一种基于FPGA和量化蒸馏的图像分类异构硬件加速方法
本发明涉及目标分类,尤其是一种基于fpga和量化蒸馏的异构硬件加速器。
背景技术:
1、在过去几年内,见证了深度神经网络在分类领域的快速发展,特别是已经在广泛的分类和回归任务上实现了新的当前最佳表现。但典型的深度模型依然很难部署在资源受限的设备上,例如移动电话或嵌入式设备。资源受限的场景意味着计算任务必须在有限的资源供应下完成,例如计算时间、存储空间、电池电量等。深度神经网络的主要问题之一是其巨大的计算成本和存储开销,这对移动设备构成了严重的挑战。在这种情况下,如果可以将深度神经网络部署到边缘设备,甚至可以在边缘设备上进行训练推理,对比上述就有明显的优势。预先对数据进行本地处理,消除了将数据来回发送到云的延迟和网络流量负载。边缘计算还通过消除与云之间的数据传输来减少安全问题。目前最先进的深度神经网络往往是以fp32数据进行计算,过度参数化的,因此,在深度学习模型中改变数据类型,去除冗余参数,如果执行得当,将产生与原始模型相似的总体精度。从长远来看,在边缘部署深度神经网络比云计算更具成本效益:深度神经网络的专用边缘设备,在大规模制造时,比云服务器便宜得多。因此,将神经网络部署到边缘设备并进行推理加速具有重大的研究意义。
2、当前常见的硬件加速方式有三种:
3、一是基于快速傅里叶变换加速卷积,优化网络的加速器,此方法依托于矩阵中有固定的特征向量,因而可以稳定地对角化,从而将矩阵乘法转换为乘对角阵,这样去除了多余的计算。但是该方法更适用于卷积核较大的情况,对于dsc里的小卷积核不适用,反而会增加不必要的运算时间。
4、二是基于不同的数据类型来优化模型,选择混合精度16位浮点数、脑浮点数、8位、4位定点数以及二值化,利用不同位宽的数据来减少计算所需参数量,但是单纯的量化网络和权重使得精度下降是一个严重的问题。
5、三是基于神经网络架构搜索(nas)的方式对模型进行剪枝和稀疏度设计,包括网格搜索、随机搜索和遗传算法等蛮力算法;以及彩票假说、大量索引跳过0权重。但是nas在计算上成本很昂贵,每个场景都必须重复模型搜索和训练。
6、四是对比其他fpga加速方法,例如一种bert中层归一化非线性函数的fpga加速方法,该专利只通过基本的量化模式对自然语言处理的网络模型的层归一化进行了处理,缺陷在于:1.没有考虑多层量化处理,对于不同的网络模型有较大局限性;2.没有通过稀疏权重和激活矩阵来减少需要计算的参数和操作数;3.没有考虑数据重用问题,导致数据串行使用,降低了计算效率;4.没有设计专门的fpga硬件加速器来执行bert中的关键操作;5.没有考虑到卷积中数据累加后存在数据溢出问题。
7、基于上述方法存在的不足,有必要研发一种基于fpga和量化蒸馏的异构硬件加速器。
8、本发明针对上述所提出的问题,提出了一种基于fpga和量化蒸馏的图像分类异构硬件加速方法,优势包括:1.提出一种架构,在fpga上使用winograd算法高效实现小卷积核的卷积神经网络,并减少部分参数量;2.针对fpga选择了对称、整数、线性和逐通道的整体量化策略,比单一的int8定点量化精度下降更少,更适用于部署在嵌入式硬件上;3.通过网络压缩和稀疏权重设计,严格分配常规卷积和廉价卷积的通道数,减少了需要计算的参数和操作数;4.设计的加速方法考虑了层融合,对卷积层、池化层、归一层、全连接层都进行了量化处理,包括其他包含深度可分离卷积层的网络模型都可以采用此类方法进行处理,大大减少了局限性;5.设计了输入特征复用、数据缓存复用的并行通道,大量减少了读取和写入数据需要的时间,提高计算效率;6.考虑了在fpga中,数据移位累加后的溢出问题,对移位数据进行尺度空间范围内的截断操作,简化后整个计算只剩下int8类型乘法,32bits加法和移位与截断操作,非常适合fpga硬件电路的运算。
