一种基于类脑视觉Transformer的图像修复方法及ADAS边缘设备
本发明涉及图像修复,尤其涉及一种基于类脑视觉transformer的图像修复方法及adas边缘设备。
背景技术:
1、随着计算机视觉和人工智能技术的迅猛发展,现有的高级驾驶辅助系统(adas)可以显著提升驾驶的安全性、便捷性和效率。adas依赖于环境感知模块来捕获实时图像或其他类型的周围车辆和道路交通信息。然而,户外驾驶经常会暴露于各种极端天气条件下,例如雨、雪和低光夜间驾驶。这些因素会限制摄像头的视野,降低系统的视觉感知能力,从而导致adas的判断不准确,可能引发交通事故。
2、图像修复网络具有将摄像头捕获的降质图像恢复成清晰图像的潜力,使系统能够获取准确的交通环境信息。图像修复网络受到了广泛的关注,并在恢复结果方面取得了显著的改进。大多数先进的图像修复网络主要基于transformer架构。然而,这些图像修复网络经常在计算效率和恢复性能之间难以取得平衡。同时,由softmax带来的异常值问题使得在边缘设备上量化部署图像修复网络的有效性变得具有挑战性。在标准的visiontransformers(vits)中,自注意力中的较小权重也会导致特征聚合,产生不必要的特征作为噪音,并干扰图像恢复过程。此外,现有的图像修复网络主要是为单一任务设计的,无法适应不同的天气条件。
3、传统的adas部署在基于cmos技术的设备上,通过传统的冯·诺伊曼体系结构实现各个模块之间的通信(即内存、处理器)。然而,随着摩尔定律的过时和内存壁问题的出现,一种具有大内存容量、快速处理能力和复杂数据计算能力的计算系统对于adas至关重要。但由于大多数transformer网络具有大量参数,这使得难以将其应用于汽车摄像头等设备。
技术实现思路
1、本发明提供一种基于类脑视觉transformer的图像修复方法及adas边缘设备,解决的技术问题在于:如何提供一种适应不同的天气条件的性能优异的图像修复网络,以及如何将该图像修复网络轻量化部署在adad系统中。
2、为解决以上技术问题,本发明提供一种基于类脑视觉transformer的图像修复方法,包括步骤:
3、s1、构建基于类脑视觉transformer的图像修复网络;
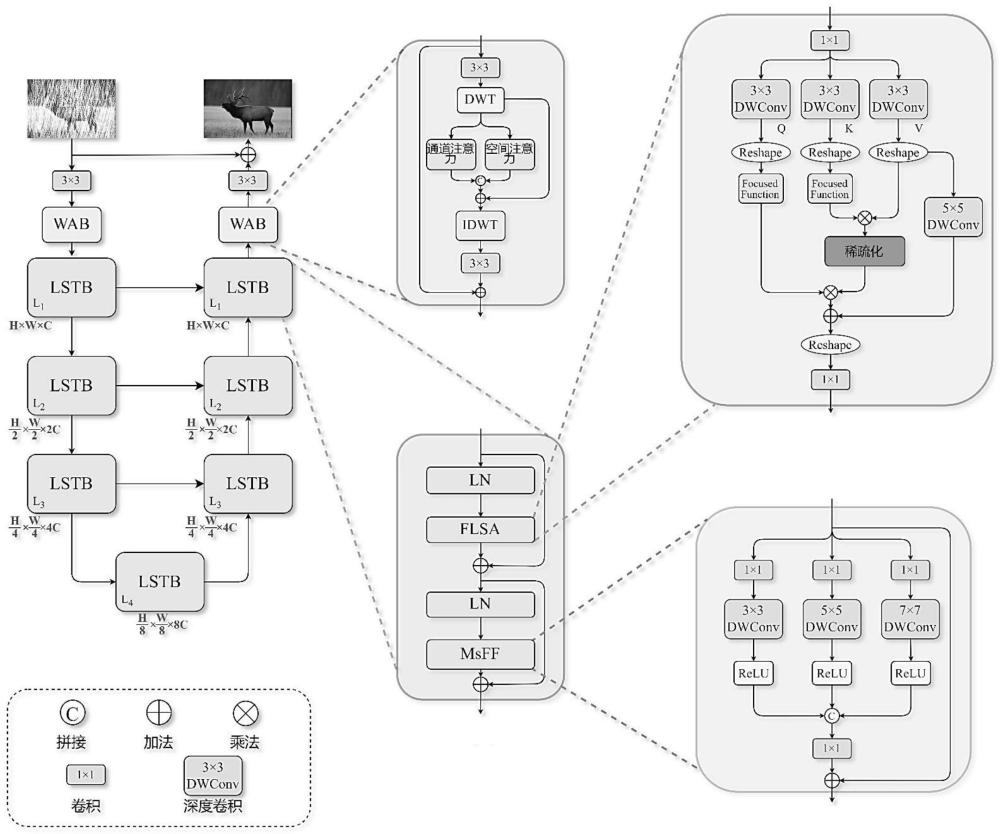
4、所述图像修复网络为u型网络结构,从输入至输出依次设置有第一3×3卷积层、第一小波注意力块、q个线性稀疏transformer块、第二小波注意力块、第二3×3卷积层,q为不小于2的奇数;
5、退化图像输入所述第一3×3卷积层进行卷积后输入所述第一小波注意力块进行注意力提取,提取结果输入q个线性稀疏transformer块进行下采样和上采样,采样结果输入所述第二小波注意力块进行注意力提取,提取结果输入所述第二3×3卷积层进行卷积后,所得卷积结果与所述退化图像相加,得到复原图像;
6、所述线性稀疏transformer块的整个过程用以下方程表示为:
7、f′i=flsa(ln(fi-1))+fi-1
8、fi=msff(ln(f′i))+f′i
9、其中,f′i、fi-1分别表示第i-1个线性稀疏transformer块的输出和输入,f′i表示中间特征图,ln()表示层归一化操作,flsa()表示聚焦线性稀疏注意力提取操作,msff()表示多尺度前馈操作;
10、s2、对所述图像修复网络进行训练;
11、s3、将需要恢复的退化图像输入训练完成的所述图像修复网络,输出复原图像。
12、进一步地,flsa()用公式表示为:
13、flsatt(q,k,v)=focuse(q)mask(s,k)+dwconv(v)
14、其中,q,k,v表示transformer中的查询、键和值,flsatt(q,k,v)表示聚焦线性稀疏注意力提取,focuse()表示聚焦函数,s=focuse(kt)v表示分数,mask()表示掩码函数,k表示top-k操作中的可调参数,dwconv()表示深度卷积;
15、聚焦函数focuse()表示为:
16、
17、其中,x指代自变量,relu()表示relu函数,x**p表示x的逐元素的p次幂。
18、进一步地,msff()用公式表示为:
19、xout=conv1×1[x3,x5,x7]
