基于YOLOv8网络的织物瑕疵检测方法及系统
本发明属于织物表面瑕疵检测,具体涉及一种基于改进yolov8模型的织物表面瑕疵检测方法及系统。
背景技术:
1、实时自动缺陷检测在纺织行业中发挥着重要作用,保证了产品质量,从而提高了竞争力。过去,织物图像中的缺陷检测采用手动执行。由于织物疵点类型多样,背景纹理复杂,该检测工作很大程度上依赖于检验人员的经验,难以满足实时性要求。传统方法基于计算机视觉虽然可以提高检测效果,但存在精度低、速度慢、过程繁琐、泛化性能差等固有缺陷。相比之下,基于深度学习的检测方法在解决这些问题方面具有巨大的潜力。在现代织物生产中,一般需要专业的质检人员来检查织物表面是否存在瑕疵。然而,这种人工检测方法存在效率低下和主观性较高的问题。检测人员不可避免地会疲劳,这可能导致误检或漏检,影响产品质量和生产效率。因此,研发一种自动化的织物瑕疵检测技术是非常有必要的。
2、近些年来,深度卷积神经网络(cnns)在图像分类、检测和分割等任务上大放异彩,吸引了大量工作进行研究。在目标检测领域,同样出现了大量的优秀的工作,代表性的有如r-cnn和yolo系列的检测模型,而且现在仍在不断迭代。其中,yolo系列算法因其检测速度快和轻量的特点,适用领域相较于前者也更为广泛,现有的织物缺陷检测技术在检测精度和检测速度上都存在一定的不足,因此,本发明对yolov8算法进行改进,以在保证检测效率的基础上进一步提升精度。
技术实现思路
1、针对上述现有技术存在的缺陷,本发明提出一种基于改进yolov8网络的织物瑕疵检测方法及系统,本发明在网络的特定位置引入了e-aspp模块和对panet(路径聚合网络)进行下采样优化,解决了在织物瑕疵检测任务中存在的复杂背景干扰和检测速度慢等问题,本发明进行织物图像的瑕疵检测,相较于现有的先进检测技术,在检测精度和效率指标上都具有较大的优势,能较好地满足实际场景中的实时性要求。
2、本发明采取如下技术方案:
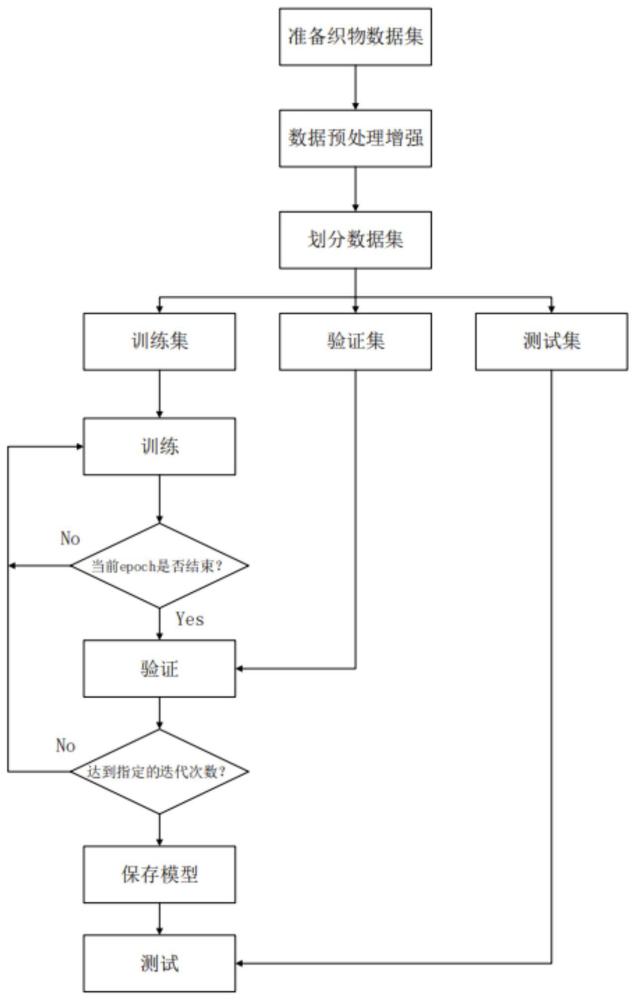
3、基于yolov8网络的织物瑕疵检测方法,包括如下步骤:
4、s1、采集织物图像数据集;
5、s2、对织物图像数据集进行数据增强以扩充数据集,以得到织物图像增强后的数据集;
6、s3、按照预设的比例对增强后的数据集进行划分,分别得到训练集、验证集和测试集;
7、s4、随机选择训练集中的x张图像作为yolov8网络的输入,经过主干网络特征提取后得到了n个不同尺度的有效特征图,然后对所得到的有效特征图进行进一步融合,得到n个不同尺度的融合特征图,最后对融合特征图的通道进行调整以获得n个预测特征图;
8、s5、对于n个预测特征图,直接预测图像中各像素属于待检测物体的概率及物体的边界框信息,然后根据这些信息生成边界框;
9、s6、根据步骤s5得到的预测边界框与对应图片的gt框来计算网络损失值,并使用梯度下降法来更新yolov8网络的参数;
10、s7、重复步骤s4-s6,直到训练集中所有图片都输入网络一次;根据参数更新后的yolov8网络来对验证集的每张图像进行预测,统计后输出验证集中各个类别的ap值;循环迭代,直至所统计的map稳定在某个值,得到训练完成的yolov8网络;
11、s8、使用训练完成的yolov8网络对测试集中所有图像进行预测,得到特征图上的预测框;根据特征图和原图的比例关系,将预测框映射至对应的原图上来定位瑕疵。
12、作为优选方案,步骤s1中,每张图像都对应一个txt格式的标注文件,其中,对图像中的每个瑕疵进行类别和位置的标注。
13、作为优选方案,步骤s1中,对类别和位置的标注作为真实框,称为ground truth(gt)。
