基于特征通道解耦的端到端文本识别方法与流程
本发明涉及深度学习和计算机视觉领域,尤其涉及一种基于特征通道解耦的端到端文本识别方法。
背景技术:
1、端到端文本识别是指将场景中的文本图像直接映射成计算机可读的文本结果的过程。该任务的目标是将给定的文本图像转换为对应的文本字符串,无需人工干预或先验知识的介入。端到端文本识别包含了文本检测和文本识别两个子任务,其中文本检测是指在图像中定位和定向文本区域,而文本识别则是将文本区域中的字符识别为对应的文本字符串。端到端文本识别在许多应用中得到了广泛的应用,例如自动化办公、数字化档案管理、车牌识别等。
2、当前的文本识别方法的大多使用共同的特征提取器提取出图像视觉特征,将共用的图像视觉特征输入独立的文本检测模块和文本识别模块得到文本检测和识别的结果。但是,文本识别只需要知道文本内容而不需要准确定位文本位置,需要抽象程度更高的高维特征,文本检测需要准确知道其位置而不需要知道其内容,需要抽象程度较低的低维特征,共用特征会使这些方法只能达到次优的性能。因此,研究如何针对两个子任务提取出最适合任务的特征,能够提升文本识别的性能。
技术实现思路
1、本发明旨在至少解决现有技术中存在的技术问题之一。为此,本发明公开了基于特征通道解耦的端到端文本识别方法。所述方法能够实现端到端的文本检测以及识别,相比现有方法,本方法创新性地把视觉特征解耦为检测专有特征,识别专有特征和检测识别共有特征,对检测模块,使用检测专有特征和检测识别共有特征,对识别模块,使用识别专有特征和检测识别共有特征;通过特征解耦,检测和识别模块的精度获得提升,本发明实现了更精准的端到端文本识别。
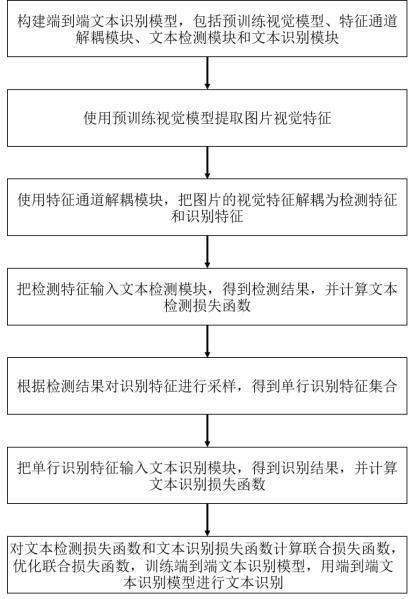
2、本发明的目的是通过如下技术方案实现的,基于特征通道解耦的端到端文本识别方法,所述方法包括:
3、步骤1,构建端到端文本识别模型,包括预训练视觉模型、特征通道解耦模块、文本检测模块和文本识别模块;
4、步骤2,使用预训练视觉模型提取图片视觉特征;
5、步骤3,使用特征通道解耦模块,把图片的视觉特征解耦为检测特征和识别特征;
6、步骤4,把检测特征输入文本检测模块,得到检测结果,并计算文本检测损失函数;
7、步骤5,根据检测结果对识别特征进行采样,得到单行识别特征集合;
8、步骤6,把单行识别特征输入文本识别模块,得到识别结果,并计算文本识别损失函数;
9、步骤7,对文本检测损失函数和文本识别损失函数计算联合损失函数,优化联合损失函数,训练端到端文本识别模型,用端到端文本识别模型进行文本识别。
10、所述的使用预训练视觉模型提取图片的视觉特征,包含以下步骤:
11、使用预训练视觉模型,将输入的图片映射为视觉特征,表达式为:其中,是一个的三维张量,其中表示通道数,表示高度,表示宽度,是预训练视觉模型提取出的图片视觉特征。
12、所述的使用特征通道解耦模块,把图片视觉特征解耦为检测特征和识别特征,包含以下步骤:
13、步骤301,计算识别门控矩阵;使用全连接层对所述的图片视觉特征进行映射,表达式为:
14、;
15、其中,和是可学习的参数,是激活函数用于把向量归一化为概率向量,是和图片视觉特征相同维度的张量,对其在通道维度上进行累加,数学表达式为:
16、;
17、其中,表示的下标为的索引值,表示的下标为的索引值,是识别门控矩阵;
18、步骤302,计算检测门控矩阵;使用全连接层对所述的图片视觉特征进行映射,数学表达式为:
19、;
20、其中,和是可学习的参数,是激活函数用于把向量归一化为概率向量,是和图片的视觉特征相同维度的张量,对其在通道维度上进行累加,取负数后加一,表达式为:
21、;
22、其中,表示的下标为的索引值,表示的下标为的索引值,是检测门控矩阵;
23、步骤303,计算检测专有特征;表达式为:
24、;
25、其中,表示张量按位相乘的操作,是检测专有特征;
26、步骤304,计算识别专有特征;表达式为:
27、;