20、其中,x3、x5、x7表示对输入特征xin分别使用大小为3×3、5×5和7×7的卷积核进行卷积的相应输出,[]表示连接操作,conv1×1表示1×1卷积;
21、x3、x5、x7表示为:
22、xi=relu(dwconvi×i(conv1×1(xin)))
23、其中,i=3,5,7,dwconvi×i表示使用卷积核大小为i×i的深度卷积。
24、进一步地,所述第一小波注意力块和所述第二小波注意力块采用相同的小波注意力块,所述小波注意力块的过程用公式表示为:
25、iout=conv3×3(idwt([is,ic]+id))+iin
26、其中,iin表示所述小波注意力块的输入特征,conv3×3表示3×3卷积,idwt()表示离散小波逆变换,id、is、ic均为中间特征且有:
27、id=dwt(conv3×3(iin))
28、is=sigmoid(conv1×1([gap(id),gmp(id)]))
29、ic=conv1×1(gap(id))
30、其中,dwt()表示离散小波变换,gmp()表示全局最大池化,gap()表示全局平均池化,sigmoid()表示sigmoid函数。
31、进一步地,所述步骤s2的训练过程中,所述图像修复网络的损失函数设计为:
32、lmixture=αlmse+(1-α)lssim
33、其中,lmixture表示混合损失,lmse表示均方误差损失,lssim表示结构相似性指数度量损失,α是用于平衡lmse和lssim的超参数;
34、lmse的计算公式如下:
35、
36、其中,c、h、w分别表示复原图像或真实图像的高度、宽度和通道数,yc,h,w表示标签值,表示预测值;
37、lssim的计算公式如下:
38、
39、其中,μx、μy分别表示复原图像和真实图像的像素平均值,σxy表示复原图像和真实图像之间的协方差,σx、σy分别表示复原图像和真实图像的像素标准差,c1、c2是不同的常数。
40、进一步地,q=7,7个所述线性稀疏transformer块构成u型结构,前4个所述线性稀疏transformer块进行下采样,将图像尺寸依次变换为h×w×c、后3个所述线性稀疏transformer块进行上采样,将图像尺寸依次变换为h×w×c。
41、本发明还提供一种图像修复adas边缘设备,其关键在于:部署有上述方法中所述的训练完成的图像修复网络,其中将所述图像修复网络的注意力层和线性层的权重映射到第一忆阻器交叉阵列;将捕获的降级图像转换为并行模拟电压,并将所述并行模拟电压输入到的所述第一忆阻器交叉阵列的每一行以执行注意力和前向传播计算。
42、具体的,所述图像修复网络的深度卷积通过第二忆阻器交叉阵列实现,在深度方向上,来自不同通道的电压行同时输入到所述第二忆阻器交叉阵列的相应行;
43、所述图像修复网络的1×1卷积通过第三忆阻器交叉阵列实现,不同通道的相同位置的电压输入到所述第三忆阻器交叉阵列的相同行。
44、本发明提供的一种基于类脑视觉transformer的图像修复方法及adad边缘设备,创建了一种u型结构的图像修复网络(本发明称之为线性稀疏transformer,简称为lsformer),在该网络中,提出了线性稀疏transformer块(lstb),在线性稀疏transformer块中设计了聚焦线性稀疏注意力块(flsa)降低计算复杂性,有助于减轻与softmax相关的异常值问题,采用内容稀疏性来选择最相关的特征信息,从而通过这些有效特征提高了恢复图像的质量,促进在智能辅助驾驶车辆中部署图像修复网络。本发明在线性稀疏transformer块中还设计了多尺度前馈网络(msff),以通过使用不同深度卷积核大小来增强局部表示。本发明在lsformer还提出了小波注意力块(wab),以提取输入图像的浅层特征并基于离散小波变换(dwt)来改进输出图像。此外,本发明提供了基于忆阻器类脑计算系统的高效且有前途的硬件实施方案,用于智能车辆中应用adas。本发明还评估了提出的网络在多个数据集上的性能,包括低照度增强、图像去雨和图像去雾等任务。结果表明,lsformer在这三个任务中均优于最先进的网络。此外,本发明还对提出的实施方案进行了多个度量测试,结果表明与现有的transformer电路相比,提出的方案更高效和稳定。
- 还没有人留言评论。精彩留言会获得点赞!