一种模型训练的方法、图像处理的方法以及相关装置与流程
本技术实施例涉及图像处理,具体涉及一种模型训练的方法、图像处理的方法以及相关装置。
背景技术:
1、文本识别是指从图像中识别出其中的文字内容。图像文本中的文本形态可以是打印体、手写体、或者数字墨水文字等。包含文本的图像可以是由电子设备拍摄的数字图像、文档的扫描版本、或者其他任何形式包含文本的图像。通过对图像中的文本进行识别,能够实现各种不同的用途。例如说,可以实现将手写字符数字化,或者用于从所拍摄的图像中识别车牌号、证件信息,或者实现基于图像的信息检索等等。
2、针对图像中的文本识别,当前传统的识别方式依旧是使用文本检测模型对图像中的文本检测框进行检测,确定出文本检测框的位置信息后,再通过文本识别模型对该文本检测框的位置信息进行识别,以识别对应的文本内容。换句话说,当前对图像中的文本内容进行识别的过程中,检测过程和识别过程分别采用不同模型对应的算法,增加了计算消耗和时间增加;而且文本检测框的位置信息在较大程度上对文本识别的效果产生直接影响,导致文本识别的准确率和识别效果都欠佳。
技术实现思路
1、本技术实施例提供了一种模型训练的方法、图像处理的方法以及相关装置,用于节省计算消耗和时间,并且提高识别准确率和识别效果。
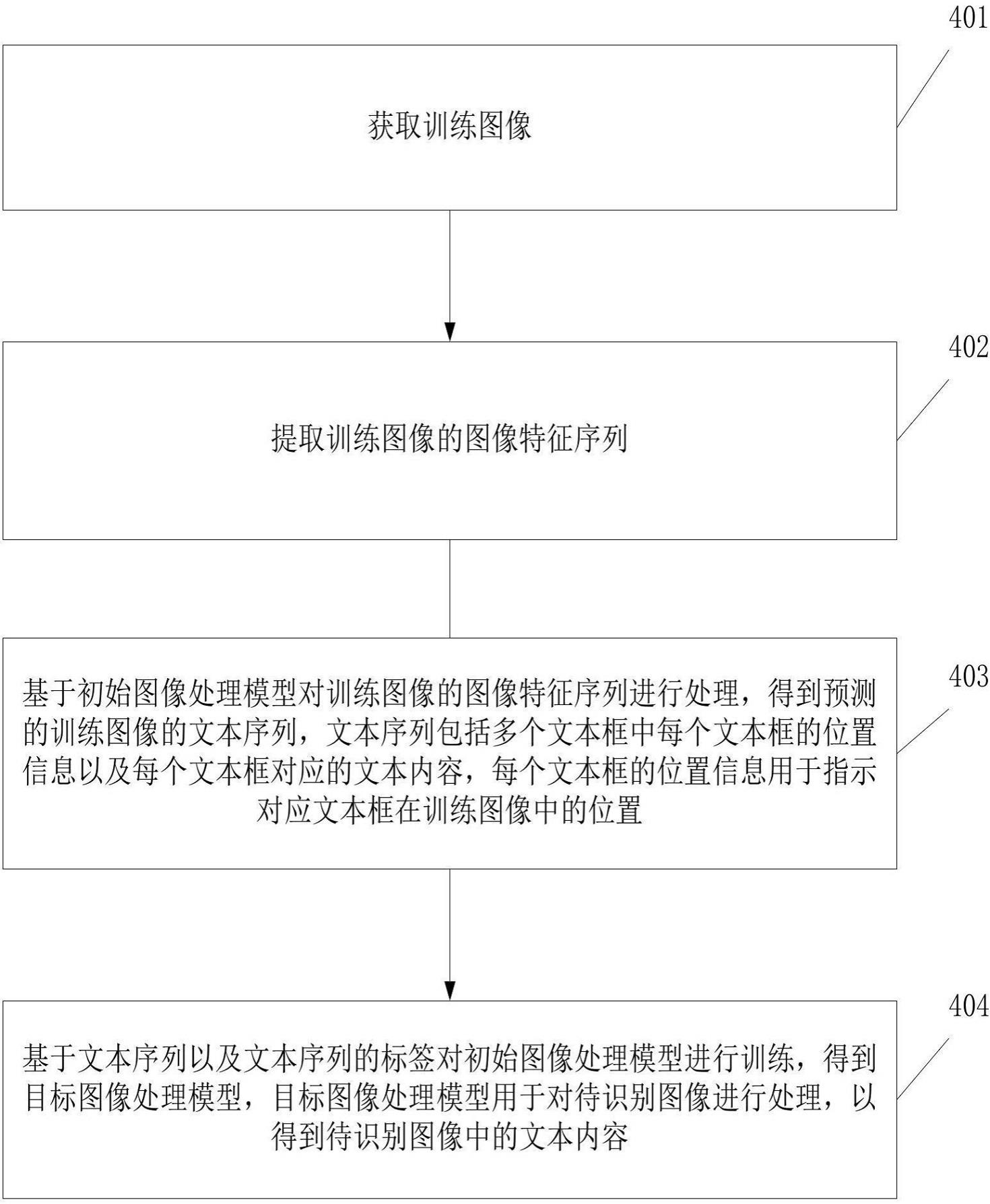
2、第一方面,本技术实施例提供了一种模型训练的方法。该模型训练的方法包括:获取训练图像;提取所述训练图像的图像特征序列;基于初始图像处理模型对所述训练图像的图像特征序列进行处理,得到预测的所述训练图像的文本序列,所述文本序列包括多个文本框中每个所述文本框的位置信息以及每个所述文本框对应的文本内容,每个所述文本框的位置信息用于指示对应所述文本框在所述训练图像中的位置;基于所述文本序列和所述文本序列的标签对所述初始图像处理模型进行训练,以得到目标图像处理模型,所述目标图像处理模型用于对所述待识别图像进行处理,以得到所述待识别图像中的文本内容。
3、第二方面,本技术实施例提供一种图像处理的方法。该图像处理的方法包括:获取待识别图像;提取所述待识别图像的图像特征序列;将所述待识别图像的图像特征序列作为目标图像处理模型的输入,得到所述待识别图像的预测文本序列,所述预测文本序列包括多个预测文本框中每个所述预测文本框的位置信息和每个所述预测文本框对应的文本内容,每个所述预测文本框的位置信息用于指示对应所述预测文本框在所述待识别图像中的位置,所述目标图像处理模型是以所预测到的训练图像的文本序列和所述文本序列的标签为训练数据,对初始图像处理模型进行迭代训练后得到的机器学习模型,所述文本序列由所述初始图像处理模型对所述训练图像的图像特征序列进行处理得到,所述文本序列包括多个文本框中每个所述文本框的位置信息以及每个所述文本框对应的文本内容,每个所述文本框的位置信息用于指示对应所述文本框在所述训练图像中的位置。
4、第三方面,本技术实施例提供一种模型训练装置。该模型训练装置包括获取单元、提取单元以及处理单元。其中,获取单元,用于获取训练图像。提取单元,用于提取所述训练图像的图像特征序列。处理单元,用于基于初始图像处理模型对所述训练图像的图像特征序列进行处理,得到预测的所述训练图像的文本序列,所述文本序列包括多个文本框中每个所述文本框的位置信息以及每个所述文本框对应的文本内容,每个所述文本框的位置信息用于指示对应所述文本框在所述训练图像中的位置。所述处理单元,用于基于所述文本序列和所述文本序列的标签对所述初始图像处理模型进行迭代训练,以得到目标图像处理模型,所述目标图像处理模型用于对所述待识别图像进行处理,以得到所述待识别图像中的文本内容。
