一种基于自适应投影的医学图像去噪方法
本发明涉及一种图像去噪方法,尤其是一种基于自适应投影的医学图像去噪方法。
背景技术:
1、目前,ct成像技术已被广泛应用于临床医学的诊断与治疗,为了减少患者接触的辐射剂量,通常采用低剂量ct(ldct)设备对人体进行扫描。但是,ldct扫描会降低图像清晰度,同时产生噪声,受到噪声污染的图像会丢失细节信息,无法对病灶进一步确诊,大大降低临床诊断的准确性。因此,预处理阶段对医学图像去噪至关重要。
2、医学图像中常见的两种噪声是高斯噪声和量子噪声,高斯噪声服从高斯分布,而量子噪声属于泊松分布。传统的降噪算法通常假定噪声是同分布的,如加性高斯白噪声,进而扩展到泊松-高斯混合噪声的研究,但是在去噪的同时会模糊图像边缘细节,无法满足医学诊断需要。随着深度学习发展,基于卷积神经网络的图像去噪方法成为主流,在图像去噪上取得进展,但仍存在着如下问题:无法适应纹理特征,会导致过渡平滑和细节缺失,在特征不明显的场景下恢复高质量图像较为困难。虽然,许多网络通过加深层数来提升模型性能,但随着网络深度增加,冗余的网络层会导致模型退化,从而扩大计算消耗的时间和内存。
技术实现思路
1、本发明是为了解决现有技术所存在的上述技术问题,提供一种基于自适应投影的医学图像去噪方法。
2、本发明的技术解决方案是:一种基于自适应投影的医学图像去噪方法,是将医学图像输入去噪模型进行处理,其特征在于所述去噪模型依次按照如下步骤进行构建:
3、01部分:数据准备阶段
4、将数据集的ldct图像分为训练集及测试集并进行预处理操作,具体步骤如下:
5、步骤c011:训练集加噪
6、将训练集的ldct图像,分别加入不同类型和强度的合成噪声,得到的训练数据集记为{train_clean_i,train_noisy_i};
7、步骤c012:测试集加噪
8、将测试集的256张测试图像加入与步骤c011同样的合成噪声,构建的测试数据集记为{test_clean_i,test_noisy_i};
9、步骤c013:图像切块
10、按照图像大小为128*128像素对训练集{train_clean_i,train_noisy_i}进行切块,切块后的训练集记为{train_clean_p,train_noisy_p};
11、02部分:将切块后的训练集送入神经网络进行训练,获取去噪模型,具体步骤如下:
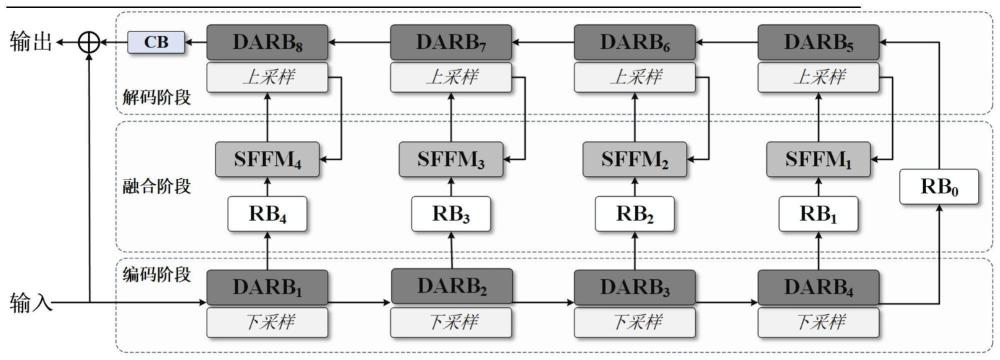
12、步骤c021:所述神经网络有编码阶段、解码阶段和融合阶段,分别记为stagee、staged和stagef,所述编码阶段stagee由分别记为darb1、darb2、darb3和darb4的四组双层注意残差模块构成,所述解码阶段staged由分别记为darb5、darb6、darb7和darb8的四组双层注意残差模块构成,所述融合阶段stagef由分别记为rb1、rb2、rb3、rb4的四个残差组和分别记为sffm1、sffm2、sffm3和sffm4的四组子空间特征融合模块组成;所述编码阶段与解码阶段通过残差组rb0连接,所述解码阶段通过卷积组cb后输出;
13、约定变量epoch为网络循环训练的次数,初始化为0,开始训练网络;
14、步骤c022:将切块后的训练集{train_noisy_p}送入编码阶段stagee,依次通过四组双层注意残差模块darb1、darb2、darb3和darb4对特征进行四次下采样,分别得到双层注意残差模块darb1、darb2、darb3和darb4的输出特征图f_darb1、f_darb2、f_darb3和f_darb4,特征图f_darb4即编码阶段stagee的输出特征图f_stagee;
15、每组双层注意残差模块均按如下步骤操作:
16、(1)输入图像经过卷积层conv1_darb、激活函数leaky_relu1_darb和卷积层conv2_darb得到初始特征图f_initial;
17、(2)初始特征图f_initial送入分别通道注意模块ca和深层注意模块da,得到两个模块提取的特征图,分别为f_ca和f_da;
18、(3)将两个模块提取的特征图f_ca和f_da连接,再经过卷积层conv3_darb得到输出特征图;
