一种基于YOLO的多尺度目标检测方法
本发明涉及目标检测,更具体的说,它涉及一种基于yolo的多尺度目标检测方法。
背景技术:
1、目标检测是对图像中感兴趣目标进行识别和定位的技术,解决了图像中物体是什么和在哪里的问题,在很多领域都有着非常重要的作用。目标检测算法经常需要被应用在一些需要实时处理图像(如视频、监控画面等)的地方,所以对算法的实时性也提出了要求,通常称处理图像的速度达到30fps以上的算法为实时目标检测算法,随着深度学习时代的来临,目标检测方法已经从基于手工特征提取的传统检测算法发展为基于深度学习的目标检测算法,通过深层次的神经网络学习更为复杂的特征信息,以进一步增强模型对图像的表达能力。目前基于深度学习的目标检测算法主要分为两个方向:二阶段检测算法和一阶段检测算法。二阶段检测算法以r-cnn系列为代表,使用最广泛的有fast rcnn、fasterrcnn等,这类基于区域的检测算法首先要从图片中搜索出一些可能存在对象的候选区,然后再对每个候选区进行对象识别。而以yolo、ssd和retinanet等为代表的一阶段检测算法则是直接在网络中提取特征来预测物体分类和位置,是一种端对端的目标检测方法,大大加快了检测速度,为了更加适用于移动场景,需要为了移动场景专门定制的轻量化网络,解决移动场景下的内存受限,计算力受限的问题,才能够使得轻量级目标检测网能很好的部署到移动场景中。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术中存在的问题,本发明提供了一种基于yolo的多尺度目标检测方法,以解决背景技术中提到的技术问题。
3、(二)技术方案
4、为实现上述目的,本发明提供如下技术方案:一种基于yolo的多尺度目标检测方法,包括以下步骤:
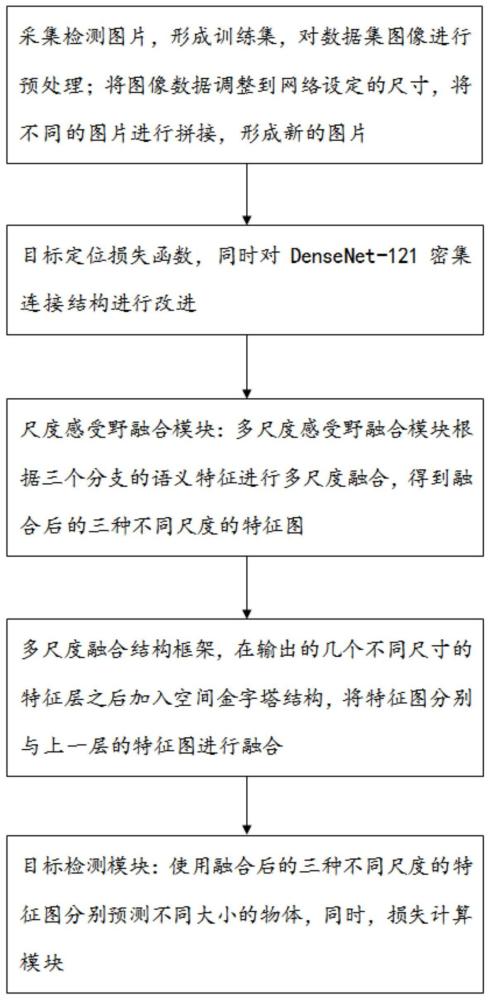
5、步骤一:采集检测图片,形成训练集,对数据集图像进行预处理;将图像数据调整到网络设定的尺寸,yolov5算法主要采用的数据增强方式是mosaic方法,将不同的图片进行拼接,形成新的图片以增加鲁棒性;
6、步骤二:目标定位损失函数,同时对densenet-121密集连接结构进行改进,即将过渡层中的池化层替换为步长为2的3*3卷积层,并使用此改进后的densenet-121结构替换原骨干网络中的残差结构,对输入图像进行下采样操作;
7、步骤三:多尺度感受野融合模块:多尺度感受野融合模块根据三个分支的语义特征进行多尺度融合,得到融合后的三种不同尺度的特征图;
8、步骤四:多尺度融合结构框架,在输出的几个不同尺寸的特征层之后加入空间金字塔结构,将经过空间金字塔模块后的特征图分别与上一层的特征图进行融合,构成四个尺寸的多尺寸预测机制;将经过第二次下采样,已经获得部分特征信息的104*104特征图与经过2倍上采样的52*52特征图进行融合,与尺寸为52*52,26*26和13*13的特征图共同进行特征预测,再使用convolutional 3*3结构以及双层1*1卷积结构进行进一步卷积操作;
9、步骤五:目标检测模块:使用融合后的三种不同尺度的特征图分别预测不同大小的物体,同时,损失计算模块:采用distance-iou loss来计算损失函数,提升检测框的回归精度,得到最终的目标检测网络。
10、本发明进一步设置为,所述目标定位损失函数包括将对角线长度和宽高比关系结合,建立一个新的损失函数;将其引入yolov5进行训练,得到实验数据;寻找宽高比和最小外接矩形框的关系,对损失函数进行优化,并将其引入yolov5进行训练,得到实验数据;思考标定框和预测框是否有新的位置关系,并尝试用新的关系对损失函数进行改进,将其引入yolov5进行训练,得到实验数据;比较不同损失函数对算法预测框准确度的影响,选择表现更好的损失函数作为改进算法的损失函数,已达到使算法定位准确度更高的要求。
