一种基于联邦半监督学习的皮肤病变智能识别方法及系统
本发明涉及人工智能与智慧医疗,具体为一种基于联邦半监督学习的皮肤病变智能识别方法及系统。
背景技术:
1、皮肤病是最为常见的疾病之一,而恶性皮肤病变,如黑色素瘤,是导致全球皮肤病相关死亡病例的主要原因。早期诊断对黑色素瘤患者的生存率至关重要,研究表明在早期阶段被诊断出来的患者5年生存率可达90%以上。反之,若黑色素瘤在早期未被诊断出来,致死率极高,患者五年生存率通常低于15%。因此,及早发现和诊断恶性皮肤病变对于减少患者死亡率具有重要意义。借助深度学习,可以实现基于图像的皮肤病自动识别分类,提高诊断的效率和准确率。
2、当前基于深度学习的皮肤病识别方法取得了良好的性能,其仍在存在一些挑战。大规模高质量的皮肤病变数据是训练深度学习模型的关键,但是目前大多数公开可用的皮肤病变数据集规模较小,这限制了深度学习模型的性能和泛化能力。其次,在医疗领域,医疗机构之间无法共享患者数据。由于训练样本不足,单一医疗机构训练得到的诊断模型往往性能较差,无法满足皮肤科医生的辅助诊断以及患者的初步筛查需求。
3、目前,有许多研究者针对数据异构提出了新的联邦学习方法,其中,具有代表性的方法大概有三类:基于数据的方法、基于聚合优化的方法以及基于个性化的方法。
4、基于数据的方法:基于数据的方法旨在通过修改数据分布来解决数据异构问题。虽然基于数据的方法可以显著提高模型在异构数据上的性能,但是这些方法中的大多数需要依赖于数据共享,这会增加数据隐私泄露的风险。
5、基于聚合优化的方法:联邦学习聚合策略的优化方法在数据异构环境下提升了联邦学习性能,但是此类方法并未提供针对特殊客户端的个性化解决方案。
6、基于个性化的方法:个性化的联邦学习方法,根据每个参与者的特定需求和环境来调整训练过程。个性化方案提高了联邦学习在异构数据上的性能,但是由于其需要考虑不同客户端之间的差异并选择合适的模型结构和算法,因此其可扩展性差也是一个亟需解决的问题。
技术实现思路
1、鉴于上述存在的问题,提出了本发明。
2、因此,本发明解决的技术问题是:现有的皮肤病变智能识别方法存在功耗耗损较大,负载率奖惩,成本较高,以及如何将任务请求分配到各个主机上实现负载平衡的优化问题。
3、为解决上述技术问题,本发明提供如下技术方案:一种基于联邦半监督学习的皮肤病变智能识别方法,包括:
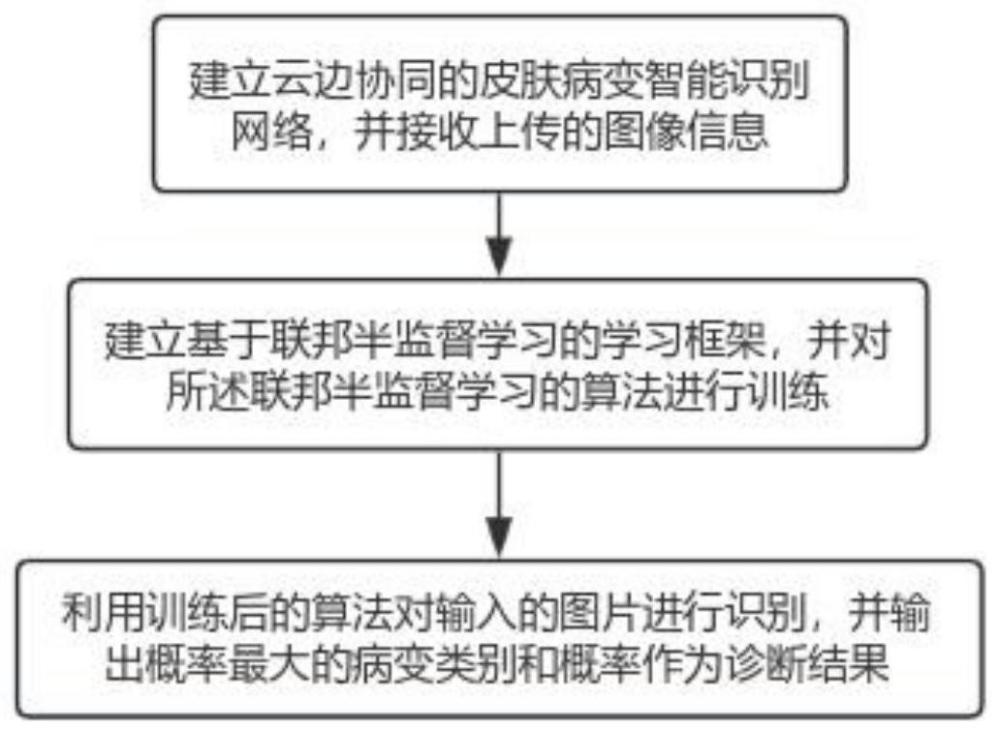
4、建立云边协同的皮肤病变智能识别网络,并接收上传的图像信息;
5、建立基于联邦半监督学习的学习框架,并对所述联邦半监督学习的算法进行训练;
6、利用训练后的算法对输入的图片进行识别,并输出概率最大的病变类别和概率作为诊断结果。
7、作为本发明所述的基于联邦半监督学习的皮肤病变智能识别方法的一种优选方案,其中:所述云边协同的皮肤病变智能识别网络包括,用户、边缘层、云层与样本源层;
8、所述用户上传图像至边缘服务器;
9、所述边缘层接受云层的训练参数,利用样本源层提供的训练样本对初始模型进行训练得到本地模型,将本地模型上传至中心服务器参与协同训练;并为用户提供皮肤病变诊断服务;
10、所述云层由中心服务器、样本存储组成;中心服务器聚合本地客户端上传的模型参数,并将全局模型参数分发给各个客户端更新全局模型;对预测结果的置信度高于阈值的样本的诊断结果及原始图片进行存储;
11、所述样本源层为客户端提供训练样本。
12、作为本发明所述的基于联邦半监督学习的皮肤病变智能识别方法的一种优选方案,其中:所述联邦半监督学习包括,面向数据异构的半监督损失函数,同时通过融合多重随机采样与准确率加权方法,将各个不均匀的本地模型聚合成一个全局共识模型。
13、作为本发明所述的基于联邦半监督学习的皮肤病变智能识别方法的一种优选方案,其中:所述融合多重随机采样与准确率加权方法的步骤包括,
14、设置客户端数量n;每次随机采样的客户端数量j;随机采样操作次数k;
15、通过多重随机采样,每次随机从n个客户端中随机选中j个客户端;
16、每个客户端cj接受全局模型参数使用fixmatch算法对模型进行本地客户端训练得到新的模型参数并计算准确率;