14、作为优选方案,步骤s1到数据集具体为,数据集包括多幅织物图像i及对应的标签文件。织物图像尺寸为1024×1024像素。标签文件是记录图像中的目标位置信息和类别信息的txt格式文件。
15、作为优选方案,步骤s2中,使用mosaic数据增强对织物数据集进行扩充,mosaic数据增强是随机选择四张训练集中的四张图像,将四张图片进行随机裁剪,再拼接到一张图上作为新的训练数据。具体的,mosaic数据增强结合20%概率的mixup数据增强对织物图像数据集进行数据增强,以实现数据集的扩充。
16、作为优选方案,步骤s3中,所划分的训练集、验证集、测试集的比例为8:1:1,并生成train.txt、val.txt、test.txt文件来保存对应图像列表。
17、作为优选方案,步骤s4具体包含如下步骤:
18、s4.1、随机选取训练集中x张图像,输入yolov8的主干网络darknet-53中进行逐级特征提取,从中取出最深层的三个含有不同尺度和通道数的有效特征图,尺度分别为20×20、40×40、80×80,所述主干网络darknet-53包括依次相连的2个conv模块、四个c2f模块和e-aspp模块;
19、s4.2、将步骤s4.1得到的三个有效特征图(按照尺度从小到大分别称为m5、m4、m3),输入特征融合网络panet进行进一步融合,经过自顶向下和自底向上的融合充分混合了深层和浅层的特征,对于特征融合模块的每层输出特征图p5、p4、p3,它们的尺度和输入特征图m5、m4、m3保持一致(分别为上述的20×20、40×40、80×80),其中,改进的panet是在e-aspp后引入深度可分离卷积代替原有的普通卷积,实现下采样过程,panet是路径聚合网络,包括从上到下和从下到上的融合路径;
20、s4.3、通过轻量化的yolo head将panet输出的三个融合特征图的通道数调整为3*(5+num_class),输出n个预测特征图。其中,轻量化的yolo head是通过将现有yolo head中的3×3卷积改进为3×3的分组卷积而获得的,num_classe表示类别数目。
21、作为优选方案,步骤s4.2具体包括以下步骤:
22、s4.2.1、将特征图m5经过e-aspp模块,得到特征图k5,将特征图k5进行上采样并和特征图m4进行融合,将融合结果输入c2f模块,以得到特征图k4;
23、s4.2.2、将特征图k4进行上采样并和特征图m3进行融合,将融合结果输入c2f模块,以得到最浅层输出特征图p3;
24、s4.2.3、将特征图p3进行下采样,并与特征图m4和特征图k4进行融合,将融合结果输入c2f模块,以得到中间层输出特征图p4;
25、s4.2.4、将特征图p4特征图进行下采样,并与特征图k5进行融合,将融合结果输入c2f模块,以得到最深层输出特征图p5。
26、作为优选方案,步骤s6中具体为:首先,基于gt框位置找到对应先验框,将gt及标签信息转换为5+num_class长度的向量;然后将其与预测特征图上每个先验框向量计算损失。具体为:
27、根据预测框及相应gt框计算交并比损失(intersection over union,iou),根据网络输出特征图中包含的每个预测框的分类置信度、边框置信度计算分类置信度损失、边框置信度损失,并将交并比损失、分类置信度损失、边框置信度损失以预设比例加权求和以得到网络整体损失,并进行反向传播来优化网络参数。
28、作为优选方案,步骤s7中:将整个训练集的图片都输入一次网络进行前向传播并反向优化网络参数的过程称为一个epoch。在每个epoch过后,使用参数更新完成的网络对验证集中的每张图片进行预测,根据每张图的预测和gt来统计出验证集的各个类别的ap指标。通过连续多轮ap值不变或者出现下降趋势可以判断网络收敛,反之则继续下个epoch的训练。
