一种多视角单目标跟踪方法及装置
本发明涉及计算机视觉,尤其涉及一种多视角单目标跟踪方法及装置。
背景技术:
1、视觉是人类认知世界的重要途径之一,人类获取外部信息的80%来自视觉系统。计算视觉就是在了解人类视觉基础上,用成像系统代替人类视觉器官,用计算机代替人脑完成对输入图像的处理与理解。同时,随着信息技术与智能科学的发展,计算机视觉是人工智能领域热门学科之一和物联网感知层重要技术之一。而视觉目标跟踪(单目标跟踪)的方法的研究和应用作为计算机视觉领域的一个重要分支,越来越受到学界与工业界的关注。其任务是在一段视频序列中,给定同一个目标的初始位置和大小,预测后续帧中该目标的大小与位置。其广泛地运用到了科学技术、国防建设、航空航天、医药卫生以及国民经济等各个领域,研究目标跟踪的技术有着重大的实用价值和广阔的发展前景。而随着视觉目标领域的发展,往往一个视角的信息不足够应用于许多有挑战的跟踪场景下,而多视角的协同跟踪就显得尤为重要。多视角协同跟踪就是使用两个不同的视角对同一个目标进行跟踪。相比于单视角跟踪,多视角可用的信息明显增多,而且不同的视角间具有互补性,如果可以对不同视角的信息有效融合,就可以实现更加鲁棒的跟踪。现有技术中,公开号为cn104331901a的中国发明专利申请《一种基于tld的多视角目标跟踪装置及方法》实现一种多视角下的目标跟踪,针对单目视觉方法进行运动目标检测与跟踪时常常存在目标遮挡以及周围场景光线变化和阴影干扰等问题,通过多视角的信息融合单元融合多视角信息,利用学习机制,增强检测模块跟踪的强壮性,提高跟踪性能。
2、在实际应用中,单视角的目标跟踪经常会遇到低分辨率和遮挡等困难情况,这些挑战对于单视角来说影响非常大,对跟踪算法精度也会受到较大的影响。而加入另一个视角之后,可利用的信息更多,可以为当前跟踪目标的视角提供更多的补充信息,来缓解这些困难的情况。同时因为两个视角有着各自的优势,也为多视角跟踪提供了可行性与有效性。地面视角相比于无人机视角来说视角近,可以提供跟踪目标的局部细节信息。反之,无人机视角比地面视角广,可以提供跟踪目标的全局运动信息。但如何关联和融合来自不同视角的同一跟踪目标的互补信息是多视角单目标跟踪面临的关键问题,过去的工作利用transformer架构中的cross attention机制,设计了一个多视角协同学习模块mvcl。该模块通过计算两个搜索区域内目标的外观相似度,将无人机视角和地面视角下搜索区域内的同一跟踪目标关联起来,并融合互补的视觉信息。虽然它相对于过去的单视角跟踪器得到了很高的性能提升,但还是有一些不足之处。例如,当其设计的多视角跟踪器遇到严重遮挡,光干扰等原因会导致搜索区域质量较差,甚至不包含跟踪目标。此时再使用协同学习模块mvcl进行目标关联和融合时,将一个不包含跟踪目标的搜索区域特征融合则会导致该方法失效甚至引入噪声,影响后续的跟踪过程。
技术实现思路
1、本发明所要解决的技术问题在于如何提升多个视角下对同一目标的跟踪性能。
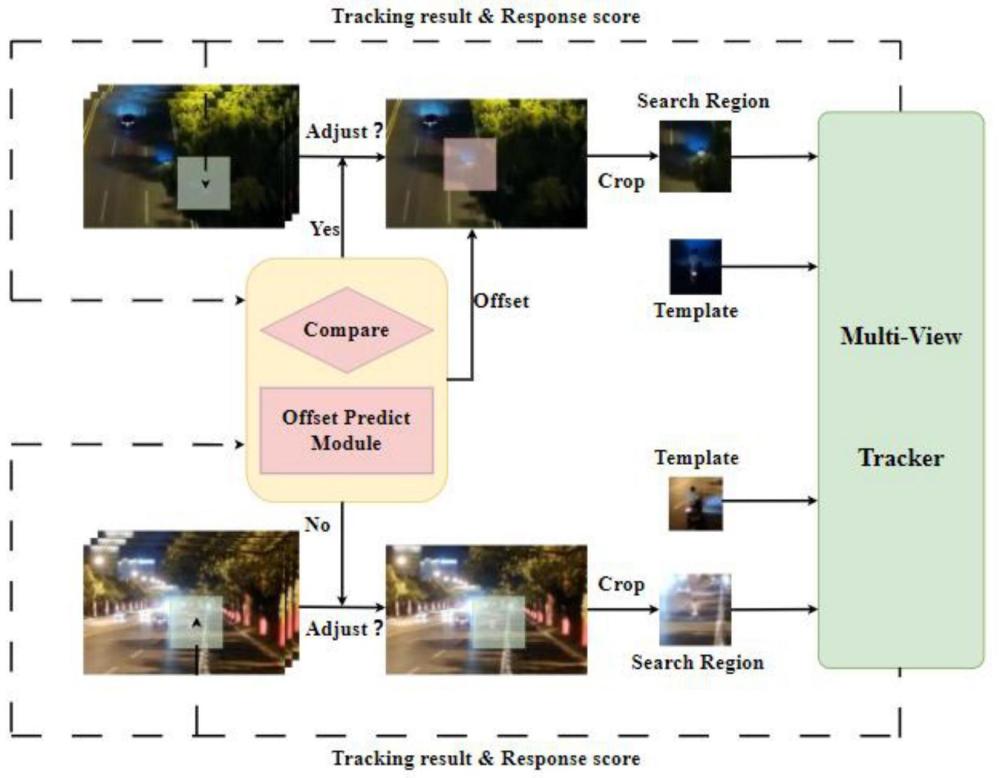
2、本发明是通过以下技术方案解决上述技术问题的:一种多视角单目标跟踪方法,包括以下步骤:
3、s10.无人机和地面拍摄设备采集多个场景的视频数据,获得无人机视频序列u={u1,u2,...,ut}和地面视频序列g={g1,g2,...,gt};
4、s20.将无人机视频序列u={u1,u2,...,ut}和地面视频序列g={g1,g2,...,gt}作为模型的输入,模型在每一帧跟踪处理前返回过去k帧的两个视角的跟踪结果,将两个视角的跟踪结果做差,得到偏移量序列;
5、s30.将偏移量序列输入到偏移量预测模块中,预测出当前帧的目标偏移量,根据上一帧的跟踪结果确定两个视角的原始搜索区域,得到跟踪结果的响应分数;