19、步骤c023:输出特征图f_stagee经过残差组rb0,得到特征图f_rb0;将得到的输出特征图f_darb1、f_darb2、f_darb3和f_darb4分别对应送入融合阶段stagef的四个残差组rb4、rb3、rb2、rb1,分别得到的特征图记为f_rb4、f_rb3、f_rb2、f_rb1;特征图f_rb0输入解码阶段staged并按照如下步骤操作:
20、(1)特征图f_rb0首先输入双层注意残差模块darb5进行上采样,得到特征图f_darb5,将特征图f_darb5和特征图f_rb1同时输入至子空间特征融合模块sffm1中,分别经过卷积层conv1_sffm1和conv2_sffm1,得到卷积精化后的输出特征图f_conv1_sffm1和f_conv2_sffm1;连接得到融合的输出特征图,记为f_concat_sffm1;将融合特征f_concat_sffm1送入残差组rb_sffm1,得到重塑尺寸的特征图f_resize_sffm1,再通过投影输出重构图像,记为特征图f_sffm1并作为双层注意残差模块darb5的输出;
21、(2)将特征图f_sffm1输入双层注意残差模块darb6进行上采样,得到特征图f_darb6,将特征图f_darb6和特征图f_rb2同时输入至子空间特征融合模块sffm2中,分别经过卷积层conv1_sffm2和conv2_sffm2,得到卷积精化后的输出特征图f_conv1_sffm2和f_conv2_sffm2;连接得到融合的输出特征图,记为f_concat_sffm2;将融合特征f_concat_sffm2送入残差组rb_sffm2,得到重塑尺寸的特征图f_resize_sffm2,再通过投影输出重构图像,记为特征图f_sffm2并作为双层注意残差模块darb6的输出;
22、(3)将特征图f_sffm2输入双层注意残差模块darb7进行上采样,得到特征图f_darb7,将特征图f_darb7和特征图f_rb3同时输入至子空间特征融合模块sffm3中,分别经过卷积层conv1_sffm3和conv2_sffm3,得到卷积精化后的输出特征图f_conv1_sffm3和f_conv2_sffm3;连接得到融合的输出特征图,记为f_concat_sffm3;将融合特征f_concat_sffm3送入残差组rb_sffm3,得到重塑尺寸的特征图f_resize_sffm3,再通过投影输出重构图像,记为特征图f_sffm3并作为双层注意残差模块darb7的输出;
23、(4)将特征图f_sffm3输入双层注意残差模块darb8进行上采样,得到特征图f_darb8,将特征图f_darb8和特征图f_rb4同时输入至子空间特征融合模块sffm4中,分别经过卷积层conv1_sffm4和conv2_sffm4,得到卷积精化后的输出特征图f_conv1_sffm4和f_conv2_sffm4;连接得到融合的输出特征图,记为f_concat_sffm4;将融合特征f_concat_sffm4送入残差组rb_sffm4,得到重塑尺寸的特征图f_resize_sffm4,再通过投影输出重构图像,记为特征图f_sffm4并作为双层注意残差模块darb8的输出,即解码阶段staged的输出特征图f_staged;
24、步骤c024:将特征图f_staged送入卷积组cb,得到最终的重建图像的残差输出,记为f_res;
25、步骤c025:通过l1 loss计算损失函数值,求解残差输出f_res和干净图像块train_clean_p之间的差异,损失函数值记为train_loss;设置变量epoch=epoch+1,当变量epoch达到设定次时,网络完成训练并保存去噪模型train_model.pt;否则反向传播损失函数值train_loss,通过优化算法更新参数,循环进行训练步骤。
26、本发明的神经网络有编码阶段、解码阶段和融合阶段,在编码阶段和解码阶段,引入了双重注意机制的残差块,从而在信息传递过程中自适应地校准重要特征;在融合阶段,提出一种子空间特征融合模块,引入卷积精化和正交投影重构。本发明基于内容和纹理可以对相关特征进行加权,处理的图像能够将混杂的噪声和图像中的细节纹理和边缘信息进行分离,同时保证网络运行效率,有效解决了低剂量医学ct图像的噪声去除问题。
- 还没有人留言评论。精彩留言会获得点赞!