17、使用准确率加权计算各个客户端的权重;
18、计算全局子模型参数和第t轮全局模型参数
19、本轮训练结束时,判断随机采样次数是否为k,若为k则结束训练,否则重复多重随机采样至计算和的过程;
20、结束训练,输出第t轮的全局模型
21、所述权重表示为:
22、
23、其中,wi表示第i个客户端的权重,acci表示第i个客户端模型的验证准确率,accj表示第j个客户端模型的验证准确率,j为选中的客户端数量;
24、在第t轮,第k次随机采样的全局子模型为:
25、
26、执行完k次随机采样操作后,中心服务器聚合k个全局子模型来更新全局模型:
27、
28、其中,wkj表示在第t轮的第k次随机采样操作中,第j个客户端的权重;表示在第t轮的第k次随机采样操作中,第j个客户端的模型参数。
29、作为本发明所述的基于联邦半监督学习的皮肤病变智能识别方法的一种优选方案,其中:所述fixmatch算法的训练过程由有监督训练和无监督训练组成;
30、对于有标签样本,使用标准的交叉熵损失函数ls执行有监督训练;
31、
32、其中,b表示有标签样本的批大小,pb表示有标签样本的真实标签,表示模型对弱增强有标签样本的预测概率分布;
33、对于无标签样本,fixmatch首先求模型对弱增强样本的预测概率分布在预测结果高于预设置的阈值τ时生成伪标签对于强增强样本,输出的预测结果和对应弱增强样本得到的伪标签做交叉熵损失,得到无标签样本的损失函数然lu;
34、
35、其中,μb表示无标签样本的批大小;表示弱增强样本生成的伪标签,表示强增强样本的预测概率分布。
36、作为本发明所述的基于联邦半监督学习的皮肤病变智能识别方法的一种优选方案,其中:对所述数据异构问题,通过有效控制本地模型与全局模型之间的差异来提升模型性能;
37、所述半监督损失函数由原始fixmatch损失函数ls+λulu和引入的l2正则项组成;面向数据异构的半监督损失函数表示为:
38、
39、其中,λu是一个超参数,表示无标签样本损失的相对权重;ρ为超参数,用于控制l2正则项的大小。
40、作为本发明所述的基于联邦半监督学习的皮肤病变智能识别方法的一种优选方案,其中:通过训练后的模型识别皮肤病变的具体步骤为:
41、用户将病变图片上传至终端设备;
42、端设备将病变图片传送给所属的边缘服务器;
43、边缘服务器接收到终端设备的诊断请求后,将诊断请求中的皮肤病变图片输入至存储的皮肤病变智能识别模型;
44、病变图片输入识别模型后,得到所述图片属于每种皮肤病变的概率,并输出概率最大的病变类别和概率作为诊断结果;
45、边缘服务器将模型输出的诊断结果传回给终端设备;
46、用户通过终端设备获得诊断结果。
47、一种采用本发明所述方法的基于联邦半监督学习的皮肤病变智能识别系统,其特征在于:
48、网络管理模块,建立云边协同的皮肤病变智能识别网络,并接收上传的图像信息;
49、算法训练模块,建立基于联邦半监督学习的学习框架,并对所述联邦半监督学习的算法进行训练;
50、诊断模块,利用训练后的算法对输入的图片进行识别,并输出概率最大的病变类别和概率作为诊断结果。
51、一种计算机设备,包括:存储器和处理器;所述存储器存储有计算机程序,其特征在于:所述处理器执行所述计算机程序时实现本发明中任一项所述的方法的步骤。
52、一种计算机可读存储介质,其上存储有计算机程序,其特征在于:所述计算机程序被处理器执行时实现本发明中任一项所述的方法的步骤。
53、本发明的有益效果:本发明提供的基于联邦半监督学习的皮肤病变智能识别方法,在保护用户隐私的前提下,协同训练各个医疗机构数据,可为用户提供准确便捷的诊断服务。设计了一种面向数据异构的半监督损失函数,以有效控制局部模型与全局模型之间的差异。通过融合多重随机采样与准确率加权方法,明确各个本地模型的贡献,并将各个不均匀的本地模型聚合成一个全局共识模型,以进一步降低数据异构的影响。取得了更好的分类性能,同时其可扩展性也明显优于其他现有方法。
- 还没有人留言评论。精彩留言会获得点赞!