28、其中,表示张量按位相乘的操作,是识别专有特征;
29、步骤305,计算检测识别共有特征;表达式为:
30、;
31、其中,表示张量按位相乘的操作,是检测识别共有特征;
32、步骤306,计算检测特征;把检测专有特征和检测识别共有特征拼接,并使用全连接层对其映射,表达式如下:
33、;
34、其中,和是可学习的参数,表示在最后一个维度进行拼接的操作,是激活函数,是特征通道解耦模块输出的检测特征;
35、步骤307,计算识别特征;把识别专有特征和检测识别共有特征拼接,并使用全连接层对其映射,表达式如下:
36、;
37、其中,和是可学习的参数,表示在最后一个维度进行拼接的操作,是激活函数,是特征通道解耦模块输出的识别特征。
38、所述的把检测特征输入文本检测模块,得到检测结果,并计算文本检测损失函数,包括以下步骤:
39、步骤401,生成文本分割标签;根据标注中每个文本框的位置,生成文本分割标签,表达式为:
40、;
41、其中,表示文本分割标签的第i行第j列的值;
42、步骤402,检测特征输入全连接层得到文本检测热力图,做法如下:
43、;
44、其中,和是可学习的参数,是激活函数用于把向量映射为0到1之间,表示模型输出的文本检测热力图;
45、步骤403,计算文本检测损失函数;对文本分割标签和文本检测热力图计算二分类交叉熵损失,表达式为:
46、;
47、其中,表示文本检测损失函数;表示文本分割标签的第i行第j列的值,表示文本检测热力图的第i行第j列的值;
48、步骤404,拟合文本框;在模型推理阶段,对文本检测热力图进行二值化,提取轮廓,拟合四边形,得到四边形集合,在模型训练阶段,四边形集合根据数据集标注获得。
49、所述的根据检测结果对识别特征进行采样,得到单行识别特征集合,做法如下:
50、具体地,对于第i个文本框的四边形,根据矩形在识别特征中进行切割,得到对应的单行特征图,并放缩为一个高度为32像素,宽度根据文本框的宽高比自适应调整的张量,数学表达式为:
51、;
52、其中,表示第i个文本框的单行识别特征,表示第i个四边形,在模型推理阶段,根据检测结果获得,在模型训练阶段,由数据标注中获得,是所述的识别特征。
53、所述的把单行识别特征输入文本识别模块,得到识别结果,并计算文本识别损失函数,包括以下步骤:
54、步骤601,生成文本识别标签;根据数据标注中每个文本框的内容,生成文本识别标签,数学表达式为:
55、;
56、其中, 第i个文本框对应的字符串标注,表示第i个文本框中第j个字符的类别,是一个one-hot向量,表示总的字符类别数,表示第i个文本框中字符的个数;
57、的具体赋值方法如下:
58、;
59、步骤602,单行识别特征输入序列模型,得到识别结果;将单行识别特征输入到序列模型transformer解码器中,得到一个序列输出,即为最终的识别结果,数学表达式为:
60、;
61、其中,对表示第i个文本框预测的字符串;
62、步骤603,计算文本识别损失函数;对文本识别标签和序列模型的输出进行损失计算,数学表达式为:
63、;
64、其中,n表示文本框的数量,表示序列模型的第i个文本框中第j个字符为类别k的概率,表示文本识别损失函数。
65、所述的对文本检测损失函数和文本识别损失函数计算联合损失函数,优化联合损失函数,训练端到端文本识别模型,用端到端文本识别模型进行文本识别,包括以下步骤:
66、将文本检测损失函数和文本识别损失函数加权求和,得到联合损失函数,表达式为:其中,是一个超参数,用于平衡两个损失函数的重要性,表示联合损失函数;使用优化算法对联合损失函数进行优化,训练端到端文本识别模型,用端到端文本识别模型进行文本识别。
67、与现有方法相比,本发明方法的优点在于:本技术提供了基于特征通道解耦的端到端文本识别方法,本方法创新性针对文本端到端识别的文本检测和文本识别两个子任务,将视觉特征进行解耦,实现了更高精度的端到端文本检测识别。
- 还没有人留言评论。精彩留言会获得点赞!