基于主题模型的标签生成方法、装置、设备和存储介质与流程
本技术涉及人工智能,尤其涉及一种基于主题模型的标签生成方法、装置、设备和存储介质。
背景技术:
1、随着人工智能技术的不断发展,自然语言处理技术对人们的生活产生了重大影响,其中,主题分析作为自然语言处理任务的一个重要研究方向,用于在一系列文本数据中发现抽象主题标签,其相关技术已被广泛的应用于多个领域,如新闻推荐、购物平台的商品推荐等。
2、现有的标签生成方法通过中文分词以及文本词项的特征向量化算法,将评论文本的词项从词项文本空间到向量空间的转化,再由文本词项向量空间转换到文本主题空间,最后根据生成的文本主题模型进行文本主题聚类,得到文本标签。
3、然而,现有的标签生成方法提取的文本特征不够准确,涵盖的语义信息不够丰富,导致主题标签的可解释性较低;同时,生成的标签是仅使用核心关键词进行拼接而成的,标签的代表性和质量较低。
技术实现思路
1、本技术提供一种基于主题模型的标签生成方法、装置、设备和存储介质,用以解决现有的标签生成方法生成的主题标签的可解释性较低,且标签质量较低的问题。
2、第一方面,本技术提供一种基于主题模型的标签生成方法,该方法包括:
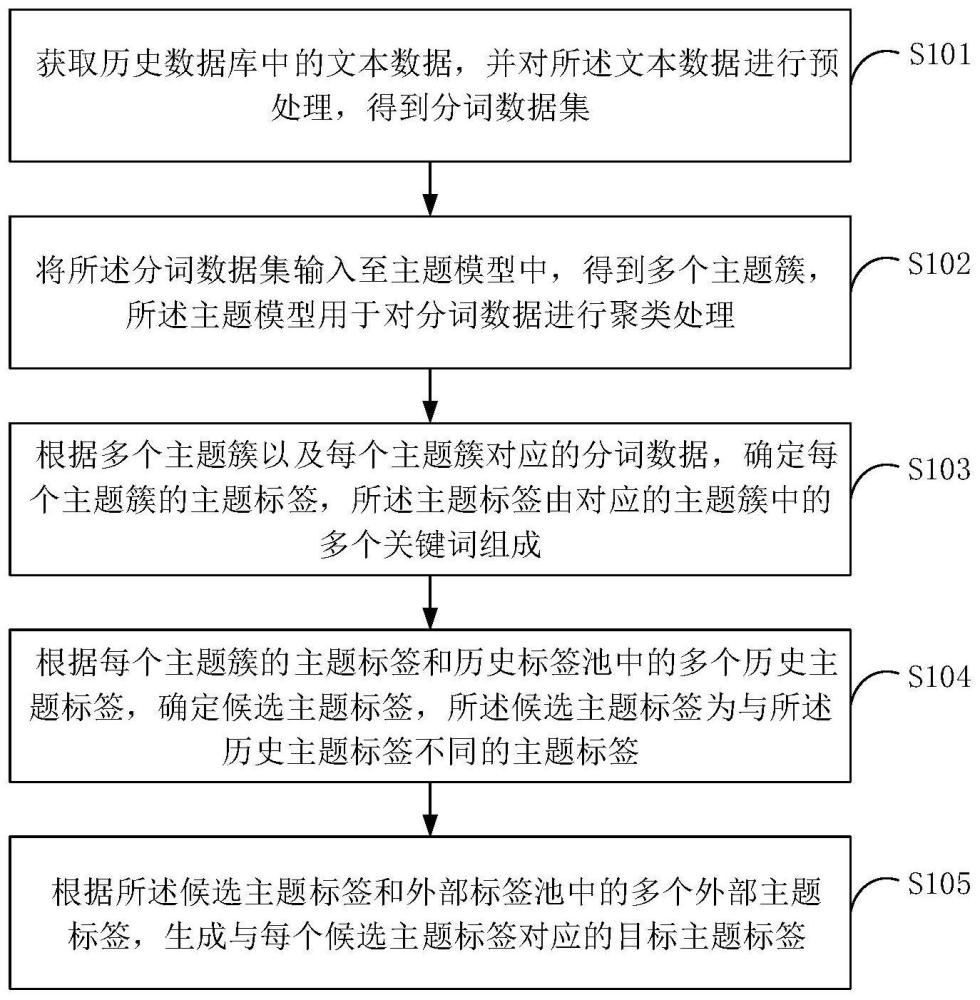
3、获取历史数据库中的文本数据,并对所述文本数据进行预处理,得到分词数据集;
4、将所述分词数据集输入至主题模型中,得到多个主题簇,所述主题模型用于对分词数据进行聚类处理;
5、根据多个主题簇以及每个主题簇对应的分词数据,确定每个主题簇的主题标签,所述主题标签由对应的主题簇中的多个关键词组成;
6、根据每个主题簇的主题标签和历史标签池中的多个历史主题标签,确定候选主题标签,所述候选主题标签为与所述历史主题标签不同的主题标签;
7、根据所述候选主题标签和外部标签池中的多个外部主题标签,生成与每个候选主题标签对应的目标主题标签。
8、可选的,所述根据每个主题簇的主题标签和历史标签池中的多个历史主题标签,确定候选主题标签,包括:
9、计算每个主题簇对应的关键词与历史主题标签对应的关键词的匹配程度,得到每个主题簇的匹配率;
10、当所述匹配率小于预设匹配率阈值时,则将所述匹配率对应的主题簇的主题标签作为候选主题标签。
11、可选的,所述根据所述候选主题标签和外部标签池中的多个外部主题标签,生成与每个候选主题标签对应的目标主题标签,包括:
12、根据所述候选主题标签对应的多个关键词,从历史标签池中获取第一文本数据,所述第一文本数据为所述历史标签池中,与所述候选主题标签关联性最强的文本数据;
13、将所述第一文本数据输入至句子编码模型,得到第一句向量,并对所述第一句向量进行加权平均处理,得到第一平均句向量;
14、从所述外部标签池中获取第二文本数据,并将所述第二文本数据输入至所述句子编码模型,得到第二句向量,所述第二文本数据为所述外部标签池中,与所述候选主题标签关联性最强的文本数据;
15、对所述第二句向量进行加权平均处理,得到第二平均句向量;
16、判断所述第一平均句向量和所述第二平均句向量的文本相似度是否大于预设相似度;
17、在所述第一平均句向量和所述第二平均句向量的文本相似度大于预设相似度时,将所述第二文本数据对应的外部主题标签作为所述候选主题标签对应的目标主题标签。
