一种基于异构超图的自监督教科书问答方法
本发明涉及教育应用领域,具体涉及一种基于异构超图的自监督教科书问答方法。
背景技术:
1、教科书问答是指利用自然语言处理和机器学习技术,对教科书中的问题进行自动回答的任务。这个任务对于教育资源的开发和利用具有非常重要的意义,可以帮助学生更好地理解教材内容和提高学习效率。然而,由于教科书问答的数据往往具有高度的复杂性和非结构性,因此如何构建有效的模型来解决这个问题一直是学术界和工业界所面临的难题。当前教科书问答方法可以分为两类:基于深度学习的方法,以及基于知识图谱和图神经网络的方法。
2、基于深度学习的方法侧重于通过深度神经网络来提取文本特征和图表特征,并通过特征融合方法来进行正确答案的预测。近年来随着transformer在多模态领域的崛起,xu等人提出了一种基于transformer的融合多阶段域预训练和多模态交叉注意力的新模型moca,解决了大量多模态输入的特征融合问题。但基于深度学习的方法由于采用的是lstm、cnn、transformer等深度神经网络,往往难以直接处理和建模复杂的关系和结构,例如概念之间的依赖关系、层次关系和推理链条等。
3、相比之下,基于知识图谱和图神经网络的方法能够更好地捕捉和建模这些复杂的关系。ma等人提出了一个关系感知的细粒度推理(relation-aware fine-grainedreasoning,rafr)网络,利用图神经网络进行图表的知识提取,提出了基于语义依赖关系和图内节点间相对位置的关系检测算法,利用文本背景知识辅助视觉图的生成,并基于教学图引导注意力和问题引导注意力对问题图节点进行推理,实现细粒度的知识推理。daesikkim等人则用节点表示教科书中的概念和实体,边表示它们之间的关系,将教科书中的文本和图像信息结合起来,形成一个多模态背景知识图,并提出了fusion gcn(f-gcn)从该图中提取特征。
技术实现思路
1、本发明所要解决的技术问题是:
2、为了解决教科书问答中的问题、答案和知识点三者之间高阶关联建模的问题,本发明提供一种基于异构超图的自监督教科书问答方法。
3、为了解决上述技术问题,本发明采用的技术方案为:
4、一种基于异构超图的自监督教科书问答方法,其特征在于包含以下步骤:
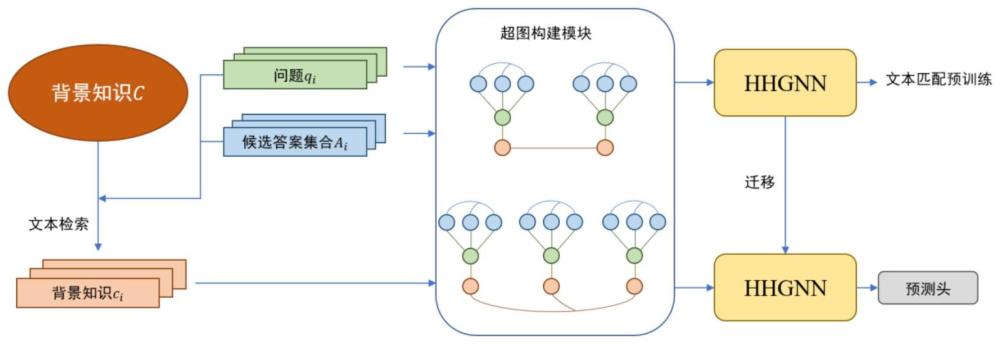
5、步骤1:获取教科书问答数据集其中n表示问题数量,qi表示第i个问题,ai=[a1,…,ak]表示第i个问题的k个候选答案,c表示所有的背景知识;
6、步骤2:对于数据集d中的每一个问题,使用文本检索方法从c中检索出与其相关度最高的一段背景知识,文本检索后数据集可表示为其中ci表示与qi相关度的一段背景知识;
7、步骤3:根据检索后的问题、答案以及背景知识之间的关联关系,构建一个教科书问答异构超图;
8、步骤4:使用深度神经网络模型对步骤3中构建的异构超图中的节点进行特征初始化;
9、步骤5:构建异构超图神经网络来学习步骤4中节点特征初始化后的异构超图;
10、步骤5.1:根据步骤2中文本检索的结果构建正负样本对;
11、步骤5.2:计算步骤5.1中构建的每个样本对中文本的相似度,并根据二元交叉熵来优化异构超图神经网络;
12、步骤6:在步骤5的异构超图神经网络后面接上一个多层感知器作为预测头,将拼接后的神经网络作为问答模型,并进行参数微调,通过交叉熵损失来进一步优化该模型的参数;
13、步骤7:测试过程中,对于任意一个问题节点q,将其特征与该问题的所有候选答案节点特征分别进行融合,然后输入到预测头中,最后通过softmax函数得到每一个候选答案的置信度,置信度最高的为正确答案。
14、本发明进一步的技术方案:步骤3中教科书问答异构超图的构建方式具体为:
15、若多个答案来自于同一个问题的候选答案集合中,则将这些答案连接;
16、若某个答案存在于某个问题的候选答案集合中,则将该答案与该问题连接;
17、若某个背景知识为某个问题的文本检索的结果,则将该背景知识与该问题连接;
