的,因此这些基于抽象语法树和数据流的方法很难迁移到新的编程语言。
3、综上所述,现有的代码克隆检测模型存在一个重要缺陷,即它们仅支持单一编程语言。在现实世界中,大型的软件工程项目通常由多种编程语言文件组成,既有像python这样的脚本语言也有像c/c++和rust这样的系统编程语言。因此,仅使用检测单一语言代码克隆的模型不能满足多语言代码克隆检测的需求。另外,这些代码克隆检测模型通常依赖于大量标注数据进行训练,对于一些不常见的编程语言,标注数据很难以获得,这极大地限制了模型在这些标注数据稀少的低资源编程语言上的检测代码克隆的能力。
4、一种解决方案是使用统一的编译器生成的中间表示(ir)来表示不同语言中的代码。模型可以在ir上进行训练,而不是在源代码上进行训练,使其能够学习跨不同编程语言的共同表征。然而,获取不同编程语言的ir需要大量的领域专业知识和工程努力来修复编译错误,在语言扩展性方面存在问题。另一个解决方案是利用预训练的多语言代码编码器。多语言代码编码器在包含多种编程语言的大型代码语料库上进行自监督模型预训练,在这个过程中可以通过自监督预训练学习到编程语言无关的代码上下文表示。然而,仅使用自监督代码表示在目标语言进行克隆检测的性能仍然不如有监督微调。
5、对比学习在视觉和语言相似性任务中被证明是能带来很大增益的自监督预训练任务。对比学习的原则是为数据的不同表现形式学习到一致的向量表示。同一数据实例的不同表示形式被称为正语义对比样本,而其他实例则被称为负语义对比样本。在对比学习自监督训练过程中,通过拉近正样本表示间的向量距离并推远负样本表示间的距离,模型可以为同一数据实例但不同表示形式的样本学习到一致的向量表示。已经有一些工作使用对比学习进行代码相似性学习。这些工作使用源代码到源代码编译器创建同一代码的不同形式作为正对比样本,使用其他源代码作为负对比样本,或者使用变量重命名生成正对比样本,使用代码漏洞注入获得负对比样本。
6、目前学术届和工业届尚无有效的方法可以实现代码相似性检测的跨语言迁移,即将在有标注数据的高资源语言上训练的相似性检测模型迁移到无标注数据的低资源语言上。
技术实现思路
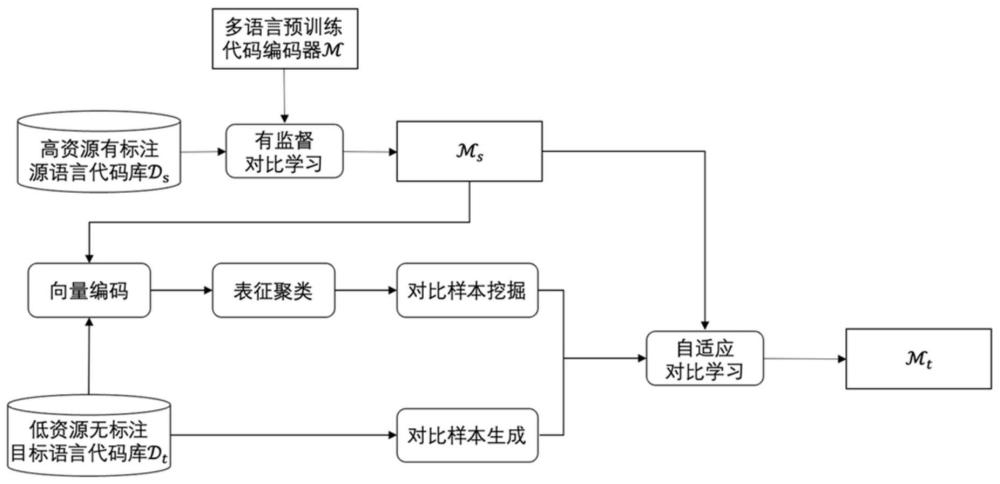
1、针对上述现有技术存在的问题,本发明提出了一种面向代码相似性检测的跨编程语言迁移方法和系统,本发明主要由三部分组成:基于预训练代码编码器的目标编程语言对比样本挖掘、基于代码转译和变量名替换的对比样本生成、基于对比样本挖掘和对比样本生成的自适应对比学习框架。
2、第一部分,基于预训练代码编码器的目标编程语言对比样本挖掘
3、该部分基于一个在高资源编程语言上微调的预训练代码编码器,通过聚类方法在低资源语言上挖掘正负对比样本。
4、(1.1)获取高资源编程语言上微调的多语言预训练代码编码器:本方法使用大规模多语言代码数据预训练的transformer模型获取代码向量编码,例如codebert和graphcodebert模型。在有标注数据的高资源编程语言上,例如c++和python,本发明使用有监督的对比学习训练目标,即infonce损失函数微调多语言预训练代码编码器。特别地,在原始transformer编码器的最后一层之后添加了一个使用relu激活函数的两层前馈网络作为预训练代码编码器,并使用[cls]令牌的最后一层隐藏状态来生成代码向量编码,最后通过代码向量编码之间的余弦相似度实现代码克隆检测。具体的,本发明使用原始代码字符串作为输入,并使用在代码数据上预训练的bpe代码分词器对输入代码字符串进行分词,将分词后的令牌输入多语言预训练代码编码器进行向量编码。在高资源语言上微调后的多语言预训练代码编码器可以拉近高资源语言上代码克隆对的代码向量的空间距离,推远非克隆对的向量距离。