技术实现思路
1、本发明旨在解决以上现有技术的问题。提出了一种将传统目标分类方法中的网络结构和分类算法做便于部署的轻量型优化,同时移植到fpga+arm的边缘嵌入式设备中,在不影响分类精度的同时实现了目标分类硬件加速,并有效减少了使用成本,提高计算效率的基于fpga和量化蒸馏的图像分类异构硬件加速方法。本发明的技术方案如下:
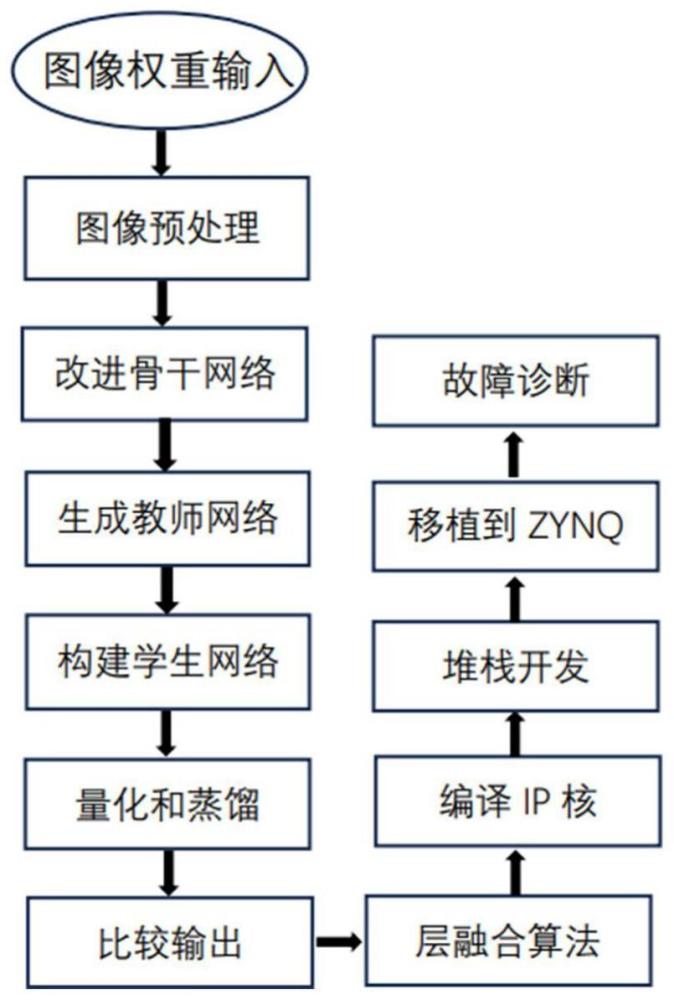
2、一种基于fpga和量化蒸馏的图像分类异构硬件加速方法,其包括以下步骤:
3、步骤1,获取图像数据集样本,采集所需分类图像特征信息,制作目标训练集和测试集;
4、步骤2,对骨干网络ghostnetv2网络模型进行改进,包括增加注意力分支模块,增强扩展的特征;网络压缩,减少冗余的1x1卷积层,减少堆叠的倒残差模块;量化减少参数量和计算量,得到教师网络;
5、步骤3,利用步骤s1中获取的数据集对步骤2中改进后的教师网络模型结构进行训练,迭代得到轻量型量化教师网络模型;
6、步骤4,构建基于深度可分离卷积dsc的特征分类学生网络;
7、步骤5,训练学生网络模型及输出,对步骤4中得到的学生网络模型进行微调优化;
8、步骤6,利用步骤s1中获取的训练样本对步骤5中构建的轻量型学生网络模型结构进行训练,迭代得到轻量型网络模型;
9、步骤7,对步骤6得到的轻量型网络模型进行误差分析和优化;
10、步骤8,将步骤3得到的教师网络模型与步骤7得到lsynet1网络模型进行知识蒸馏;
11、步骤9,由步骤8中得到的网络模型编译实现ip核;
12、步骤10,将步骤9编译好的模型部署到边缘设备,输入权重,与主机连接搭建异构平台;
13、步骤11,故障诊断,利用步骤10部署到边缘设备上的网络模型对步骤1中的图像数据集进行分类识别,实现异构平台上的硬件加速。
14、进一步的,所述步骤2具体包括:
15、对主干网络进行层和通道同步剪枝,压缩模型的宽度和大小;通道剪枝是基于减少3x3卷积输入通道数量进行剪枝,先以全局阈值找出各卷积层的参数量,然后对于每组3x3卷积,将相连的部分卷积层做下采样,对每一个相关层都做严格的分割,控制常规卷积和廉价卷积在输出特征图中的比例,同时对每一个层的保留通道做了限制,对激活偏移值进行微调;层剪枝是在通道剪枝的策略基础上进行进一步剪枝,针对每一个dsc层进行评价,对每一层的参数进行排序,取最小的进行层剪枝。
16、进一步的,所述步骤4构建基于深度可分离卷积dsc的特征分类学生网络,具体包括:
17、关键目标识别采用构建的基于dsc的轻量级网络,通过winograd快速矩阵乘法算法,保留通过在空间域中对卷积层进行剪枝得到的稀疏性,实现卷积加速;采用了目标检测融合算法,将bn层参数和卷积层参数融合,实现算子折叠。。
18、进一步的,所述步骤5中,量化采用ppq进行开发,通过量化工具ppq将float32模型转换为int8模型,从而使训练得到的网络模型能够在fpga上部署进行加速运算,量化方式如下:
19、对主干网络整体进行量化处理,通过减少表示每个权重所需的比特数来压缩原始网络,数据格式为8-bit定点数;量化方式采取对称+线性+整数+逐通道,改进后的量化公式如下:
20、en+1=(en⊙wn+fn2bn-an-wn)2an+wn-an+1
21、其中☉为卷积操作,en是第n层卷积的输入特征图,en+1是第n层卷积的输出特征图,wn是第n层卷积的卷积核权重,fn是第n层卷积的偏置,sx是量化尺度因子,为了不失一般性,将偏置和int8卷积放在一起,将上述量化尺度因子转换为指数运算,an是第n个输入的比特位,而bn是第n个输出的比特位。
22、进一步的,所述步骤8,将步骤3得到的教师网络模型与步骤7得到lsynet1轻量型网络模型进行知识蒸馏,具体包括:
23、准备数据集,需要准备用于训练和知识蒸馏的数据集,包括训练集和验证集。确保数据集与任务相关,并且用于教师和学生网络的训练;
24、定义教师网络和学生网络,训练教师网络的目的是为了获得一个强大的基准模型,该模型将在后续步骤中传授知识给学生网络;定义lsynet1为学生网络架构,该网络将接受来自教师网络的知识;
25、定义蒸馏损失,在知识蒸馏中一般使用两个损失训练学生网络:硬目标损失:是学生网络的标准交叉熵损失,使用原始的标签数据来计算损失;软目标损失,基于教师网络的输出概率分布和学生网络的输出概率分布之间的差异。一种常见的方法是使用温度调节的softmax函数来计算软目标损失。该损失鼓励学生网络的输出与教师网络的输出保持一致,使学生网络能够学到更多的信息;
26、定义超参数,在知识蒸馏中需要定义温度调节函数、教师网络的输出和学生网络的输出以及温度参数;
27、训练和评估学生网络,使用数据集来训练学生网络,同时最小化原始损失和蒸馏损失。一旦学生网络训练完成,应该评估其性能,以确保它在任务上表现良好。
28、进一步的,所述步骤9由步骤8中得到的网络模型编译实现ip核,具体包括:
29、对网络采用硬件友好型编译方式:在硬件逻辑上,对于2的指数运算,简化为移位操作;对于偏置数据fn的处理方式:经过左移位β至相同尺度,然后和卷积的结果进行累加,考虑不同层中的特征图数据的量化尺度en和en+1,对应累加后数据的右移α位操作,考虑到累加后数据存在溢出的情况,针对移位数据进行尺度空间范围内的截断操作;
30、所述步骤9中,所述编译和实现是指对于量化和蒸馏后生成的模型,还需要将其转换为目标设备能够运行的rtl格式,这个过程采用xillinx hls开发,将模型以及连接通信方式编译为不同的ip核,利用c/rtl协同模拟生成对应该边缘设备的异构优化代码;
31、进一步的,步骤10中,所述部署到边缘设备是将权重文件、图像文件以及量化后的模型文件移植到dram上,连接板卡,采用xilinx viaits堆栈开发,在xilinx viaits中实现navida gpu提取特征,fpga做后端提取特征的异构平台硬件加速器。
32、进一步的,所述步骤10中部署到边缘设备上是通过axi总线通信协议;ddr3高速接口;dma ip协议来对处理器系统部分(processing system,简称ps)和可编程逻辑部分(programmable logic简称pl)进行通信连接;使用axi4总线协议与ps通信,当ps需要加速一个神经网络时,它控制pl端的加速器对神经网络进行推理和训练;ps对特征图和权重数据进行格式转换和数据预处理;所有的特征图和权值都存储在ps端的ddr4中,等待pl获取这些数据。
