一种基于知识协调的VLP模型参数高效微调方法及系统
本发明属于机器学习的,特别涉及一种基于知识协调的vlp模型参数高效微调方法及系统。
背景技术:
1、目前,大模型的预训练-微调范式已在自然语言处理(nlp)、计算机视觉(cv)和多模态等领域取得了显著成功。在这一范式中,模型首先通过大规模数据进行预训练,然后通过参数全量微调来适应各个下游任务。然而,随着模型规模的不断增大(例如,gpt-3拥有高达175b的参数),以及下游任务种类的不断增多,尤其是在多模态场景中,传统的参数全量微调方法变得日益不切实际,这主要受到其带来的显著增加的计算和存储需求的制约。
2、为了解决上述挑战,研究人员积极探索替代方法。例如:线性探针方法为每个任务调整一个轻量级头部,以减小微调的规模;adapter和prompt learning等方法通过在模型的输入以及模块之间引入轻量化的结构,在nlp领域展示出了显著的可泛化性能。尽管这些方法在一定程度上缓解了由于模型的参数微调所带来的计算和存储成本的问题,但它们通常只考虑单一模态或单一下游任务,缺乏对单/跨模态和不同下游任务的支持。因此,面对日益复杂的视觉语言预训练模型以及多样化的跨模态下游任务,急需研究一种即插即用的、适用于不同vlp模型的轻量化微调方法,来使得预训练模型在特定下游任务上的适配更加灵活和高效。
技术实现思路
1、本发明为解决公知技术中存在的技术问题而提供即插即用的、适用于不同vlp模型的一种基于知识协调的vlp模型参数高效微调方法及系统。
2、本发明为解决公知技术中存在的技术问题所采取的技术方案是:
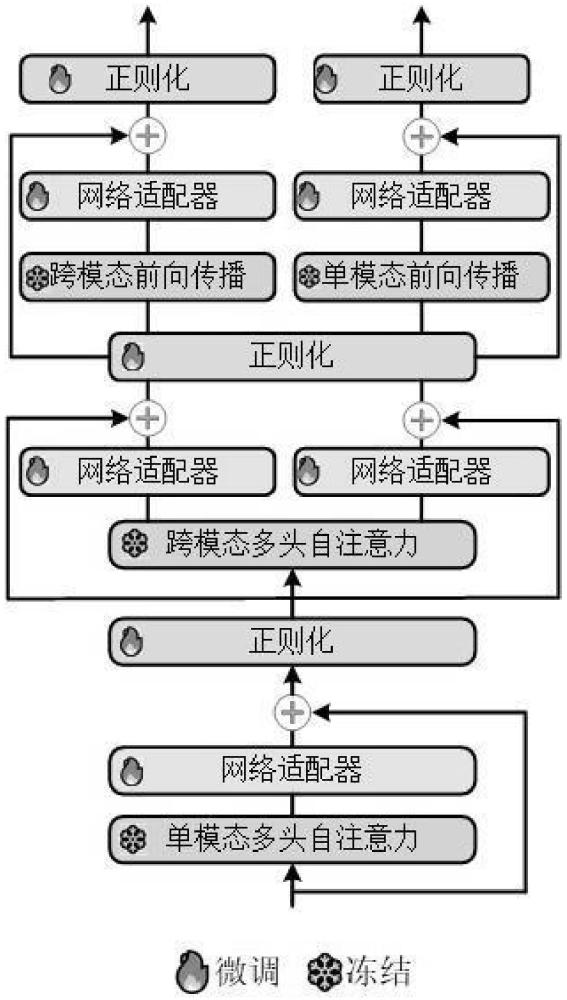
3、一种基于知识协调的vlp模型参数高效微调方法,基于给定的图像文本对及下游任务,从完成预训练的vlp模型中选取多个网络模块,构建vlp基础模型;构建与vlp基础模型中各网络模块进行知识协调的网络适配器;将对应的网络适配器插入vlp基础模型中的各网络模块中,构成vlp扩展模型,对vlp扩展模型进行训练并优化模型参数时,不对vlp基础模型中原有网络模块的参数进行调整,只对网络适配器及其后的正则化层参数进行调整。
4、进一步地,网络适配器包括依次连接的输入全连接层、激活函数层、路由策略层,及均与路由策略层连接的多个并行输出全连接层。
5、进一步地,设网络适配器与vlp基础模型中各网络模块进行知识协调的知识协调函数为fm(zm),fm(zm)的表达式如下:
6、
7、其中,
8、式中:
9、m为网络适配器序号;
10、n为网络适配器数量;
11、为所有网络适配器共享的下采样层的权重;
12、为第m个网络适配器的上采样层的权重;
13、zm为插入第m个网络适配器的网络模块内部的知识;
14、σ(·)为relu激活函数;
15、dm为第m个网络适配器输入维度;
16、rm为第m个网络适配器中间隐藏层维度;
17、设定rm<<dm来保证模型的轻量化设计;网络适配器的下采样层选择参数共享的方式来有效减少参数。
18、进一步地,vlp基础模型包括单模态编码器、跨模态编码器和/或跨模态解码器。
19、进一步地,单模态编码器包括单模态多头注意力层及单模态前向传播网络;跨模态编码器包括跨模态多头自注意力层及跨模态前向传播网络;跨模态解码器包括解码器多头自注意力层及解码器前向传播网络。