5、(1.2)获取低资源语言代码表征聚类:通过上述步骤在高资源编程语言上微调的多语言预训练代码编码器(后简称ms)可以对任意代码片段进行向量编码,包括一些低资源编程语言。同时,ms的代码克隆检测能力具有一定的跨编程语言迁移性,可以直接迁移到低资源语言上对代码进行编码同时通过向量相似度进行克隆检测。本发明发现,直接将ms迁移到低资源语言上的代码克隆检测性能可以超过简单的基于文本相似度的匹配方法,例如bm25。基于多语言预训练代码编码器的跨语言迁移能力,本发明直接使用微调后的ms对无标注的低资源语言代码片段进行向量编码来获取代码表征,并对整个低资源语言代码库中的代码表征使用kmeans算法进行表征聚类,将低资源语言的所有代码分为c个簇。
6、(1.3)基于表征聚类的低资源语言对比样本挖掘:这一步骤的目的是通过步骤(1.2)的表征聚类结果,从低资源语言代码库中挖掘出对比学习样本,解决低资源语言上标注数据缺失的问题。对于低资源语言代码库中的任一代码片段p,找到和p属于同一个簇的所有代码片段,并计算p和这些代码片段的向量相似度,取和p向量距离最接近的前k个簇内代码片段作为候选的对比学习正样本;取所有和p不在同一个簇内的代码片段作为候选的对比学习负样本。
7、第二部分,基于代码转译和变量名替换的对比样本生成
8、在第一部分中,对比样本挖掘的准确率直接依赖于ms的跨编程语言迁移能力,然而直接迁移的模型性能较为有限,挖掘得到的对比样本通常会包含伪正样本和伪负样本,直接在精度较低的挖掘得到样本上进行迁移学习甚至会导致模型性能下降。因此,提出了一种基于代码回译和变量名替换的对比样本生成方法,通过代码数据增强方法获取一定正确的正对比样本。
9、第三部分,基于对比样本挖掘和对比样本生成的自适应对比学习框架
10、在第一部分挖掘得到的对比样本来源于整个代码库,形式上更加多样,但由于模型迁移能力的限制,会包含错误的正负对比样本;在第二部分生成的对比样本一定能保证和原始代码功能一致,但是由于生成方法固定,多样化较受限。为了将这两方面获得的对比学习样本结合在一起,发挥各自的优势并形成互补,提出了一个自适应对比学习框架。
11、(3.1)自适应对比学习样本选择策略:本方法提出了一种自适应的对比学习样本策略,以在整个训练过程动态地调整选择挖掘得到/生成得到的对比样本的偏好。本方法采用了线性衰减的方法来调整在整个训练过程中选择挖掘得到/生成得到的对比样本的偏好参数αt。直观上,模型在训练的早期阶段难以准确地挖掘对比学习样本,因此应该提高生成得到样本的偏好,以减少噪声。然而,当模型逐渐适应新的编程语言模式时,增加选择挖掘得到的对比样本的偏好就变得有利了。这种调整使得能够引入更大的复杂性和多样性,从而增强了模型处理更广泛语义变化的能力。
12、(3.2)迭代式对比学习训练:在每一个训练步重新挖掘对比学习样本是非常耗时的,甚至在代码库较大时是不可行的,因为必须对所有的程序重新编码,并再次运行kmeans来更新对比学习样本。为了减少训练时间的成本,只在每个训练周期的开始更新每个程序挖掘得到的对比学习样本。此外,将代码库随机分为两部分,以减小用于kmeans聚类和邻居搜索的池的大小。本发明采用了在两部分代码库之间交替的训练策略。在训练开始时,首先在第一部分上挖掘对比学习样本,然后在第一部分上训练模型。然后切换为第二部分,使用增强的模型在第二部分上挖掘更精确的对比学习样本,如此反复,迭代式地增强模型在目标编程语言上的代码克隆检测能力。
13、基于上述三部分内容,本发明提出的一种面向代码相似性检测的跨编程语言迁移方法,包括:
14、利用高资源有标注源语言代码库对多语言预训练代码编码器进行有监督对比学习,得到微调的多语言预训练代码编码器;
15、将低资源无标注目标语言代码库分为两部分,基于两部分代码库轮流对微调的多语言预训练代码编码器进行自适应对比学习,所述的自适应对比学习中的对比样本获取方式包括挖掘和生成两种模式,训练过程采用线性衰减方法调整偏好参数,基于偏好参数从挖掘和生成的对比样本中抽样;
16、将经过自适应对比学习之后得到的多语言预训练代码编码器作为跨编程语言迁移之后的结果,用于在低资源目标语言上实现代码相似性检测。
17、此外,本发明还提出一种面向代码相似性检测的跨编程语言迁移系统,用于实现上述方法。
18、本发明具备的有益效果是:本发明可以将一个在高资源语言上训练的相似性检测模型,即微调的预训练代码编码器迁移到低资源语言上,在低资源语言上实现代码相似性检测。
- 还没有人留言评论。精彩留言会获得点赞!