一种基于多源数据驱动的设备健康分析方法与流程
本发明涉及智能设备健康监测与故障预测领域,具体为一种基于多源数据驱动的设备健康分析方法。
背景技术:
1、工业设备的性能会随服役时间的增长而慢慢衰退,有效地评估与预测设备的健康状态对于故障的预防以及提高设备可靠性都具有重要意义,而现如今对智能工业设备的维护保养主要是在以下几个方面:
2、1、设备健康管理
3、传统的设备健康管理主要依靠人工经验判断和规则建模,但这些方法存在经验不可重用、规则难以覆盖设备整个生命周期的限制;
4、2、设备运行数据采集
5、各类设备在运行过程中可以采集不同类型的数据,如振动、声音、温度、电流等运行参数,以及事件日志、报警信息等,但是传统系统一般只集中在某一种类型的数据;
6、3、数据驱动的设备健康分析
7、数据驱动分析利用机器学习等算法,从设备的多源异构数据中提取知识,建立健康评估与故障预测模型,实现更智能和全面的设备健康管理;但现有技术主要基于单一数据源,不同数据源整合运用不足;
8、4、在线健康监测与预警
9、实现设备的持续在线健康监测与预警,可以大幅提升维护的及时性和效率,降低突发故障造成的损失,但针对多源数据的在线集成分析仍面临技术挑战;
10、从而不难发现在工业领域常用的设备健康评估方法过于依赖专家的经验,而在实际的生产过程中,只了解设备当前的状态并不能对设备进行全面的评估,往后的时间中设备的性能还是无法了解,从而不能对工业设备进行正确的提前维护,容易出现生产事故,制约了企业高效、高质、低成本的生产,也远远滞后企业实现智能制造的需求的问题。
技术实现思路
1、本发明的目的在于提供一种基于多源数据驱动的设备健康分析方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于多源数据驱动的设备健康分析方法,包括以下步骤:
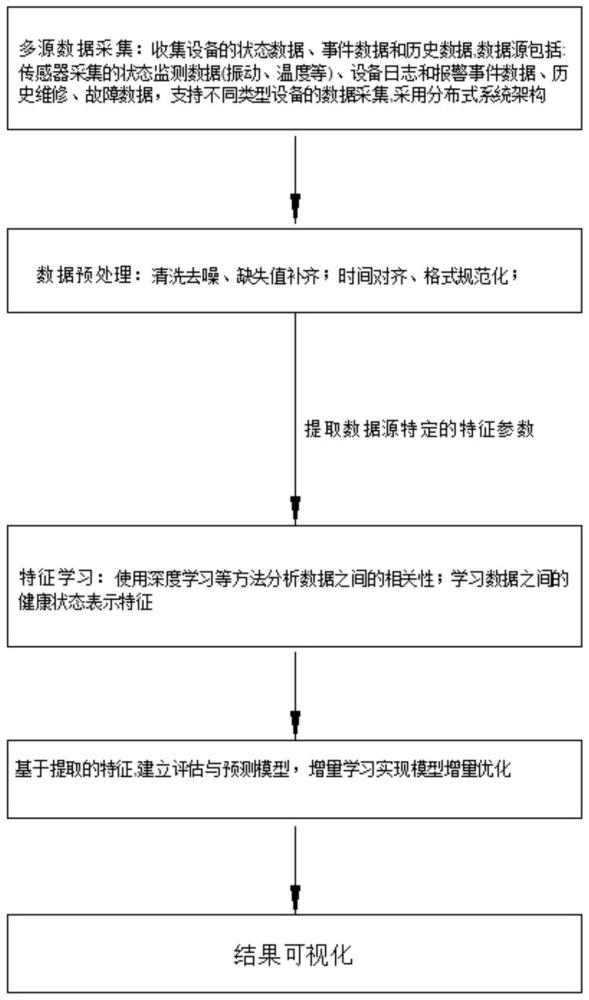
3、步骤一:多源数据采集,采集不同类型设备的数据,收集设备的状态数据、事件数据和历史数据,数据源包括传感器采集的状态监测数据、设备日志和报警事件数据、历史维修、故障数据;
4、步骤二:数据预处理,对采集的数据进行清洗去噪,补齐缺失值,时间对齐、格式规范化;
5、步骤三:数据提取,提取数据源中特定的特征参数,所述数据源包括:设备状态监测的时间序列数据,包含传感器采集的温度、压力、流量、震动等;
6、步骤四:特征学习,分析数据之间的相关性,学习数据之间的健康状态表示特征;
7、步骤五:健康评估与预测,基于提取的特征,建立评估与预测模型同时增量学习对模型进行增量优化;
8、步骤六:结果可视化,基于提取特征,构建评估与预测模型,展示健康状态评估结果;对运行设备进行实时监测与风险预警,提供预警信息、维护建议;以可视化方式展示设备健康监测结果,不同角色的用户访问控制。
9、作为优选,所述步骤二中补齐缺失值包括以下方法:
10、传感器误报导致的随机缺失采用统计值填充补齐,可以是均值、中值与众数;
11、设备故障导致的一段时间序列数据缺失采用插值法或者相邻平均法填充补齐,其中插值法包括线性插值与样条插值;
12、网络中断导致的数据传输缺失采用复制相似装置的数据进行填充补齐。
13、作为优选,所述步骤三中特征提取方法包括以下步骤:
14、s1:从时间序列数据中提取统计特征、频域特征与时间域特征,其中特征提取采用滑动窗口机制,每隔一段时间计算一个窗口的特征;
