基于深度学习的人体姿态行为检测方法、系统和存储介质与流程
所属的技术人员知道,本发明可以实现为系统、方法或计算机程序产品,因此,本发明可以具体实现为以下形式,即:可以是完全的硬件、也可以是完全的软件(包括固件、驻留软件、微代码等),还可以是硬件和软件结合的形式,本文一般称为“电路”、“模块”或“系统”。此外,在一些实施例中,本发明还可以实现为在一个或多个计算机可读介质中的计算机程序产品的形式,该计算机可读介质中包含计算机可读的程序代码。可以采用一个或多个计算机可读的介质的任意组合。计算机可读介质可以是计算机可读信号介质或者计算机可读存储介质。计算机可读存储介质例如可以是一一但不限于——电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。计算机可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式计算机磁盘、硬盘、随机存取存储器(ram),只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑磁盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。在本发明中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
背景技术:
1、目前在许多领域,譬如安防领域、游戏领域等,需要对人们的人体姿态做出及时的检测和处理。利用传统的人工方法检测人体姿态不仅耗费大量的人力物力,而且会出现一些异常行为被漏检的情况。随着计算机视觉和人工智能技术的快速发展,人们开始基于视频数据,采用人工智能方法进行人体姿态检测。
2、人体姿态检测方法可分为有监督、弱监督、无监督三类。无监督方法缺少人工标记,泛化能力极弱,如何增强无监督方法的泛化能力也是近几年学术研究的热点。弱监督方法大多采用基于重构判断的方法进行判定,容易造成误判。有监督方法将人体姿态检测视为二分类或多分类问题,用详细标记的正异常行为样本训练神经网络,提取正异常之间更具区分性的特征。有监督方法的识别和定位精度普遍较高,在现实生活中被广泛使用。
3、在实现本公开的过程中,发明人发现现有技术存在以下问题:由于视频影像监控存在人目标遮挡、视角变化等复杂动态干扰,对人体姿态检测和可靠辨识带来困难。仅依赖目前表现较好的有监督方法难以适应复杂动态的人体姿态监测场景。因此,如何克服动态场景中人被遮挡、监控摄像视角变化的挑战,摆脱算法误差、环境干扰带来的辨识干扰,是诸多现实场景下对人体姿态进行检测与辨识亟待解决的问题。
技术实现思路
1、本发明所要解决的技术问题是针对现有技术的不足,具体提供了一种基于深度学习的人体姿态行为检测方法、系统和存储介质,具体如下:
2、1)第一方面,本发明提供一种基于深度学习的人体姿态行为检测方法,具体技术方案如下:
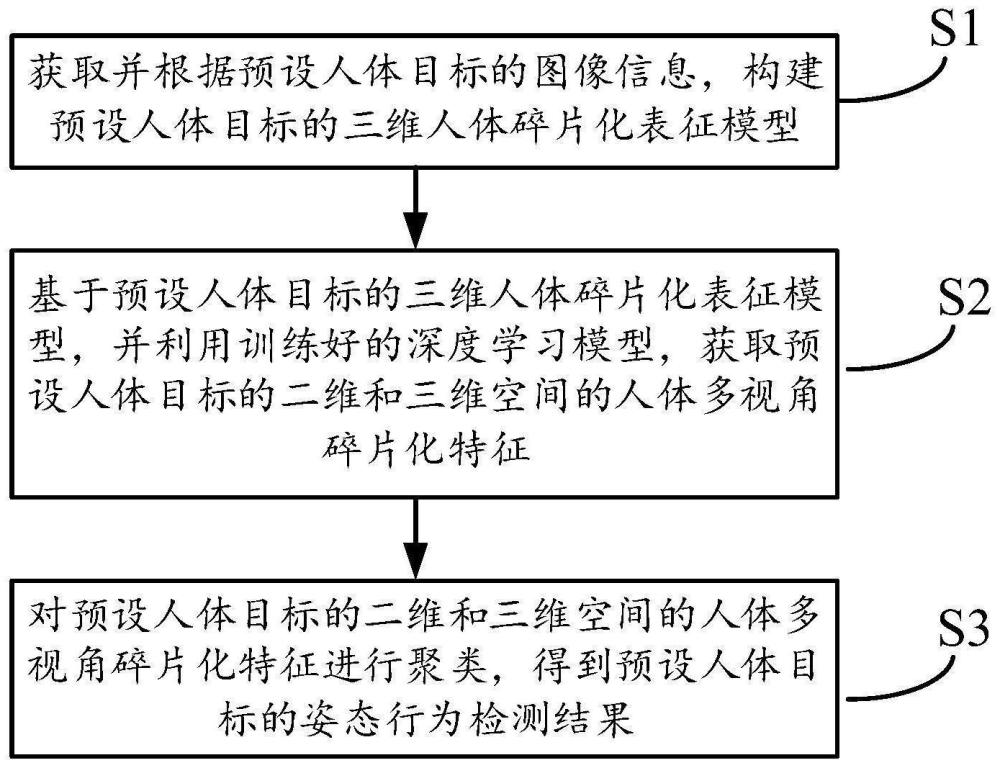
3、获取并根据预设人体目标的图像信息,构建预设人体目标的三维人体碎片化表征模型;
4、基于预设人体目标的三维人体碎片化表征模型,并利用训练好的深度学习模型,获取预设人体目标的二维和三维空间的人体多视角碎片化特征;
5、对预设人体目标的二维和三维空间的人体多视角碎片化特征进行聚类,得到预设人体目标的姿态行为检测结果。
6、本发明提供的一种基于深度学习的人体姿态行为检测方法的有益效果如下:
7、跳出现有“详细标记的正异常行为样本训练神经网络方法”的有监督识别方法的传统思维模式,探索在人体目标存在遮挡干扰情况下,利用碎片化数据提取特征来对人体姿态进行多维度表达与辨识的方法。本发明可克服动态场景中人被遮挡、监控摄像视角变化所带来的影响,摆脱算法误差、环境干扰带来的辨识干扰,对人体姿态进行准确的检测与辨识。