5、在一些可选的实施方式中,处理单元用于:将所述训练图像的图像特征序列、多个文本框的排列顺序以及所述文本序列的标签输入所述初始图像处理模型,所述文本序列的标签包括当每个所述文本框的位置信息标签以及每个所述文本框对应的文本内容标签。处理单元用于通过所述初始图像处理模型执行以下步骤,以得到预测的所述训练图像的文本序列:对于当前文本框,基于按照所述排列顺序排列在所述当前文本框前的所有文本框的位置信息标签和所述所有文本框的文本内容标签,确定所述当前文本框的位置信息;基于所述当前文本框的位置信息、排列在所述当前文本框前的所有文本框的位置信息标签和所述所有文本框的文本内容标签,确定所述当前文本框所对应的当前文本内容。
6、在另一些可选的实施方式中,所述初始图像处理模型包括l层transformer模型;处理单元,用于:针对当前文本框,将按照所述排列顺序排列在所述当前文本框前的所有文本框的位置信息标签和所述所有文本框的文本内容标签,作为第l层所述transformer模型的输入,以得到所述当前文本框的位置信息,其中,所述l层transformer模型中的第一层transformer模型的输入为所述训练图像的图像特征序列,所述l层transformer模型中的第l-1层transformer模型的输入为第l-2层transformer模型输出的第一文本框的位置信息所对应的标签、排列在所述第一文本框前的所有文本框的文本内容标签和文本内容标签,输出为所述第一文本框的位置信息,所述第一文本框为排列在所述当前文本框的前一个文本框。
7、在另一些可选的实施方式中,处理单元,用于:计算所述文本序列和所述文本序列的标签之间的差异,以得到损失值;基于所述损失值对所述初始图像处理模型进行训练,以得到目标图像处理模型。
8、在另一些可选的实施方式中,提取单元,用于:对所述训练图像进行图像划分,得到多个子图像;基于预设特征提取模型对每个所述子图像进行特征提取处理,得到每个所述子图像的图像特征;将多个所述子图像的图像特征进行拼接处理,得到所述训练图像的图像特征序列。
9、在另一些可选的实施方式中,提取单元,用于:基于所述预设特征提取模型中的每个注意力机制,对第一子图像中的每个图像区域进行特征提取处理,得到所述第一子图像中每个所述图像区域的图像特征,所述第一子图像为所述多个子图像中的任意一个;基于所述预设特征提取模型中的全连接层对所述第一子图像中每个所述图像区域的图像特征进行拼接处理,得到所述第一子图像的图像特征。
10、第四方面,本技术实施例提供一种图像处理装置。该图像处理装置包括获取单元、提取单元以及处理单元。其中,获取单元,用于获取待识别图像。提取单元,用于提取所述待识别图像的图像特征。处理单元,用于将所述待识别图像的图像特征序列作为目标图像处理模型的输入,得到所述待识别图像的预测文本序列,所述预测文本序列包括多个预测文本框中每个所述预测文本框的位置信息和每个所述预测文本框对应的文本内容,每个所述预测文本框的位置信息用于指示对应所述预测文本框在所述待识别图像中的位置,所述目标图像处理模型是以所预测到的训练图像的文本序列和所述文本序列的标签为训练数据,对初始图像处理模型进行迭代训练后得到的机器学习模型,所述文本序列由所述初始图像处理模型对所述训练图像的图像特征序列进行处理得到,所述文本序列包括多个文本框中每个所述文本框的位置信息以及每个所述文本框对应的文本内容,每个所述文本框的位置信息用于指示对应所述文本框在所述训练图像中的位置。