18、若多个背景知识来自于同一课程,则将这些背景知识连接。
19、本发明进一步的技术方案:步骤4中所使用的深度神经网络模型为roberta-base、yolo和resnet101;对于答案节点、背景知识节点以及无图表问题节点,利用开源的预训练过的roberta-base模型获取初始序列特征;对于有图表问题节点,则是在文本序列特征的基础上融入视觉特征;有图表问题中问题节点的特征初始化公式如下:
20、
21、
22、
23、式中,表示第i个问题的文本数据,表示第i个问题的图表数据,du(·)表示图表理解模块,表示哈达马积运算,表示对建模后得到的表征向量,d表示向量维度,表示对建模后得到的表征向量,表示多模态融合表征向量,即问题文本与问题图表融合的结果;
24、图表理解模块利用resnet101模型来学习yolo在图表中检测到的第k个区域的特征向量,然后使用全连接层将其坐标投影为一个d维的位置向量,再将特征向量与特征向量取算术平均,得到图表中第k个区域的特征表示最后将所有区域的特征表示进行求和,得到整张图表的特征表示具体计算公式如下所示:
25、
26、
27、式中,为可学习的参数矩阵,μ表示yolo在图表中检测到的区域数量。
28、本发明进一步的技术方案:步骤5.1中正负样本对的构建,具体为:
29、将所有问题按照课程顺序排序,对于每一个问题,存在一个正样本对和一个负样本对;首先,将问题节点qi和它的所有候选答案节点进行特征融合,作为queryi,其中m表示选项的个数;queryi计算公式如下:
30、
31、然后将queryi和其最相关的背景知识ci作为正样本对(queryi,ci),和不相关的背景知识cj作为负样本对(queryi,cj),其中n表示问题数量。
32、本发明进一步的技术方案:步骤5.2中使用余弦相似度来计算各样本对中文本的相似度,具体为:
33、s(i,j)=cosine similarity(queryi,cj) (7)采用二分类交叉熵作为损失函数优化异构超图神经网络,损失计算公式如下:
34、
35、本发明进一步的技术方案:步骤5中微调模型参数,具体为:
36、对于任意一个问题节点qi,将其特征与该问题的所有候选答案节点特征分别进行融合;最终,添加一个多层感知器作为预测头,并通过交叉熵来微调模型参数,计算公式如下:
37、
38、
39、
40、式中,n表示问题数量,m表示每个问题的选项的数量,softmax(·)是一种激活函数,mlp(·)表示多层感知器,||表示拼接操作。
41、一种计算机系统,其特征在于包括:一个或多个处理器,计算机可读存储介质,用于存储一个或多个程序,其中,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现上述的方法。
42、一种计算机可读存储介质,其特征在于存储有计算机可执行指令,所述指令在被执行时用于实现上述的方法。
43、本发明的有益效果在于:
44、本发明提供的一种基于异构超图的自监督教科书问答方法,首先,设计了新的异构超图结构来准确表示问题、答案和知识点之间的关联关系。通过异构超图能够更全面而准确地捕捉数据中的复杂关系。其次,引入了文本匹配自监督任务来对模型进行预训练。该任务利用文本检索的结果作为监督信号,使得模型能够提取问题和知识点之间更丰富的语义信息。通过这种方式,我们能够有效地利用未标注数据来提升模型的性能。最后,在带有正确答案标注的数据上微调网络,以进一步优化模型的性能和泛化能力。
45、与现有技术相比,本发明通过超图表示和图神经网络的结合,以及图自监督学习的引入,有效地解决了教科书问答中的问题、答案和知识点三者之间高阶关联建模的问题。本发明采用了自监督文本匹配预训练,以降低模型对大量有标注的教科书问答数据样本的依赖。该方法在实验中展现了出色的性能,为教育领域中的问答任务提供了一种有力的解决方案。
- 还没有人留言评论。精彩留言会获得点赞!