一种基于全国产异构平台的OpenCL实现系统及方法与流程
本发明涉及信号处理,尤其涉及一种基于全国产异构平台的opencl实现系统及方法。
背景技术:
1、随着近年来,云计算和大数据应用呈爆发式增长,在推动数据中心产业升级的同时也为数据中心的应用开发与运行维护带来了一系列问题。目前,数据中心运维人员主要通过易于编程的多核cpu和gpu来开发应用,但是,从设备gpu不具有硬件可编程性,仅能通过利用gpu已存在的simd、加速模块等特点,发挥从设备运算效率。因此,对于一些特殊的场景,基于gpu的异构计算或是要经过编译器的复杂的优化或是不能完全发挥硬件的性能。
2、其次多核cpu和gpu加速器在可扩展性上存在严重的问题,即客户希望用简单的全高度插入式pcie开发板作为数据中心服务器的应用加速器。这种开发板经配置可运行高功率图形卡,但客户同时希望功耗不超过25w,以便最大化可扩展性并最小化总功耗。面对这些苛刻的需求,在比较了gpu、dsp、fpga等多种方案之后发现,同等物理环境中,fpga在降低功耗和提升性能上表现最佳。但将fpga应用于数据中心存在着一个最大的问题--编程。
3、数据中心应用开发人员不希望采用传统fpga的开发路径,即以硬件为中心的rtl流程,他们希望能够在完全软件的开发环境中完成易于升级的设计同时保证单位功耗性能最高。opencl代码到fpga平台的直接映射,缩短了面向fpga实现方案的开发周期,降低了fpga平台的开发难度,极大的便利了软件工程师对fpga的使用,即不需要对fpga有深入的了解,也可以实现面向fpga的设计和编程。
4、目前异构计算平台的fpga主要有国外的xilinx和altera公司两大供应商,在国产fpga中还没有类似于xilinx sdaccel的开发工具。
技术实现思路
1、本发明的目的在于针对上述现有技术的不足,提供了一种基于全国产异构平台的opencl实现系统及方法,解决了opencl算法在基于pcie总线的国产fpga异构平台中的实现。
2、为实现上述目的,本发明采用了如下技术方案:
3、本发明提供了一种基于全国产异构平台的opencl实现系统,包括国产化fpga和国产化主控制器,所述国产化主控制器的接口与所述国产化fpga的接口为pcie接口;所述国产化fpga外挂一个ddr设备;
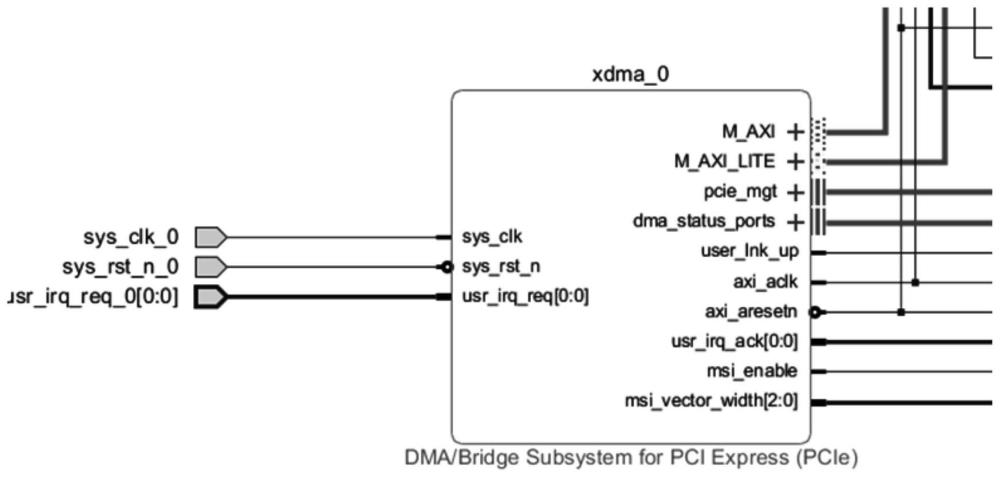
4、在所述国产化fpga端实施例化一个pcie xdma ip核;
5、在主机上实现pcie xdma的驱动;
6、在所述国产化fpga端使用hls实现一个opencl的kernel;
7、在所述主机上编写对应的fpga opencl的api。
8、进一步,一种基于全国产异构平台的opencl实现方法,由所述基于全国产异构平台的opencl实现系统实现,还包括以下步骤,
9、s1、国产cpu端实施例化后的xdma ip核实现并安装的xdma驱动,安装成功后会在/dev目录下生成xdma0_c2h_x、xdma0_h2c_x、xdma0_control和xdma0_user文件;
10、s2、所述主机传输数据到所述国产化fpga;
11、s3、所述国产化fpga传输数据到主机;
12、s4、opencl ip的核实;
13、s5、国产cpu端api的实现。
14、进一步,所述s1中,所述xdma0_c2h_x:是所述国产化fpga到所述国产化cpu端数据传输的设备文件,在所述国产化fpga通过pcie接口向所述国产化cpu传输数据的时候使用的设备文件;