18、可选的,所述根据所述候选主题标签和外部标签池中的多个外部主题标签,生成与每个候选主题标签对应的目标主题标签,包括:
19、将所述候选主题标签对应的多个关键词输入至词向量模型,得到第一词向量,并对所述第一词向量进行加权平均处理,得到第一平均词向量;
20、从所述外部标签池中获取第三文本数据,并将所述第三文本数据输入至所述词向量模型,得到第二词向量,所述第三文本数据为所述外部标签池中,与所述候选主题标签对应的多个关键词的关联性最强的文本数据;
21、对所述第二词向量进行加权平均处理,得到第二平均词向量;
22、根据所述第一平均词向量和所述第二平均词向量的文本相似度,确定所述候选主题标签对应的目标主题标签。
23、可选的,所述根据所述候选主题标签和外部标签池中的多个外部主题标签,生成与每个候选主题标签对应的目标主题标签,包括:
24、对所述候选主题标签对应的多个关键词进行排序处理,得到多组关键词;
25、根据所述多组关键词,从所述外部标签池中获取与所述多组关键词对应的目标外部主题标签,并对所述目标外部主题标签进行分词处理以及笛卡尔积组合,得到多个拼接词;
26、对所述多个拼接词进行筛选处理,得到多个目标拼接词;
27、将所述多个目标拼接词作为所述候选主题标签对应的目标主题标签。
28、可选的,所述生成与每个候选主题标签对应的目标主题标签之后,所述方法还包括:
29、根据多个目标主题标签,生成可视化评估信息;
30、控制显示装置显示所述可视化评估信息,以对所述多个目标主题标签进行评估处理。
31、第二方面,本技术提供一种基于主题模型的标签生成装置,该装置包括:
32、获取模块,用于获取历史数据库中的文本数据,并对所述文本数据进行预处理,得到分词数据集;
33、处理模块,用于将所述分词数据集输入至主题模型中,得到多个主题簇,所述主题模型用于对分词数据进行聚类处理;
34、所述处理模块,还用于根据多个主题簇以及每个主题簇对应的分词数据,确定每个主题簇的主题标签,所述主题标签由对应的主题簇中的多个关键词组成;
35、所述处理模块,还用于根据每个主题簇的主题标签和历史标签池中的多个历史主题标签,确定候选主题标签,所述候选主题标签为与所述历史主题标签不同的主题标签;
36、生成模块,用于根据所述候选主题标签和外部标签池中的多个外部主题标签,生成与每个候选主题标签对应的目标主题标签。
37、可选的,所述处理模块,还用于计算每个主题簇对应的关键词与历史主题标签对应的关键词的匹配程度,得到每个主题簇的匹配率;
38、所述处理模块,还用于当所述匹配率小于预设匹配率阈值时,则将所述匹配率对应的主题簇的主题标签作为候选主题标签。
39、可选的,所述装置还包括:判断模块;
40、所述获取模块,还用于根据所述候选主题标签对应的多个关键词,从历史标签池中获取第一文本数据,所述第一文本数据为所述历史标签池中,与所述候选主题标签关联性最强的文本数据;
41、所述处理模块,还用于将所述第一文本数据输入至句子编码模型,得到第一句向量,并对所述第一句向量进行加权平均处理,得到第一平均句向量;
42、所述处理模块,还用于从所述外部标签池中获取第二文本数据,并将所述第二文本数据输入至所述句子编码模型,得到第二句向量,所述第二文本数据为所述外部标签池中,与所述候选主题标签关联性最强的文本数据;
