一种人脸口罩佩戴检测方法和装置
本发明涉及目标检测,特别是指一种人脸口罩佩戴检测方法和装置。
背景技术:
1、由于公共场所人流量大,口罩体积小,因此很难监测口罩的佩戴情况。因此,在公共环境的疾病控制和工业环境的防尘方面,对口罩的佩戴情况进行快速且精准的检测具有重要的研究意义。
2、在各种场景下,现有的检测模型虽然已经有所改进并取得了较好的结果,但在一些恶劣的环境下,仍无法满足实时高效的检测,有进一步提高的空间。检测的具体问题包括识别的检测精度低、低光照下的检测性能差、漏检误检等问题。同时,现有的检测模型还存在原始模型参数大、检测效率低、实时处理能力弱和部署复杂性高等问题。
技术实现思路
1、本发明实施例提供了一种人脸口罩佩戴检测方法。针对数据驱动模型缺乏目标值之间存在的相关性解析的问题,本技术不仅提高识别的检测精度,还可以提高低光照下的检测性能,避免漏检误检的问题。为解决上述发明目的,所述技术方案如下:
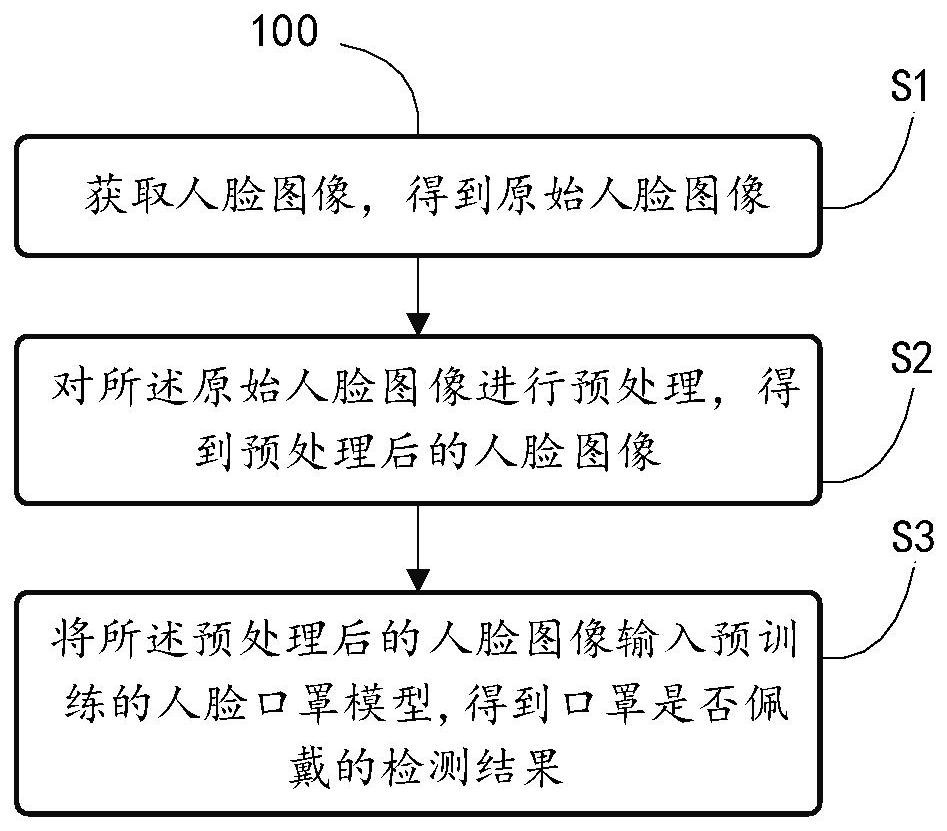
2、一方面,本技术实施例提供了一种人脸口罩佩戴检测方法,包括以下步骤:
3、s1:获取人脸图像,得到原始人脸图像;
4、s2:对所述原始人脸图像进行预处理,得到预处理后的人脸图像;
5、s3:将所述预处理后的人脸图像输入预训练的人脸口罩模型,得到口罩是否佩戴的检测结果,所述人脸口罩模型是基于改进的yolov5模型,所述改进的yolov5模型的骨架为改进的fasternet网络。
6、优选地,在所述s3的将所述预处理后的人脸图像输入预训练的人脸口罩模型,得到口罩是否佩戴的检测结果之前,包括:
7、s01:构建待训练的人脸口罩模型;
8、所述s01的构建待训练的人脸口罩模型,包括以下步骤:
9、s011:初始化yolov5模型,所述yolov5模型包括骨干网络、颈部结构和头部结构,所述yolov5模型的后处理过程采用非极大值抑制;
10、s012:使用改进的fasternet网络替换yolov5模型的骨干网络,得到第一个更新后的模型,所述改进的fasternet网络由4个ema-fasternet块构成,所述ema-fasternet块包括部分卷积层、两个逐点卷积层、批标准化层、线性整流函数层和一个添加在尾部的高效多尺度注意力机制;
11、s013:在第一个更新后的模型的颈部结构中的选定替换位置,使用深度可分离卷积代替c3模块,所述替换位置包含至少一个c3模块,得到第二个更新后的模型;
12、s014:优化第二个更新后的模型的后处理过程,所述后处理过程包括非极大值抑制和解码器;
13、s015:在第二个更新后的模型的骨干网络中加入高效多尺度注意力机制,得到待训练的人脸口罩模型。
14、优选地,所述s013的在第一个更新后的模型的颈部结构中的选定替换位置,使用深度可分离卷积代替c3模块,所述替换位置包含至少一个c3模块,得到第二个更新后的模型,包括:
15、s0131:在第一个更新后的模型的颈部结构中,识别全部的c3模块;
16、s0132:对全部的c3模块进行组合,得到全部的组合位置,所述组合位置包含至少一个c3模块;
17、s0133:在每个组合位置,用深度可分离卷积代替c3模块,得到对应的替代后的模型;
18、s0134:计算每个替代后的模型的检测精度和轻量化程度,遍历全部组合,选择检测精度最优和轻量化程度最高的替代后的模型,得到选定替换位置和第二个更新后的模型。
19、优选地,所述s014的计算每个替代后的模型的检测精度和轻量化程度,遍历全部组合,选择检测精度最优和轻量化程度最高的替代后的模型,得到选定替换位置和第二个更新后的模型,包括:
20、s0141:在第二个更新后的模型的后处理过程,采用软化非极大值抑制替换非极大值抑制;
21、s0142:基于公式(1)计算置信度:
22、
23、其中,si为置信度,a′为得分最大的框,iou为损失函数,i为除得分最大的a′框以外,剩余框以得分从高到底的排序的序号,bi为待处理框,d表示过滤后的候选框,σ为一个超参数;
24、s0143:对每个标签的检测结果按照置信度从高到低排序;
25、s0144:选择置信度最高的口罩锚框作为初始基准框;
26、s0145:计算初始基准框与相邻检测框的重叠度iou;
27、s0146:对大于阈值的检测框设置一个惩罚函数,降低这些检测框的置信度得分;
28、s0147:重复以上步骤,直到所有的检测框都被处理;
29、s0148:根据设定的置信度阈值,最终筛选出目标检测结果;
30、s0149:基于目标检测结果,得到口罩是否佩戴的检测结果。
31、优选地,在所述s3的将所述预处理后的人脸图像输入预训练的人脸口罩模型,得到口罩是否佩戴的检测结果之前,还包括:
32、s02:获取训练数据集,对待训练的人脸口罩模型进行训练,得到预训练的人脸口罩模型;
33、所述s02,包括
34、s021:获取人脸图像集,得到原始人脸图像集;
35、s022:对原始人脸图像集进行预处理,得到预处理后的人脸图像集;
36、s023:对预处理后的原始人脸图像集进行第一次标注,得到多个人脸图像组,所述第一次标注包括给每个图像添加标签,并按照标签将图像分为多个人脸图像组,所述人脸图像组包含同一标签的全部人脸图像,所述标签包括佩戴口罩和未佩戴口罩;
37、s024:按照选定数量比例从各个人脸图像组提取图像,得到第一次标注后的人脸图像集;
38、s025:对第一次标注后的人脸图像集进行样本扩增和数据增强,得到增强后的人脸图像集;
39、s026:对增强后的人脸图像集进行第二次标注,得到训练数据集;
40、s027:基于训练数据集,对待训练的人脸口罩模型进行训练,得到预训练的人脸口罩模型。
41、优选地,所述s021的获取人脸图像集,得到原始人脸图像集,包括:
42、s0211:从多种数据源获取图像数据,所述多种数据源包括公开数据集、网络爬取数据和自采集数据,所述自采集数据为通过拍摄采集的人脸口罩图像数据;