33、进一步的,所述步骤10中,hls中使用了4个axi interconnect ip处理从内存读取和写入操作;采用一个axi智能连接ip,使用一个axi端口进行如下操作:1)写入数据采集块,2)从分类判定块读取分类结果;zynq处理系统ip核是该设计的主要模块,使用处理器系统复位ip来驱动具有公共时钟和复位信号的所有模块;一旦数据采集块接收到训练样本,conv hls ip就首先开始运行;在lsynet中,内存容量分为三个主要块来存储不同的数据类型。
34、进一步的,所述步骤10中,权重bram负责存储缓冲区和误差/增量计算所需的权重值。输入bram负责存储来自外部存储器的输入特征和fc层的节点结果,也用于存储执行权重更新时的权重梯度,还有输出bram。
35、本发明的优点及有益效果如下:
36、1、本发明采用了fpga+gpu异构硬件加速轻量化神经网络的方法,提高了部署到边缘设备上的目标分类设备的效率,同时降低了成本;通过缩小网络模型,改进数据格式,分类和诊断算法的运行速度变快,确保了在实际非理想条件场景中,能够满足准确性与实时性的要求。
37、2、本发明的目标分类主干部分采用了ghostnetv2网络,通过步骤2中的网络压缩和量化,包括增加注意力分支模块,增强扩展的特征;网络压缩,减少冗余的1x1卷积层,减少堆叠的倒残差模块;量化减少参数量和计算量,通过稀疏权重设计,严格分配常规卷积和廉价卷积的通道数,减少了需要计算的参数和操作数;实现了便于部署的改进型轻量化教师网络。
38、3、本发明的目标分类算法部分采用了winograd快速卷积算法,在步骤6中通过减少乘法数量结合适用于硬件的计算方式实现目标分类;采用的基于dsc的轻量型结构、算子折叠的融合算法、并对教师网络和学生网络同时进行量化和知识蒸馏,优势在于减少运算参数的情况下使精度下降不明显。相比于其他目标分类算法,具有极简极精的特点,使其对边缘硬件设备要求不高;在步骤10中能够通过量化和vitisai堆栈开发的方法实现arm+fpga的异构硬件加速,能够更便携的应用于目标分类。
39、4、本发明量化技术点部分在于步骤3和步骤6中,针对fpga选择了对称、整数、线性和逐通道的整体量化策略,优点是比单一的int8定点量化精度下降更少,更适用于部署在嵌入式硬件上;优势还包括设计的加速方法考虑了层融合,对卷积层、池化层、归一层、全连接层都进行了量化处理,包括其他包含深度可分离卷积层的网络模型都可以采用此类方法进行处理,大大减少了局限性。
40、5、本发明编译和硬件部署的技术点在于步骤9中设计了输入特征复用、数据缓存复用的并行通道,优点是大量减少了读取和写入数据需要的时间,提高计算效率;还在技术上考虑了在fpga中,数据移位累加后的溢出问题,对移位数据进行尺度空间范围内的截断操作,简化后整个计算只剩下int8类型乘法,32bits加法和移位与截断操作,非常适合fpga硬件电路的运算。
41、6、本发明的硬件部分选择了xilinx公司的板卡zynq7020,在步骤11中通过在vitis hls上c/rtl联合模拟,能够通过并行处理的方式快速的获取结果,便捷的实现软硬件协同开发以及量化编译移植实现算法边缘嵌入式部署。
42、7、本发明通过优化、移植,不仅提升了精确度与实时性,还降低了实际应用中对边缘硬件的要求,保证能够在低成本、轻型化的条件下很好的完成了实际应用中目标分类任务。
- 还没有人留言评论。精彩留言会获得点赞!