一种资源调度方法、装置、电子设备及存储介质与流程
本技术涉及云计算,尤其涉及一种资源调度方法、装置、电子设备及存储介质。
背景技术:
1、hive组件是基于apache hadoop的一个数据仓库,其使用计算引擎处理数据仓库存储的数据,所使用的资源(如cpu和内存)从基于apache hadoop的yarn资源管理器中申请。yarn资源管理器提供的资源通常是多种业务共用,因此,需要yarn资源管理器合理分配资源给不同业务组件(例如,hive、spark、flink等)产生的任务。
2、hive的计算引擎目前支持mr(mapreduce)、tez、spark等,即hive on mr、hive ontez、hive on spark。其中,hive on tez和hive on mr两种类型是在任务启动后动态申请资源,而且申请的资源数量没有上限。实际应用时,hive任务(本文中的hive任务是指hiveon tez任务或hive on mr任务)需要的资源少则申请的资源少,hive任务需要的资源多则申请的资源多,而这样会导致一个hive大任务把整个yarn集群的资源全部申请完,导致其他任务无法申请到资源,进而导致资源利用率低。
技术实现思路
1、有鉴于此,本技术提供了一种资源调度方法、装置、电子设备及存储介质,以解决资源利用效率低的问题,其公开的技术方案如下:
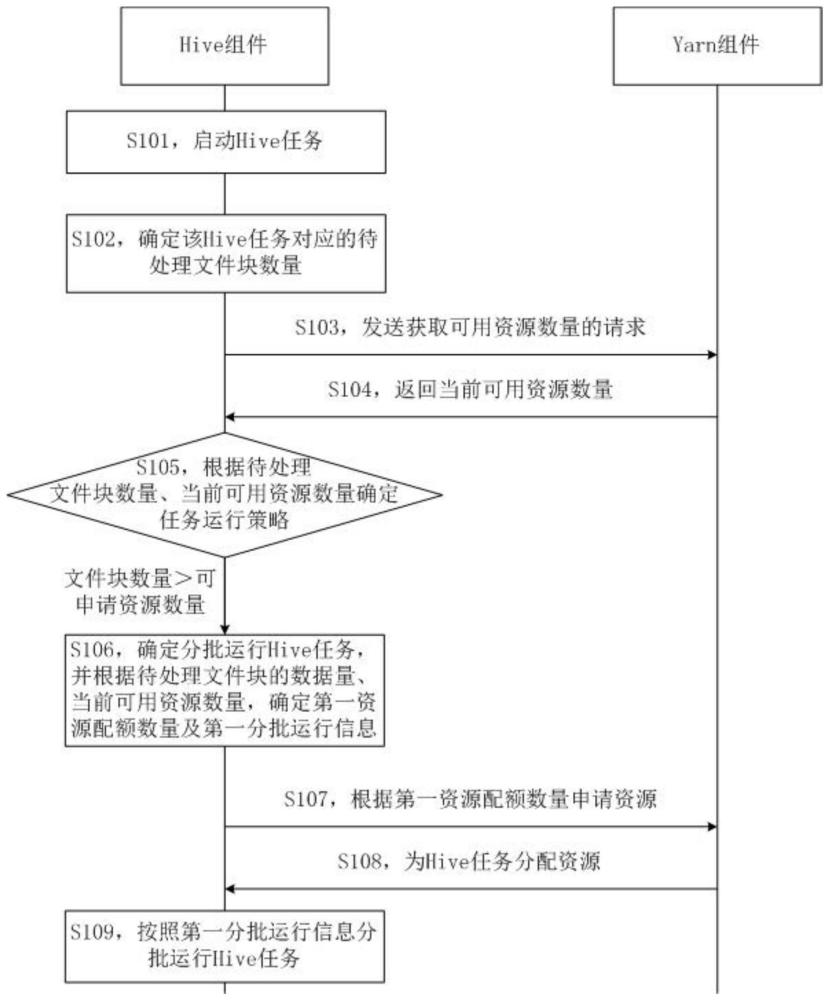
2、第一方面,本技术提供了一种资源调度方法,应用于hadoop集群中的hive组件,hadoop集群还包括资源集群,该方法包括:确定当前启动的hive任务对应的待处理文件块的信息,待处理文件块的信息包括待处理文件块的数量和总数据量;获取资源集群中的当前可用资源数量;根据待处理文件块的信息和当前可用资源数量,确定hive任务的资源配额数量,资源配额数量小于待处理文件块的数量;基于资源配额数量向资源集群申请资源;利用资源集群为hive任务分配的资源运行hive任务。可见,该方法根据hive任务对应的文件块的数量和总数据量以及当前可用资源数量确定资源配额数量。文件块的数据量可能小于基本规格(如128mb或256mb),因此按照文件块包含的数据量申请资源,小于直接按文件块数量申请的资源数量,即减少资源占用时长,从而更快地释放已分配资源,最终提高了资源利用效率。
3、在一种可能的实现方式中,根据待处理文件块的信息和当前可用资源数量,确定hive任务的资源配额数量,包括:根据待处理文件块的数量和当前可用资源数量确定任务运行策略,任务运行策略包括分批启动任务和同时启动任务;在分批启动任务的情况下,根据待处理文件块的总数据量及当前可用资源数量确定第一分批运行信息,并根据第一分批运行信息确定第一资源配额数量,第一分批运行信息包括分组数量及各个分组包含的文件块数量;在同时启动任务的情况下,根据待处理文件块的总数据量及单个资源的算力确定第二资源配额数量。可见,该实现方式在需要分批启动hive任务的情况下,根据hive任务的文件块的总数据量和当前可用资源数量确定的分组数量小于直接按照文件块数量确定的分组数量,即减少了分组数量,从而减少了资源占用时长,更快地释放已分配资源,最终提高了资源利用效率。
4、在一种可能的实现方式中,根据待处理文件块的数量和当前可用资源数量确定任务运行策略,包括:若待处理文件块的数量大于当前可用资源数量,确定任务运行策略是分批启动任务;若待处理文件块的数量小于或等于当前可用资源数量,确定任务运行策略是同时启动任务。
5、在一种可能的实现方式中,在分批启动任务的情况下,根据待处理文件块的总数据量及当前可用资源数量确定第一分批运行信息,包括:根据待处理文件块的总数量及单个资源的算力确定同时启动hive任务所需的资源需求量;根据资源需求量和当前可用资源数量确定hive任务对应的分组数量及每个分组包含的文件块的数量。
6、在一种可能的实现方式中,根据待处理文件块的总数量及单个资源的算力确定同时启动hive任务所需的资源需求量,包括:确定待处理文件块的总数量与单个资源的算力之间的第一比值;将第一比值取整得到hive任务所需的资源需求量。