15、s2:将提取的特征进行融合,形成全面的设备状态表示,应用主成分分析降维方法,获得代表整体状态的主要特征。
16、作为优选,所述步骤四中使用深度学习算法分析数据之间的相关性,其中编码器、解码器可用全连接网络结构,包括以下步骤:
17、p1:数据预处理:对输入数据进行归一化预处理;
18、p2:网络构建:构建包含编码器和解码器的神经网络,编码器逐步减小维数,降维提取特征,解码器逐步重构输入,对称地恢复维数;
19、p3:前向传播:输入数据x经过编码器得到低维表示z,再通过解码器得到重构数据x';
20、p4:损失函数:使用重构错误作为损失函数,函数表达式为:
21、l(x,x')≤(|x-x'|)^2;
22、p5:反向传播:通过损失函数反向传播优化编码器和解码器的参数;
23、p6:编码表示:分析最终的编码表示z的组分结构,判断不同输入维度的相关性;
24、p7:网络模型优化:改变网络结构、调整超参数以优化模型并提高相关性分析的效果。
25、作为优选,所述步骤五中建立评估与预测模型的方法包括以下步骤:
26、q1:特征选择,根据domain知识和特征重要性分析,根据模型目标和输入要求,选择与设备健康评估相关的主要特征的子集作为模型输入;
27、q2:数据标注,依据设备历史失败维修数据,给样本数据打上健康状态的标注;
28、q3:模型选择,选择匹配问题的模型,其中包括回归模型:预测连续健康指数、分类模型:预测故障模型、阀门算法模型与液位算法模型;
29、q4:训练验证,将数据分为训练集和验证集,拟合模型参数,评估不同模型的效果;
30、q5:模型优化,改进模型结构,调参优化,提高评估与预测的准确率,同时增量学习实现模型增量优化;
31、q6:在线部署,选择最优模型在云平台上部署,实现对实时设备数据的评估与故障预测;
32、q7:模型迭代,通过持续反馈设备运行数据,进行模型增量学习训练实现模型增量优化。
33、作为优选,所述模型优化中使用随机森林算法获取更优的预测性能进行模型优化,包括以下步骤:
34、m1:从原始训练集中通过有放回的方式抽取多个子样本;
35、m2:对每个子样本训练一棵决策树模型,训练时,在选取特征切分节点时增加随机性,每次从部分特征中随机抽取进行评估;
36、m3:测试样本经过每个决策树模型后,得到多个分类或回归结果;
37、m4:对测试样本进行投票或取平均,得到随机森林模型的最终分类或回归结果;
38、m5:通过调整数量参数,进行控制模型性能,其中数量参数包括决策树数量与特征子集大小。
39、作为优选,所述液位算法模型的训练验证方法包括以下步骤:
40、r1:通过仪表采集液位数值,记为a,并将数据保存到工业互联网系统中;
41、r2:从工业互联网系统中获取dcs采集的数值,记为b;
42、r3:判断a和b的数值是否在正常范围,如果超出正常范围进行告警;
43、r4:比较a与b的相对偏差,记为c,判断c是否超出允许偏差,如果超出进行告警;
44、r5:同理再获取液位算法模型中的时序数据与仪表数据进行对比;
45、r6:展示结果,如果有异常则进行推送。
46、作为优选,所述液位算法模型中的时序数据包括以时间和液位高度构建时序序列,按时间次序拟合成连续的曲线,进行观测液位的变化阈值通过时序序列间的相似性进行聚类分析;
47、时序序列:设全体液位时序序列t,t={t1,t2,t3,…,ti,…,tj,…,tn},t是液位总体变化,在数据t中,如果0<i<j≤n,则称ti先于tj发生,称ti与ti+1为相邻的;