15、所述xdma0_h2c_x:是所述国产化cpu到所述国产化fpga数据传输的设备文件,为所述国产化cpu通过pcie接口向所述国产化fpga发送数据的时候使用的设备文件;
16、所述xdma0_control:是fpga xdma的内部寄存器控制的设备文件;
17、所述xdma0_user:是pcie接口到axi lite master interface选择的空间设备文件。
18、进一步,所述s2中,主机传输数据到所述国产化fpga的操作流程为:
19、用户打开所述xdma0_c2h_x并初始化dma;用户程序分配一个数据缓冲区指针,并将所述数据缓冲区指针和数据大小传递给所述xdma0_c2h_x;
20、驱动程序基于输入数据/大小创建描述符,并用起始描述符及相邻的描述符初始化dma;
21、所述驱动程序写一个控制寄存器来启动dma传输;
22、dma从主机读取所述描述符并开始处理每个描述;
23、dma从主机获取数据并将数据发送到用户端;
24、当所有数据都根据设置传输完毕后,dma会产生一个中断给主机;
25、isr驱动在中断处理程序中找出正在发送中断的dma引擎,查看中断状态寄存器及有多少个描述符被处理过;
26、转态无误后,驱动程序将传输字节长度返回给用户端。
27、进一步,所述s3中,国产化fpga传输数据到主机的操作流程为:
28、用户打开所述xdma0_c2h_x并初始化dma;
29、用户程序分配一个数据缓冲区指针,并将所述数据缓冲区指针和数据大小传递给所述xdma0_c2h_x;
30、驱动程序基于输入数据/大小创建描述符,并用起始描述符及相邻的描述符初始化dma;
31、驱动程序写一个控制寄存器来启动dma传输;
32、dma从主机读取所述描述符并开始处理每个描述符;
33、dma从所述国产化fpga获取数据并将数据发送给主机;
34、当所有数据根据设置传输完毕后,dma会产生一个中断给主机;
35、isr驱动在中断处理程序中找出正在发送中断的dma引擎,查看中断状态寄存器及有多少个描述符被处理过;
36、状态无误后,驱动程序将传输字节长度返回给用户端。
37、进一步,所述s4中,opencl ip的核实方式为:
38、新建一个vivado hls,编写一个加法器opencl函数,然后进行合成;
39、从opencl代码合成硬件后,出现了名为“impl”和“syn”的新目录;
40、将vadd ip块添加到设计中,添加vadd ip。
41、进一步,所述s5中,国产cpu端api的实现过程为:
42、打开所述xdma0_user,对所述xdma0_user进行地址映射;
43、打开所述xdma0_h2c_0,将要计算的数据写入到opencl核的数据接收缓存中;
44、通过所述xdma0_user映射的控制寄存器启动opencl核运算;
45、打开所述xdma0_c2h_0,接收opencl核发送的计算结果数据。
46、本发明的有益效果为:基于全国产异构平台的opencl实现方法设计分为cpu端和fpga端,cpu与fpga的数据通信为pcie(xdma)方式。设计方法是fpga端opencl生成ip核,与pcie集成。cpu端根据fpga端生成的ip核的地址寄存器、数据寄存器及控制寄存器编写相应的api接口,用户通过调用api接口实现opencl所需数据的发送、控制计算及计算结果的获取。
- 还没有人留言评论。精彩留言会获得点赞!