一种基于人工智能的智慧档案管理方法与流程
本发明涉及数字电子档案数据处理,具体涉及一种基于人工智能的智慧档案管理方法。
背景技术:
1、智慧档案管理指对于数字电子档案的管理方法,数字电子档案是以数字格式存储的文件和记录,通常以电子文档或电子数据的形式存在。传统的电子档案管理存储方法在数字化时代面临一些挑战,包括空间占用和长期保存的问题。在长期管理存储电子档案时,压缩文件可以节省宝贵的存储空间,降低存储成本,尤其在信息化时代背景下对于大规模的归档和数据保留策略。同时较好的压缩方法对于提高大规模档案的备份与传输效率有着深刻意义。
2、在现有技术中,利用游程编码对电子档案的文本数据进行压缩时有时会因为相邻文本数据的冗余程度较低导致压缩效率不高,而引入有损压缩可能会导致重要信息丢失,对精度要求比较高的档案进行储存时,无法同时做到在保留数据精度的同时提高游程编码的压缩效率。
技术实现思路
1、为了解决对精度要求比较高的档案进行储存时,无法同时做到在保留数据精度的同时提高游程编码的压缩效率的技术问题,本发明的目的在于提供一种基于人工智能的智慧档案管理方法,所采用的技术方案具体如下:
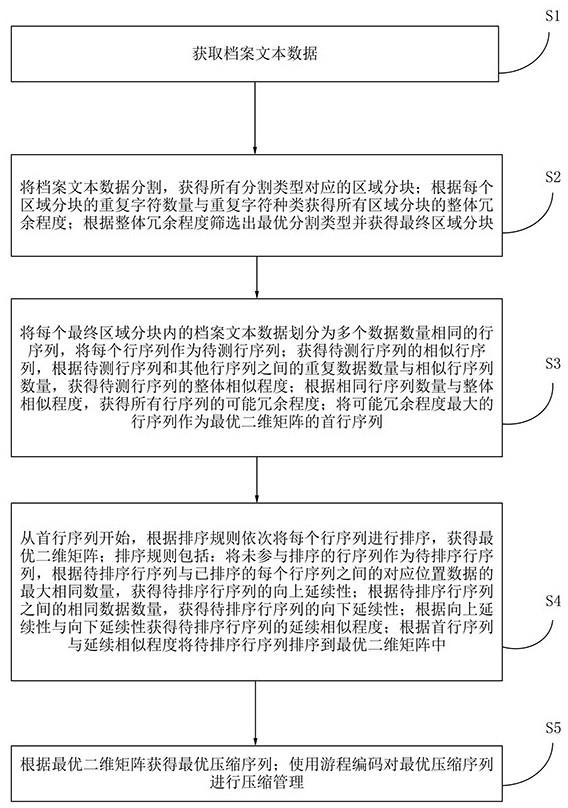
2、一种基于人工智能的智慧档案管理方法,该方法包括:
3、获取档案文本数据;
4、将所述档案文本数据分割,获得所有分割类型对应的区域分块;根据每个区域分块的重复字符数量与重复字符种类获得所有区域分块的整体冗余程度;根据所述整体冗余程度筛选出最优分割类型并获得最终区域分块;
5、将每个最终区域分块内的档案文本数据划分为多个数据数量相同的行序列,将每个行序列作为待测行序列;获得待测行序列的相似行序列,根据待测行序列和其他行序列之间的重复数据数量与相似行序列数量,获得待测行序列的整体相似程度;根据相同行序列数量与整体相似程度,获得所有行序列的可能冗余程度;将可能冗余程度最大的行序列作为最优二维矩阵的首行序列;
6、从所述首行序列开始,根据排序规则依次将每个行序列进行排序,获得最优二维矩阵;所述排序规则包括:将未参与排序的所述行序列作为待排序行序列,根据待排序行序列与已排序的每个行序列之间的对应位置数据的最大相同数量,获得所述待排序行序列的向上延续性;根据所述待排序行序列之间的相同数据数量,获得待排序行序列的向下延续性;根据所述向上延续性与所述向下延续性获得所述待排序行序列的延续相似程度;根据所述首行序列与所述延续相似程度将所述待排序行序列排序到所述最优二维矩阵中;
7、根据最优二维矩阵获得最优压缩序列;使用游程编码对所述最优压缩序列进行压缩管理。
8、进一步地,所述整体冗余程度的获取方法包括:
9、预设第一权值与第二权值分别对每个区域分块内的重复字符数量与重复字符种类进行加权;
10、将加权后的重复字符数量与加权后的重复字符种类的比值作为每个区域分块的区域冗余度;
11、将每个分割类型对应的所有区域分块内的所述区域冗余度求和,获得每个分割类型对应的所有区域分块内的整体冗余程度。
12、进一步地,所述最终区域分块获得方法包括:
13、将所述整体冗余程度最大的分割类型对应的每个区域分块作为最终区域分块。
14、进一步地,所述相似行序列获取方法包括:
15、若待测行序列与其余任意一个行序列之间存在相同数据,则将存在相同数据的行序列作为待测行序列的相似行序列。
16、进一步地,所述可能冗余程度的获取方法包括:
17、根据可能冗余程度计算公式获取所述可能冗余程度,所述可能冗余程度计算公式如下所示:
18、;式中,表示区域分块内待测行序列的可能冗余程度;表示待测行序列的相同行序列数量;表示行序列中数据的数量;表示相似行序列中与待测行序列中的重复数据数量;表示待测行序列的相似行序列数量。
19、进一步地,所述向上延续性获取方法包括:
20、获得待排序行序列与已排序的每个行序列对应位置数据的最大相同数量;
21、将已排序的每个行序列中每个数据所述最大相同数量的平方累加获得向上延续程度;将所述向上延续程度归一化获得待排序行序列的所述向上延续性。
22、进一步地,所述向下延续性的获取方法包括:
23、将行序列之间的相同数据数量作为行序列之间的相似程度;将已排序行序列中的最后一个行序列作为待对比行序列;将待排序序列作为第一递归序列,将与所述第一递归序列相似程度最高的未排序的行序列作为第二递归序列;在递归过程中,将每次递归过程的第一递归序列与第二递归序列之间的相似程度与前一次递归过程的递归结果的和值作为本次递归过程的递归结果,将第二递归序列更新为第一递归序列并重新选取第二递归序列开始下一次递归;在第一次递归过程中,以第一递归序列与待对比行序列之间的相似程度作为所述前一次递归过程的递归结果;直至所述第一递归序列与其他未排序的所有行序列之间不存在相同数据,终止递归,将最后一次递归过程的递归结果归一化,获得待排序序列的所述向下延续性。
24、进一步地,所述延续相似程度的获取方法包括:
25、根据延续相似程度计算公式获取所述延续相似程度,所述延续相似程度计算公式如下所示:
26、;式中,表示待排序行序列的延续相似程度;表示行序列中数据的数量;表示待排序行序列中第个数据与已排序的行序列对应位置数据的最大相同数量;表示终止递归时第一递归序列与第二递归序列之间的相似程度;表示进行递归操作终止时的递归结果;表示前一次递归过程的递归结果;表示待排序行序列的向上延续性;表示待排序行序列的向下延续性;表示待排序行序列的向上延续性的第三权值;表示待排序行序列的向下延续性的第四权值;表示归一化函数。
27、进一步地,所述最优二维矩阵的获取方法包括:
28、从二维矩阵的所述首行序列开始,依照待排序行序列的所述延续相似程度从大到小排列,依次插入到二维矩阵的下一行,遍历所有行序列,获得所述最优二维矩阵。
29、进一步地,最优压缩序列的获取方法包括:
30、采用纵向的方向对二维矩阵进行扫描,通过扫描得到冗余程度最高的压缩序列作为最优压缩序列。
31、本发明具有如下有益效果:
32、本发明首先将档案文本数据依据不同字符数量进行分割获得不同分割类型对应的区域分块;根据区域分块中重复字符数量与重复字符种类获得区域分块的区域冗余度;区域冗余度反映了每个区域分块的冗余程度,将所有区域分块的区域冗余度累加获得整体冗余程度,根据整体冗余程度可以得知此种分割类型对应的区域分块内字符的重复程度,进而得到所有最终区域分块;在每个最终区域分块上构建二维矩阵,根据行序列之间的相似性与重复性获得行序列的可能冗余程度,可能冗余程度反映出最终区域分块的所有字符中数据的重复程度,根据可能冗余程度选出二维矩阵中的首行序列,首行序列决定了后续对行序列进行排序时的整体冗余程度;由二维矩阵首行开始进行相似性数据遍历排序,通过待排序行序列向上的每个行序列之间的数据的最大相同数量获得待排序行序列的向上延续性,向上延续性越大,对应位置数据的连续性越高,冗余度就越大,根据待排序行序列之间的相同数据数量,获得待排序行序列的向下延续性,向下延续性越大,反映出待排序行序列之间的相似程度越大,根据向上延续性和向下延续性获得待排序行序列的延续相似程度,延续相似程度反映出待排序行序列与向上行序列的适配程度,通过延续相似程度可以对二维矩阵依次排序,获得最优二维矩阵,最优二维矩阵在纵向上具有高度的相邻相似性,冗余程度极高;获得最优二维矩阵对应的最优压缩序列,便于使用游程编码进行压缩,实现对电子档案的管理存储。本发明通过构建电子档案文本数据的最优二维矩阵,大大增加了电子档案文本数据的冗余程度,在使用游程编码进行压缩时,能够在保证电子档案数据精度的同时,大大减少了存储空间的占用,提高了游程编码的压缩效率。
- 还没有人留言评论。精彩留言会获得点赞!