8、在上述方案的基础上,本发明的一种基于深度学习的人体姿态行为检测方法还可以做如下改进。
9、进一步,预设人体目标的三维人体碎片化表征模型包括:预设人体目标的外观、姿态和位置。
10、进一步,训练好的深度学习模型的获取过程,包括:
11、对预设深度学习模型进行训练,得到训练好的深度学习模型。
12、进一步,预设深度学习模型为transformer网络模型,transformer网络模型包括自注意力层、前匮层和规范化层;
13、基于预设人体目标的三维人体碎片化表征模型,并利用训练好的深度学习模型,获取预设人体目标的二维和三维空间的人体多视角碎片化特征,包括:
14、基于预设人体目标的三维人体碎片化表征模型,并利用训练好的transformer网络模型,得到训练好的自注意力层的预测结果、训练好的前匮层的预测结果和训练好的规范化层的预测结果;
15、根据训练好的自注意力层的预测结果、训练好的前匮层的预测结果和训练好的规范化层的预测结果,得到预设人体目标的二维和三维空间的人体多视角碎片化特征。
16、进一步,获取预设人体目标的图像信息的过程,包括:根据监控图像,获取预设人体目标的图像信息。
17、2)第二方面,本发明还提供一种基于深度学习的人体姿态行为检测系统,具体技术方案如下:
18、包括获取构建模块、碎片化特征获取模块和姿态行为检测模块;
19、获取构建模块用于:获取并根据预设人体目标的图像信息,构建预设人体目标的三维人体碎片化表征模型;
20、碎片化特征获取模块用于:基于预设人体目标的三维人体碎片化表征模型,并利用训练好的深度学习模型,获取预设人体目标的二维和三维空间的人体多视角碎片化特征;
21、姿态行为检测模块用于:对预设人体目标的二维和三维空间的人体多视角碎片化特征进行聚类,得到预设人体目标的姿态行为检测结果。
22、在上述方案的基础上,本发明的一种基于深度学习的人体姿态行为检测系统还可以做如下改进。
23、进一步,预设人体目标的三维人体碎片化表征模型包括:预设人体目标的外观、姿态和位置。
24、进一步,还包括训练模块,训练模块用于:对预设深度学习模型进行训练,得到训练好的深度学习模型。
25、进一步,预设深度学习模型为transformer网络模型,transformer网络模型包括自注意力层、前匮层和规范化层;
26、碎片化特征获取模块具体用于:
27、基于预设人体目标的三维人体碎片化表征模型,并利用训练好的transformer网络模型,得到训练好的自注意力层的预测结果、训练好的前匮层的预测结果和训练好的规范化层的预测结果;
28、根据训练好的自注意力层的预测结果、训练好的前匮层的预测结果和训练好的规范化层的预测结果,得到预设人体目标的二维和三维空间的人体多视角碎片化特征。
29、进一步,还包括图像信息获取模块,图像信息获取模块用于:根据监控图像,获取预设人体目标的图像信息。
30、3)第三方面,本发明还提供一种计算机设备,计算机设备包括处理器,处理器与存储器耦合,存储器中存储有至少一条计算机程序,至少一条计算机程序由处理器加载并执行,以使计算机设备实现上述任一项基于深度学习的人体姿态行为检测方法。
31、4)第四方面,本发明还提供一种计算机可读存储介质,计算机可读存储介质中存储有至少一条计算机程序,至少一条计算机程序由处理器加载并执行,以使计算机实现上述任一项基于深度学习的人体姿态行为检测方法。
32、需要说明的是,本发明的第二方面至第四方面的技术方案及对应的可能的实现方式所取得的有益效果,可以参见上述对第一方面及其对应的可能的实现方式的技术效果,此处不再赘述。
- 还没有人留言评论。精彩留言会获得点赞!