29、步骤s7中,具体地,进行yolo v8网络模型训练,具体包括以下步骤:
30、a:配置网络环境,python版本为3.8和深度学习框架为pytorch 1.8,使用cuda进行加速;
31、b:设置初始学习率为0.001,学习率调整策略为余弦退火衰减;
32、c:设置每批输入网络的图像数量为8;
33、d:网络不使用预训练权重。在训练过程中的每个周期结束后进行网络整体损失计算。循环迭代,直至验证集的map(mean average precision,全类平局精度)指标稳定在某个值,此时停止yolov8网络的训练。
34、作为优选方案,步骤s8中:对于每张图像,网络输出对应的n个预测特征图,然后直接预测图像中各像素属于待检测物体的概率及物体的边界框信息,根据这些信息生成边界框,得到每张图像的所有预测框,接着使用非极大值抑制(nms)去除其中的冗余框,得到特征图上的预测框。最后根据比例关系将特征图尺度上的预测框映射到原图尺度上。
35、作为优选方案,步骤s8中,从所有调整后的测试集预测框中得到最终预测框具体包括以下步骤:
36、s9.1、对所有调整后的预测框按照置信度得分进行排序;
37、s9.2、在所有调整后的预测框中使用非极大值抑制(non-maximum suppression,nms)去除冗余框,以得到最终的预测框。
38、本发明还公开了一种基于yolov8网络的织物瑕疵检测系统,基于上述的方法,其包括如下模块:
39、图像采集模块:采集织物图像数据集;
40、数据增强模块:对织物图像数据集进行数据增强以扩充数据集;
41、数据集划分模块:按照预设的比例对增强后的数据集进行划分,得到训练集、验证集和测试集;
42、预测模块:随机选择训练集中的x张图像作为yolov8网络的输入,经过主干网络特征提取后得到了n个不同尺度的有效特征图,然后对所得到的有效特征图进行融合,得到n个不同尺度的融合特征图,最后对融合特征图的通道进行调整,获得n个预测特征图;
43、边界框生成模块:对于n个预测特征图,预测图像中各像素属于待检测物体的概率及物体的边界框信息,生成边界框;
44、更新模块:根据得到的边界框与对应图片的gt框计算网络损失值,并使用梯度下降法来更新yolov8网络的参数;
45、迭代模块:将训练集中所有图片都输入网络一次;根据参数更新后的yolov8网络对验证集的每张图像进行预测,统计后输出验证集中各个类别的ap值;循环迭代,直至所统计的map稳定在某个值,得到训练完成的yolov8网络;
46、映射模块:使用训练完成的yolov8网络对测试集中所有图像进行预测,得到特征图上的预测框;根据特征图和原图的比例关系,将预测框映射至对应的原图上以定位瑕疵。
47、本发明的有益效果是:
48、(1)本发明对yolov8网络进行了改进,将主干网络深层的特征图进行冗余去除和上下文特征提取,在加速网络的同时,不影响网络的检测精度。
49、(2)考虑到现有技术特征融合模块panet的下采样操作效率低,引入具有同样功能的轻量下采样dwconv(深度可分离卷积)来提高网络特征融合的效率。此外,本发明通过在主干网络的最深处引入了轻量级的高效的空洞空间卷积池化(efficient atrous spatialpyramid pooling)来筛选对检测任务更有利的特征。特别地,将网络深层中的激活函数更换为硬件友好型的hard-swish来进一步加速网络。
- 还没有人留言评论。精彩留言会获得点赞!