用于质量缺陷类别识别模型的训练方法及装置与流程
本发明涉及装备检测,尤其涉及一种用于质量缺陷类别识别模型的训练方法及装置。
背景技术:
1、装备质量历来是生产制造领域重点关注的问题,生产过程中,大部分出厂件为正常样本,缺陷件少、占比低且种类不全。
2、在使用机器学习算法对装备质量问题识别时,受样本不均衡、负样本量少的影响,难以训练得到优良的智能算法模型,即使训练完成的模型,在实际应用时,效果也不尽人意。同时,现有技术中采用的模型结构在面对各种类别的特征指标时,无法注意到对质量缺陷识别影响较大的特征指标,即无法提取关键的特征,导致模型识别精确度低,不能很好的识别出真正的质量缺陷。
3、因此,为更好的对装备质量进行识别,亟需一种新的对装备质量的识别模型进行训练的方法。
技术实现思路
1、鉴于上述的分析,本发明实施例旨在提供一种用于质量缺陷类别识别模型的训练方法及装置,用以解决现有技术中识别模型识别不准确的问题。
2、一方面,本发明实施例提供了一种用于质量缺陷类别识别模型的训练方法,所述训练方法包括:
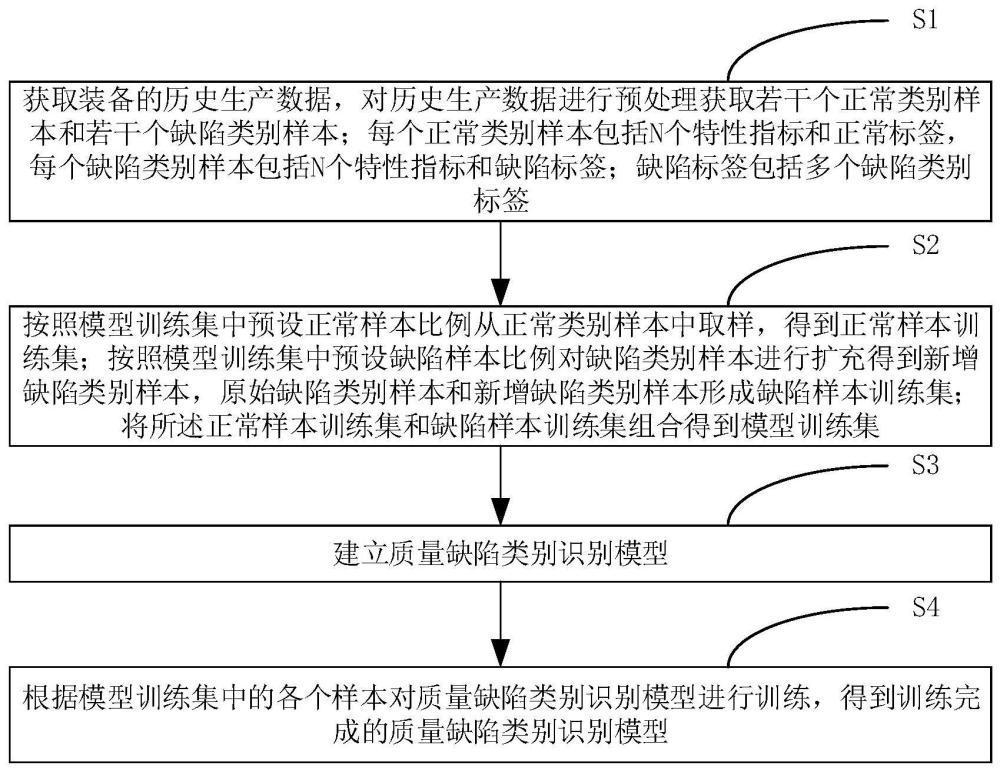
3、获取装备的历史生产数据,对历史生产数据进行预处理获取若干个正常类别样本和若干个缺陷类别样本;每个正常类别样本包括n个特性指标和正常标签,每个缺陷类别样本包括n个特性指标和缺陷标签;缺陷标签包括多个缺陷类别标签;
4、按照模型训练集中预设正常样本比例从正常类别样本中取样,得到正常样本训练集;按照模型训练集中预设缺陷样本比例对缺陷类别样本进行扩充得到新增缺陷类别样本,原始缺陷类别样本和新增缺陷类别样本形成缺陷样本训练集;将所述正常样本训练集和缺陷样本训练集组合得到模型训练集;
5、建立质量缺陷类别识别模型;
6、根据模型训练集中的各个样本对质量缺陷类别识别模型进行训练,得到训练完成的质量缺陷类别识别模型。
7、基于上述训练方法的进一步改进,所述质量缺陷类别识别模型包括依次连接的特征提取层和缺陷类别分类层;
8、特征提取层,用于接收模型训练集中的每个样本的n个特性指标,并对n个特性指标进行卷积计算,提取得到每个样本的特征;
9、缺陷类别分类层,用于接收每个样本的特征,并根据该样本的特征进行预测,得到该样本的缺陷类别。
10、基于上述训练方法的进一步改进,所述特征提取层包括多个依次连接的残差网络;
11、每个残差网络包括依次连接的第一残差模块和第二残差模块;
12、第一残差模块的主分支包括两个卷积层,残差分支上包括一个通道加权模块;
13、第二残差模块的主分支包括两个卷积层,残差分支上包括一个挤压激励模块。
14、基于上述训练方法的进一步改进,第一残差模块和第二残差模块中的卷积层均为3×3的卷积结构;通道加权模块包括依次连接的一维卷积、全连接层、softmax层和平均池化层。
15、基于上述训练方法的进一步改进,按照训练集中预设缺陷样本比例对缺陷类别样本进行扩充得到新增缺陷类别样本,包括:
16、按照下述步骤获取每一个新增缺陷类别样本:
17、依次按照n个特性指标的大小对缺陷类别样本进行排序,得到n个特性指标对应的缺陷类别样本序列;
18、随机从缺陷类别样本中确定一个参考缺陷样本,确定该参考缺陷样本在n个特性指标对应的缺陷类别样本序列中的取样位置,共得到n个取样位置;
19、根据该n个取样位置,分别确定该新增缺陷类别样本对应的n个特性指标,参考缺陷样本的缺陷标签作为该新增缺陷类别样本的缺陷标签。
20、基于上述训练方法的进一步改进,所述根据该n个取样位置,分别确定该新增缺陷类别样本对应的n个特性指标,包括:
21、按照下述步骤获取该新增缺陷类别样本应的n个特性指标中任意一个特性指标:
22、根据该特性指标的取样位置,在该特性指标对应的缺陷类别样本序列中确定取样位置的前一个位置和后一个位置缺陷类别样本的缺陷类别标签;
23、比较该取样位置的缺陷类别标签和后一个位置的缺陷类别标签是否相同;如果相同,根据该取样位置处缺陷类别样本中的该特性指标和后一个位置处缺陷类别样本中的该特性指标生成该新增缺陷类别样本对应的该特性指标;如果不相同,再比较该取样位置的缺陷类别标签和前一个位置的缺陷类别标签是否相同;