43、s0212:对图像数据进行筛选,保留人脸图像集,得到原始人脸图像集,所述人脸图像集为至少一个人脸出现在图像任意位置的全部图像的集合。
44、优选地,所述s026的对增强后的人脸图像集进行第二次标注,得到训练数据集,包括:
45、s0261:对增强后的人脸图像集中的每个图像,进行人脸部位的识别,得到人脸部位;
46、s0262:在所述人脸部位,进行口罩区域识别,得到口罩区域识别的结果;
47、s0263:基于口罩区域识别的结果,采用标框方法,使用锚框来标记增强后的人脸图像集中的每个图像的每个口罩区域,框出口罩区域,得到口罩锚框;
48、s0264:将标签、口罩锚框和增强后的人脸图像集,进行合并,得到训练数据集。
49、第二方面,本技术实施例提供了一种人脸口罩佩戴检测装置,包括以下步骤:
50、人脸图像单元:用于获取人脸图像,得到原始人脸图像;
51、预处理单元:用于对所述原始人脸图像进行预处理,得到预处理后的人脸图像;
52、检测结果单元:用于将所述预处理后的人脸图像输入预训练的人脸口罩模型,得到口罩是否佩戴的检测结果。
53、第三方面,本技术实施例提供了一种电子设备,其特征在于,所述电子设备包括:壳体、处理器、存储器、电路板和电源电路,其中,电路板安置在壳体围成的空间内部,处理器和存储器设置在电路板上;电源电路,用于为上述电子设备的各个电路或器件供电;存储器用于存储可执行程序代码;处理器通过读取存储器中存储的可执行程序代码来运行与可执行程序代码对应的程序,用于执行前面任意一项所述的方法。
54、第四方面,本技术实施例提供了一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有一个或者多个程序,所述一个或者多个程序可被一个或者多个处理器执行,以实现前面任意一项所述的方法。
55、本发明实施例提供的技术方案带来的有益效果至少包括:
56、上述技术方案,与现有技术相比至少具有如下有益效果:上述方案是基于一个人脸口罩佩戴检测模型。该模型是通过对yolov5模型进行改进得到的。具体改进包括:替换骨干网络、改进颈部网络的卷积、添加注意力机制、改进原有的非极大值抑制。这些改进进一步降低了网络模型的开销,在不影响模型的精度的前提下,显著降低模型的参数量、计算量,较大程度上地提高了模型效率,增加了模型的泛化能力和鲁棒性。基于本技术提出的人脸口罩佩戴检测模型,在一些恶劣的环境下,可以满足实时高效的检测。另外,模型在参数量较大压缩的前提下,精度没有改变。最后,替换不同位置的深度可分离卷机对模型的影响,选出最优组合,导致模型的参数量计算量进一步降低,且精度较高。因此本技术提出的人脸口罩佩戴检测模型同时降低了原始模型参数的数量,也提高了检测效率,提高了实时处理能力,并降低了部署复杂性。
- 还没有人留言评论。精彩留言会获得点赞!