20、进一步地,在单模态多头自注意力层及单模态前向传播网络后均插入网络适配器,将在单模态多头自注意力层及单模态前向传播网络后插入的网络适配器称之为单模态网络适配器;设单模态网络适配器的输入为xs,为输入特征xs所属的集合范围;rs为单模态网络适配器隐藏层维度;单模态网络适配器的输出为:xs+router(fs(xs)),其中,router(·)为基于单模态知识的路由规划策略;xs为单模态内部特征;fs(xs)为提前预设的来自单模态的知识信息。
21、进一步地,单模态编码器包括视觉编码器及文本编码器;视觉编码器包括视觉多头自注意力层及视觉前向传播网络;文本编码器包括文本多头自注意力层及文本前向传播网络。
22、进一步地,在跨模态多头自注意力层及跨模态前向传播网络后均插入网络适配器,将在跨模态多头自注意力层及跨模态前向传播网络后插入的网络适配器称之为跨模态网络适配器;
23、设跨模态网络适配器的输入为xc,xc=xc1+xc2+xc3,xc为跨模态内部特征,xc1为跨模态内部对应视觉的特征,xc2为跨模态内部对应文本的特征,xc3为跨模态内部对应多模态的特征;为输入特征xc所属的集合范围;rc为跨模态网络适配器隐藏层维度;
24、跨模态网络适配器的输出为:xc+router(f1(xc1),f2(xc2),f3(xc3);ft(t)),其中,router(·)为基于模态知识的路由规划策略,f1(xc1)为提前预设的来自视觉的知识信息,f2(xc2)为提前预设的来自文本的知识信息,f3(xc3)为提前预设的来自多模态的知识信息,ft(t)为对应视觉、文本、多模态的特征分配权重。
25、进一步地,使router(f1(xc1),f2(xc2),f3(xc3);ft(t))=w1·f1(xc1)+w2·f2(xc2)+w3·f3(xc3),其中w1为对应视觉特征的分配权重;w2为对应文本特征的分配权重;w3为对应多模态特征的分配权重;w1,w2,w3的计算公式如下:
26、设x′ci为xci经跨模态网络适配器转换之后的特征;i=1,2,3;
27、
28、
29、式中:
30、dc为跨模态网络适配器的输入维度;
31、τ为softmax函数的温度系数;
32、b1为跨模态网络适配器路由规划策略中对应视觉特征的偏置;
33、b2为跨模态网络适配器路由规划策略中对应文本特征的偏置;
34、b3为跨模态网络适配器路由规划策略中对应多模态特征的偏置。
35、本发明还提供了一种基于知识协调的vlp模型参数高效微调系统,包括存储器和处理器,所述存储器用于存储计算机程序;所述处理器,用于执行所述计算机程序并在执行所述计算机程序时,实现如上述的基于知识协调的vlp模型参数高效微调方法步骤。
36、本发明具有的优点和积极效果是:
37、(1)本发明提供了一种即插即用的、适用于不同视觉语言预训练模型的轻量化参数高效微调网络适配器,不仅在学术上具备重要的研究价值,而且在实际应用中表现出卓越的实用性;本发明采用网络适配器与vlp基础模型相组合,得到满足不同下游任务需求的vlp扩展模型。使得预训练模型在特定下游任务上的适配更加灵活和高效。
38、(2)本发明实现了对单/跨模态和不同下游任务的支持,解决了传统方法往往只考虑单一模态或单一下游任务的技术问题。
39、(3)本发明在保持性能的同时显著减小模型训练参数量,从而降低了视觉语言预训练模型在适配下游任务时对计算资源和存储空间的需求。这一技术突破为更高效的模型适配提供了可行途径,为应对不断增加的下游任务提供了有力支持。
- 还没有人留言评论。精彩留言会获得点赞!