7、在一种可能的实现方式中,根据资源需求量和当前可用资源数量确定hive任务对应的分组数量及每个分组包含的文件块的数量,包括:确定资源需求量与当前可用资源数量之间的第二比值;将第二比值取整得到hive任务对应的分组数量;根据hive任务的待处理文件块的总数据量及分组数量,确定每个分组包含的文件块的数量,每个分组包含的文件块的总数据量小于或等于当前可用资源数量的资源对应的总算力。
8、在一种可能的实现方式中,根据第一分批运行信息确定第一资源配额数量,包括:确定第一分批运行信息中每个分组包含的文件块的总数据量与单个资源的算力之间的第三比值;将第三比值取整得到第一资源配额数量。
9、在一种可能的实现方式中,在同时启动任务的情况下,根据待处理文件块的总数据量及单个资源的算力确定第二资源配额数量,包括:确定待处理文件块的总数据量与所单个资源的算力的第四比值;将第四比值取整得到第二资源配额数量。在当前可用资源数量满足同时启动hive任务的情况下,该方案根据hive任务包含的文件块的实际数据量确定申请的资源配额数量,可以减少申请资源的数量,提高资源利用率。
10、在一种可能的实现方式中,利用资源集群为hive任务分配的资源运行hive任务包括:在分批启动任务的情况下,判断实际分配资源数量能否处理一个分组包含的文件块的总数据量;如果实际分配资源数量能够处理一个分组包含的文件块的总数据量,则利用实际分配资源数量按照任务运行信息运行hive任务;如果实际分配资源数量不能处理一个分组包含的文件块的总数量,则根据待处理文件块包含的数据量及实际分配资源数量,确定第二分批运行信息,并利用实际分配资源按照第二分批运行信息运行hive任务,第二分批运行信息分组数量及各个分组包含的文件块数量。可见,该方案按照实际分配资源重新确定分批运行信息使得实际分配资源与数据处理量更匹配,从而实现合理分配负载,提高数据处理效率。
11、在一种可能的实现方式中,利用资源集群为hive任务分配的资源运行hive任务包括:在同时启动任务的情况下,判断实际分配资源数量能否处理hive任务的所有数据;如果实际分配资源数量不能处理hive任务的所有数据,则根据待处理文件块的总数据量和实际分配资源数量,确定第三分批运行信息;如果实际分配资源数量能够处理hive任务的所有数据,则利用实际分配资源数量按照任务运行信息运行hive任务,第三分批运行信息包括分组数量各分组包含的文件块数量。
12、第二方面,本技术还提供了一种资源调度装置,应用于hadoop集群中的hive组件,hadoop集群还包括资源集群,该装置包括:第一确定模块,用于确定当前启动的hive任务对应的待处理文件块的信息,待处理文件块的信息包括待处理文件块的数量和总数据量;可用资源获取模块,用于获取资源集群中的当前可用资源数量;第二确定模块,用于根据待处理文件块的信息和当前可用资源数量,确定hive任务的资源配额数量,资源配额数量小于待处理文件块的数量;资源申请模块,用于基于资源配额数量向资源集群申请资源;任务运行模块,用于利用资源集群为hive任务分配的资源运行hive任务。
13、第三方面,本技术还提供了一种电子设备,电子设备包括:一个或多个处理器和存储器;存储器用于存储程序代码;处理器用于运行程序代码,使得电子设备实现如第一方面任一项的资源调度方法。
14、第四方面,本技术还提供了一种计算机可读存储介质,其上存储有指令,当指令在电子设备上运行时,使得电子设备执行如第一方面任一项的资源调度方法。
15、第五方面,本技术还提供了一种计算机程序产品,其上存储有执行,当计算机程序产品在电子设备上运行时,使得电子设备实现第一方面任一项的资源调度方法。
16、应当理解的是,本技术中对技术特征、技术方案、有益效果或类似语言的描述并不是暗示在任意的单个实施例中可以实现所有的特点和优点。相反,可以理解的是对于特征或有益效果的描述意味着在至少一个实施例中包括特定的技术特征、技术方案或有益效果。因此,本说明书中对于技术特征、技术方案或有益效果的描述并不一定是指相同的实施例。进而,还可以任何适当的方式组合本实施例中所描述的技术特征、技术方案和有益效果。本领域技术人员将会理解,无需特定实施例的一个或多个特定的技术特征、技术方案或有益效果即可实现实施例。在其他实施例中,还可在没有体现所有实施例的特定实施例中识别出额外的技术特征和有益效果。
- 还没有人留言评论。精彩留言会获得点赞!