24、如果该取样位置的缺陷类别标签和前一个位置的缺陷类别标签相同,则根据该取样位置处缺陷类别样本中的该特性指标和前一个位置处缺陷类别样本中的该特性指标生成该新增缺陷类别样本对应的该特性指标;否则,将该取样位置处缺陷类别样本中的该特性指标作为该新增缺陷类别样本对应的该特性指标。
25、基于上述训练方法的进一步改进,如果该取样位置的缺陷类别标签和后一个位置的缺陷类别标签相同,通过下述公式计算该新增缺陷类别样本对应的该特性指标:
26、
27、其中,表示第r个新增缺陷类别样本的第n个特性指标,表示第l个取样位置对应的缺陷类别样本中第n个特性指标,表示第l+1个位置对应的缺陷类别样本中第n个特性指标,δ为(0,1)范围的随机数;
28、如果该取样位置的缺陷类别标签和前一个位置的缺陷类别标签相同,通过下述公式计算该新增缺陷类别样本对应的该特性指标:
29、
30、其中,表示第l-1个取样位置的第n个特性指标的大小。
31、基于上述训练方法的进一步改进,所述按照模型训练集中预设正常样本比例从正常类别样本中取样,包括:
32、根据模型训练集的预设总样本和预设正常样本比例确定正常样本数量;
33、利用不放回取样方法,随机从正常类别样本中取出正常样本数量的正常训练样本。
34、基于上述训练方法的进一步改进,所述利用不放回取样方法,随机从正常类别样本中取出正常样本数量的正常训练样本,包括:
35、按照n个特性指标中任意一个指标的大小对正常类别样本进行排序,得到排序后的正常类别样本;
36、产生一个(0,1)范围内的随机数,根据该随机数和排序后的正常类别样本的数量确定取样位置;
37、将该取样位置对应的正常样本取出,作为正常样本训练集中的一个正常训练样本,同时将该取样位置对应的正常样本从排序后的正常类别样本中删除,对正常类别样本进行更新;
38、判断采样得到的正常训练样本的数量是否达到正常样本数量;如果没达到正常样本数量,则重复上述步骤进行下一次采样;否则,结束正常训练样本的采样。
39、另一方面,本发明实施例提供了一种用于质量缺陷类别识别模型的训练装置,所述训练装置包括:
40、样本获取模块,用于获取装备的历史生产数据,对历史生产数据进行预处理获取若干个正常类别样本和若干个缺陷类别样本;每个正常类别样本包括n个特性指标和正常标签,每个缺陷类别样本包括n个特性指标和缺陷标签;缺陷标签包括多个缺陷类别标签;
41、训练集采样模块,用于按照模型训练集中预设正常样本比例从正常类别样本中取样,得到正常样本训练集;按照模型训练集中预设缺陷样本比例对缺陷类别样本进行扩充得到新增缺陷类别样本,原始缺陷类别样本和新增缺陷类别样本形成缺陷样本训练集;将所述正常样本训练集和缺陷样本训练集组合得到模型训练集;
42、模型建立模块,用于建立质量缺陷类别识别模型;
43、模型训练模块,用于根据模型训练集中的各个样本对质量缺陷类别识别模型进行训练,得到训练完成的质量缺陷类别识别模型。
44、与现有技术相比,本发明至少可实现如下有益效果之一:
45、1、通过对缺陷类别样本进行扩充得到新增缺陷类别样本,原始缺陷类别样本和新增缺陷类别样本形成缺陷样本训练集,扩大了样本多样性,以覆盖更多的数据潜在分布,从而提高对不同特征指标的泛化能力。使得训练完成的质量缺陷类别识别模型在对装备进行识别时,准确度更高;
46、2、通过在质量缺陷类别识别模型的结构中增设通道加权模块和挤压激励模块,使得模型能够关注到样本不同通道以及卷积核不同通道的特征指标的特征,加大对质量缺陷影响较大的通道的权重,能够提取到更加精准的特征,最终提高了模型识别准确度。
47、本发明中,上述各技术方案之间还可以相互组合,以实现更多的优选组合方案。本发明的其他特征和优点将在随后的说明书中阐述,并且,部分优点可从说明书中变得显而易见,或者通过实施本发明而了解。本发明的目的和其他优点可通过说明书以及附图中所特别指出的内容中来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!