11、本发明进一步设置为,所述多尺度融合结构框架包括在颈部网络高层的骨干网络连接处引入1×1卷积遍历高层特征图,以减小高层网络的通道数,在保持高层信息不丢失的情况下降低计算量,使改进算法的速度有一个提升。
12、本发明进一步设置为,所述多尺度融合结构框架还包括在颈部网络的采用分别上采样加融合下采样的方式,增加对骨干网络特征的利用层数,增加可利用信息,达到增加算法精度的目标。
13、本发明进一步设置为,所述多尺度融合结构框架还包括对颈部网络的第一步对算法速度进行了提升,为第二步预计增加的计算量进行一定控制;通过设立选择不同的层数进行对比实验,找到一个fps没有明显下降,而准确度得到提升的算法框架。
14、本发明进一步设置为,所述步骤二还包括特征提取:将训练集输入到特征提取模块中提取语义特征,将提取到的语义特征在不同尺度上抽取三个分支,送入多尺度感受野融合模块;特征提取模块包括依次连接的第一1x1卷积、第一3x3卷积以及通道无缩放卷积块nep;所述通道无缩放卷积块nep包括依次连接的第一层网络、第二层网络、注意力模块eca、第三层网络,第一层网络为第一ghost模块,第二层网络为3x3的深度可分离卷积块,第三层网络为第二ghost模块,所述第一ghost模块、第二ghost模块均包括依次连接的第二1x1卷积和第二3x3的深度可分离卷积,所述第一ghost模块、第二ghost模块替代常用的1x1卷积块;注意力模块eca在全局平均池化后得到的一维特征图上,通过一个权重共享的1维卷积来学习通道无缩放卷积块nep的各通道权重,而其中1维卷积核k×1的大小代表着模块的跨通道信息交互率,k会随着通道数的变化而动态调整;然后将得到的各通道权重分配到通道无缩放卷积块nep的各特征通道上,最后通过权重重新分配后的通道进行权重特征融合,将得到的权重特征融合通过第二ghost模块得到语义特征。
15、本发明进一步设置为,当特征提取模块中使用通道无缩放卷积块nep对当前特征图进行下采样时,扩充通道数,解决因为下采样而带来的特征信息丢失问题。
16、本发明进一步设置为,通道无缩放卷积块nep的深度可分离卷积步长为2时,不使用残差连接;通道无缩放卷积块nep的深度可分离卷积步长为1,加入残差连接。
17、本发明进一步设置为,所述步骤一中对数据集图像进行预处理;将图像数据调整到网络设定的尺寸包括对图像进行颜色增强、平移变化、水平以及垂直翻转;使用线性插值法将所有图像数据大小放缩到416*416。
18、(三)有益效果
19、与现有技术相比,本发明提供了一种基于yolo的多尺度目标检测方法,具备以下有益效果:
20、本发明提出的轻量级目标检测方法,使用了ghost模块作为基础的通道调整与通道特征融合模块,在普通的1x1卷积基础上,引入了3x3的深度可分离卷积,解决了轻量级目标检测网的感受野不够,语义特征不足的问题。并通过引入eca模块,来重新分配通道权重,充分利用轻量级卷积的可用通道容量。并且保证nep模块在计算的过程中通道无缩放,减少了特征信息的丢失,有效的提高网络的检测精度。因此本发明所提出的网络结构,解决了深度卷积神经网络参数复杂度过高的问题,且精度较目前主流的轻量级目标检测算法有一定的提升,参数精度在量化为8bit后,能够进一步减小模型大小,同时实现高精度的目标检测,此外,改进的算法框架将在mscoco数据集上进行训练和测试,使新的算法在基本维持yolo算法fps的情况下,使其拥有更好的检测准确度指标,此外,本发明创造解决了yolo v3在复杂场景中目标尺寸大小不同和小目标重叠距离较近时无法准确识别的问题。使用densenet密集连接网络来提高特征提取网络提取信息的能力,同时优化多尺度预测机制,构建第四个尺度的预测层对不同层次的信息进行融合,使得网络能都学习到能够提高小目标识别率的位置信息。
- 还没有人留言评论。精彩留言会获得点赞!