48、时序序列间的相似性度量:采用动态时间扭曲距离方法计算时序序列间的相似度:给定的2个时序序列t中的子序列:s={s1,s2,...,si,sm}、q={q1,q2,...,qj,...,qn},其相似性计算如下,构造m*n的矩阵a,矩阵a中的每个元素为aij=dis(si,qj),在矩阵a中搜寻扭曲路径,其中起点p1=a11,终点pk=amn,对ph=aij,ph-1=axy,必须满足连续性和单调性约束:i-x≥0;0≤j-y≤1,序列中某2个时间点之间的距离:
49、dis(i,j)=min{dis(i-1,j-1),dis(i,j-1),dis(i-1,j)}将满足条件的i、j作为路径值添加到规整路径p中,根据规整路径:p=(p1,p2,...,ph,...,pk),将每个时间点上的距离求和作为2个时间序列之间的相似值sim(s,q)。
50、作为优选,所述聚类分析方法中采用自底向上的层次聚类算法将层叠线性分段输出的子序列集中的每个序列看作一个初始聚类簇,然后按照簇间距离找出最近的2个类簇进行合并,不断重复该过程,直至达到预设的想查看的聚类簇个数;
51、所述簇间距离为不同簇的所有子序列间的扭曲距离的平均值,平均距离及计算公式为:
52、对所述时序序列t分类集合中的子序列t′的聚类过程如下:
53、输入t的模式集合t′={s1,s2,…,sm},目标查看簇数目k;
54、初始化原始簇c,对时间序列t分类集合t′中的每个子序列sj,都作为原始簇:cj={sj};
55、对原始簇c中的每个簇两两计算相似度,得到子序列相似度矩阵m:m(i,j)=dtw(ci,cj);m(j,i)=m(i,j);
56、设置当前聚类簇个数:q=m;
57、在当前簇个数大于要聚类的个数时:q>k;
58、a)在簇相似矩阵m中找出距离最近的2个聚类簇ci*和cj*;
59、b)将簇ci*和cj*合并成新的簇:ci*=ci*∪cj*;
60、c)对相似度矩阵中的簇更新编号:
61、for i=j*+1,j*+2,...,q;do
62、将聚类簇cj重新编号为cj-1;
63、d)删除相似度矩阵m中的第j*行与第j*列;
64、e)计算更新后的簇ci*与其它簇的相似度,更新相似度矩阵m:
65、最后输出进行模式的划分。
66、作为优选,所述步骤一中多源数据采集采用分布式系统架构,在对数据源管理中采用主数据源和从数据源的架构,数据源之间采用主-从、主-主集群模式进行同步。
67、综上所述,本发明有益效果是:
68、1、本发明通过多源数据融合使故障预测准确率大大提高,比单一数据源更准确,从而避免了由于信息不全导致的误报和漏报。
69、2、深度学习提取特征使得监测维度提升巨大,状态检测更全面,避免了维度不足造成的监测盲区。
70、3、增量学习实现模型迭代,大大降低了预测误差,有效减少了离线训练无法快速响应新情况的局限性。
71、4、联机部署实现实时监测,使得故障预警时间提前了,从而能更早的进行预防,从而可以避免事故扩大,降低企业损失。
72、5、结果可视化使维护人员快速定位根因,从而能快速进行维护,维护效率大大提高了,大幅缩短了事故处理周期,为设备精准维护提供决策支持评估结果可指导设备保养和维修预测结果可用于维修资源规划,有助于降低维护成本,优化保养策略。
- 还没有人留言评论。精彩留言会获得点赞!