43、所述处理模块,还用于对所述第二句向量进行加权平均处理,得到第二平均句向量;
44、所述判断模块,用于判断所述第一平均句向量和所述第二平均句向量的文本相似度是否大于预设相似度;
45、所述生成模块,还用于在所述第一平均句向量和所述第二平均句向量的文本相似度大于预设相似度时,将所述第二文本数据对应的外部主题标签作为所述候选主题标签对应的目标主题标签。
46、可选的,所述处理模块,还用于将所述候选主题标签对应的多个关键词输入至词向量模型,得到第一词向量,并对所述第一词向量进行加权平均处理,得到第一平均词向量;
47、所述处理模块,还用于从所述外部标签池中获取第三文本数据,并将所述第三文本数据输入至所述词向量模型,得到第二词向量,所述第三文本数据为所述外部标签池中,与所述候选主题标签对应的多个关键词的关联性最强的文本数据;
48、所述处理模块,还用于对所述第二词向量进行加权平均处理,得到第二平均词向量;
49、所述生成模块,还用于根据所述第一平均词向量和所述第二平均词向量的文本相似度,确定所述候选主题标签对应的目标主题标签。
50、可选的,所述处理模块,还用于对所述候选主题标签对应的多个关键词进行排序处理,得到多组关键词;
51、所述获取模块,还用于根据所述多组关键词,从所述外部标签池中获取与所述多组关键词对应的目标外部主题标签;
52、所述处理模块,还用于并对所述目标外部主题标签进行分词处理以及笛卡尔积组合,得到多个拼接词;
53、所述处理模块,还用于对所述多个拼接词进行筛选处理,得到多个目标拼接词;
54、所述生成模块,还用于将所述多个目标拼接词作为所述候选主题标签对应的目标主题标签。
55、可选的,所述装置还包括:控制模块;
56、所述生成模块,还用于根据多个目标主题标签,生成可视化评估信息;
57、所述控制模块,用于控制显示装置显示所述可视化评估信息,以对所述多个目标主题标签进行评估处理。
58、第三方面,本技术提供一种基于主题模型的标签生成设备,包括:
59、存储器;
60、处理器;
61、其中,所述存储器存储计算机执行指令;
62、所述处理器执行所述存储器存储的计算机执行指令,以实现如上述第一方面和第一方面各种可能的实现方式所述的基于主题模型的标签生成方法。
63、第四方面,本技术提供一种计算机存储介质,其上存储有计算机程序,所述计算机程序被处理器执行以实现如上述第一方面及第一方面各种可能的实现方式所述的基于主题模型的标签生成方法。
64、本技术提供的基于主题模型的标签生成方法,通过获取历史数据库中的文本数据,并对所述文本数据进行预处理,得到分词数据集,将所述分词数据集输入至主题模型中,得到多个主题簇,所述主题模型用于对分词数据进行聚类处理,根据多个主题簇以及每个主题簇对应的分词数据,确定每个主题簇的主题标签,根据每个主题簇的主题标签和历史标签池中的多个历史主题标签,确定候选主题标签,根据所述候选主题标签和外部标签池中的多个外部主题标签,生成与每个候选主题标签对应的目标主题标签,该方法不仅提高了主题标签的语义信息的丰富性和可解释性,并且提高了主题标签的代表性和质量。
- 还没有人留言评论。精彩留言会获得点赞!