6、s40.根据跟踪结果的响应分数判断无人机搜索区域和地面搜索区域的质量,响应分数越高,搜索区域质量越好,反之越差,采用质量好的搜索区域以及预测出来的偏移量,计算另一个视角搜索区域调整后的位置;
7、s50.将两个视角的搜索区域送入多视角跟踪器,融合两个视角跟踪目标的信息,输出跟踪结果。
8、本发明的跟踪方法引入了两个视角间的偏移量这一几何关系,也就是跟踪结果的坐标差,保证搜索区域尽可能包含跟踪目标,对于定位到质量更好,更易于包含跟踪目标的搜索区效果更好。通过搜索区域调整策略,对模型产生的原始搜索区域进行调整,用质量高的搜索区域的位置以及偏移量来确定更改后的原始低质量搜索区域的位置。由于质量好的搜索区域更容易包含目标,通过偏移量更改后的另一个搜索区域也更容易包含跟踪目标,从而将不同视角下同一目标的信息进行有效地融合,以实现两个视角跟踪性能的提升。
9、优选的,步骤s20中在跟踪某序列的第t帧时,模型会返回当前帧前k帧的两个视角的跟踪结果,将无人机视角下的跟踪结果集记录为xu=[ut-k;...;ut-2;ut-1],地面视图的跟踪结果集记录为xg=[gt-k;...;gt-2;gt-1],ut-i和gt-i表示跟踪状态,xu和xg∈rk×4,k和t均为大于1的自然数,i为1至1-k的自然数,对于每个跟踪视角的每一帧跟踪结果,跟踪器都会输出一个边界框b=[x,y,w,h]作为跟踪状态,(x,y)为边界框左上顶点的坐标,w为边界框的宽度,h为边界框的高度,计算两个视角跟踪结果中心点的坐标差记为偏移量序列。
10、优选的,所述两个视角跟踪结果中心点的坐标(xc,yc)的计算公式为:
11、xc=x+0.5×w
12、yc=y+0.5×h;
13、两个视角下的跟踪结果中心点序列x′u和x′g为:
14、x′u=[u′t-k;...;u′t-2;u′t-1]
15、x′g=[g′t-k;...;g′t-2;g′t-1];
16、其中,u′t-i和g′t-i都是1×2的坐标(xc,yc)t-i;
17、再将两个视角下的跟踪结果中心点序列x′u和x′g做差,得到偏移量序列记为xoff=x′u-x′g=[xt-k;...;xt-2;xt-1]=[(δxt-k,δyt-k);...;(δxt-2,δyt-2);(δxt-1,δyt-1)],xoff∈rk×2。
18、优选的,步骤s30中预测出当前帧的目标偏移量的方法包括:
19、s31、将偏移量序列输入到变换器编码器,通过concat操作进行前k帧偏移量聚合,input embedding将特征映射到更高维空间,然后与位置编码postional emcoding相加,送入n层堆叠式编码器;
20、s32、n层堆叠式编码器通过编码器里的多头自注意力、残差连接、层归一化以及前馈网络进行特征编码;
21、s33、将编码后的特征输入编码送入n层堆叠式解码器中,解码器输入二维xdec,xdec值设为(0,0),解码器的输入xdec通过自注意力计算后,与特征输入编码进行交叉注意力计算,得出预测的当前帧偏移量(δx,δy)。
22、优选的,获得两个视角搜索区域后,比较当前帧两个视角搜索区域的响应分数,响应分数高的搜索区域质量更好,并将其中心点作为当前帧下目标的位置,根据质量好的搜索区域的中心点坐标,再加上预测的偏移量,得到质量差的搜索区域调整后的位置。
23、优选的,步骤s40中当地面视角搜索区域质量差时,调整方式为:
24、x′g=xu+δx
25、y′g=yu+δy;
26、当无人机视角搜索区域质量差时,调整方式为:
27、x′u=xg-δx
28、y′u=yg-δy。
29、本发明还提供一种多视角单目标跟踪装置,包括:
30、数据采集模块,无人机和地面拍摄设备采集多个场景的视频数据,获得无人机视频序列u={u1,u2,...,ut}和地面视频序列g={g1,g2,...,gt};