11、在一些可选的实施方式中,处理单元,用于将所述待识别图像的图像特征序列、多个预测文本框的排列顺序作为所述目标图像处理模型的输入。处理单元,用于通过所述目标图像处理模型执行以下步骤,以得到所述待识别图像的预测文本序列:对于当前预测文本框,基于按照所述多个预测文本框的排列顺序排列在所述当前预测文本框前的所有预测文本框的位置信息和所述所有预测文本框的文本内容,确定所述当前预测文本框的位置信息;基于所述当前预测文本框的位置信息、排列在所述当前预测文本框的所有预测文本框的位置信息和所述所有预测文本框的文本内容,确定所述当前预测文本框所对应的当前文本内容。
12、在另一些可选的实施方式中,所述目标图像处理模型包括l层transformer模型;处理单元用于:针对当前预测文本框,基于第l层所述transformer模型中的多头注意力层对所述当前预测文本框的位置信息、排列在所述当前预测文本框前的所有文本框的位置信息和所述所有预测文本框的文本内容进行处理,得到注意力特征;基于所述第l层所述transformer模型中的归一化层对所述注意力特征进行归一化处理,得到归一化层特征;基于所述第l层所述transformer模型中的前馈层对所述归一化层特征进行处理,得到所述当前预测文本框的预测概率,所述当前预测文本框的预测概率用于指示所述当前预测文本框所对应的当前文本内容。
13、本技术实施例第五方面提供了一种图像处理设备,包括:存储器、输入/输出(i/o)接口和存储器。存储器用于存储程序指令。处理器用于执行存储器中的程序指令,以执行上述第一方面的实施方式对应的模型训练的方法;或者,执行上述第二方面的实施方式对应的图像处理的方法。
14、本技术实施例第六方面提供了一种计算机可读存储介质,计算机可读存储介质中存储有指令,当其在计算机上运行时,使得计算机执行以执行上述第一方面的实施方式对应的模型训练的方法;或者,执行上述第二方面的实施方式对应的图像处理的方法。
15、本技术实施例第六方面提供了一种包含指令的计算机程序产品,当其在计算机或者处理器上运行时,使得计算机或者处理器执行上述以执行上述第一方面的实施方式对应的模型训练的方法;或者,执行上述第二方面的实施方式对应的图像处理的方法。
16、从以上技术方案可以看出,本技术实施例具有以下优点:
17、本技术实施例中,在获取到训练图像后,提取该训练图像的图像特征序列,并基于初始图像处理模型对训练图像的图像特征序列进行处理,得到预测的训练图像的文本序列。其中,在文本序列中,包括多个文本框中每个文本框的位置信息以及每个文本框对应的文本内容,每个文本框的位置信息能够指示对应文本框在训练图像中的位置。进一步地,再基于文本序列和文本序列的标签对初始图像处理模型进行训练,以得到目标图像处理模型。这样,在得到目标图像处理模型后,能够通过目标图像处理模型对待识别图像进行处理,直接识别得到待识别图像中的文本内容。通过上述方式,借助训练图像的图像特征序列先确定出训练图像的文本序列,进而借助该文本序列中每个文本框的位置信息和文本内容、以及相应的文本序列的标签对初始图像处理模型进行迭代训练,从而实现将文本检测和文本识别融合在所训练得到的目标图像处理模型中,省去了单独的文本检测模块,减少了计算消耗和时间,而且基于所训练得到的目标图像处理模型能够实现对待识别图像的文本内容的直接识别,无需依赖于文本检测框的位置信息,提高识别准确率和识别效果。
- 还没有人留言评论。精彩留言会获得点赞!