31、模型建立模块,用于将无人机视频序列u={u1,u2,...,ut}和地面视频序列g={g1,g2,...,gt}作为模型的输入,模型在每一帧跟踪处理前返回过去k帧的两个视角的跟踪结果,将两个视角的跟踪结果做差,得到偏移量序列;
32、偏移量预测模块,用于将偏移量序列输入到偏移量预测模块中,预测出当前帧的目标偏移量,根据上一帧的跟踪结果确定两个视角的原始搜索区域,得到跟踪结果的响应分数;
33、搜索区域调整模块,根据跟踪结果的响应分数判断无人机搜索区域和地面搜索区域的质量,响应分数越高,搜索区域质量越好,反之越差,采用质量较好的搜索区域以及预测出来的偏移量,计算另一个视角搜索区域调整后的位置;
34、输出模块,将两个视角的搜索区域送入多视角跟踪器,融合两个视角跟踪目标的信息,输出跟踪结果。
35、优选的,模型建立模块在跟踪某序列的第t帧时,模型会返回当前帧前k帧的两个视角的跟踪结果,将无人机视角下的跟踪结果集记录为xu=[ut-k;…;ut-2;ut-1],地面视图的跟踪结果集记录为xg=[gt-k;...;gt-2;gt-1],ut-i和gt-i表示跟踪状态,xu和xg∈rk×4,k和t均为大于1的自然数,i为1至1-k的自然数,对于每个跟踪视角的每一帧跟踪结果,跟踪器都会输出一个边界框b=[x,y,w,h]作为跟踪状态,(x,y)为边界框左上顶点的坐标,w为边界框的宽度,h为边界框的高度,计算两个视角跟踪结果中心点的坐标差记为偏移量序列。
36、优选的,所述两个视角跟踪结果中心点的坐标(xc,yc)的计算公式为:
37、xc=x+0.5×w
38、yc=y+0.5×h;
39、两个视角下的跟踪结果中心点序列x′u和x′g为:
40、x′u=[u′t-k;...;u′t-2;u′t-1]
41、x′g=[g′t-k;...;g′t-2;g′t-1];
42、其中,u′t-i和g′t-i都是1×2的坐标(xc,yc)t-i;
43、再将两个视角下的跟踪结果中心点序列x′u和x′g做差,得到偏移量序列记为xoff=x′u-x′g=[xt-k;...;xt-2;xt-1]=[(δxt-k,δyt-k);...;(δxt-2,δyt-2);(δxt-1,δyt-1)],xoff∈rk×2。
44、优选的,偏移量预测模块预测出当前帧的目标偏移量的方法包括:
45、s31、将偏移量序列输入到变换器编码器,通过concat操作进行前k帧偏移量聚合,input embedding将特征映射到更高维空间,然后与位置编码postional emcoding相加,送入n层堆叠式编码器;
46、s32、n层堆叠式编码器通过编码器里的多头自注意力、残差连接、层归一化以及前馈网络进行特征编码;
47、s33、将编码后的特征输入编码送入n层堆叠式解码器中,解码器输入二维xdec,xdec值设为(0,0),解码器的输入xdec通过自注意力计算后,与特征输入编码进行交叉注意力计算,得出预测的当前帧偏移量(δx,δy)。
48、本发明提供的的优点在于:
49、1.本发明的跟踪方法引入了两个视角间的偏移量这一几何关系,也就是跟踪结果的坐标差,保证搜索区域尽可能包含跟踪目标,对于定位到质量更好,更易于包含跟踪目标的搜索区效果更好。用质量高的搜索区域的位置以及偏移量来确定更改后的原始低质量搜索区域的位置。由于质量好的搜索区域更容易包含目标,通过偏移量更改后的另一个搜索区域也更容易包含跟踪目标,从而将不同视角下同一目标的信息进行有效地融合,以实现两个视角跟踪性能的提升。
50、2.本发明的搜索区域调整策略得到的搜索区域相比于原始策略,本发明搜索区域跟踪目标基本都处于搜索区域的中心位置,且包含目标,跟踪结果和实际跟踪目标位置基本重合,总是包含跟踪目标,跟踪效果好,减少丢失目标的情况。
- 还没有人留言评论。精彩留言会获得点赞!