联邦学习中基于双服务器信誉评估机制的鲁棒安全训练方法
本发明属于联邦学习数据安全领域,具体涉及一种联邦学习中基于双服务器信誉评估机制的鲁棒安全训练方法。
背景技术:
1、联邦学习(fl)作为分布式机器学习的新兴范例,可以从分布于客户端的本地数据中训练出有效的模型,并且不需要客户端暴露其原始数据从而保护数据隐私。但由于训练环境中存在恶意客户端,很容易遭受攻击和破坏。因此,为fl设计鲁棒的模型聚合算法对模型训练至关重要。
2、传统鲁棒聚合算法只能防御基础的恶意攻击,并且越来越多针对传统鲁棒聚合算法的攻击方式在破坏鲁棒性方面性能显著。根数据集作为一种以模型性能为导向的聚合算法,不仅能避免恶意攻击对模型性能的影响,还可以鉴别恶意攻击是由哪些客户端发起的,在提高fl鲁棒性能方面发挥重要作用。并且根数据集样本数量要求远小于训练样本数量,这也为其应用在现实场景中提供了极大便利。本方法基于本地模型在根数据集上的表现提出了客户端信誉评估选择机制,不仅防御了恶意攻击并且有效减少了恶意客户端在后续训练轮次的参与次数。
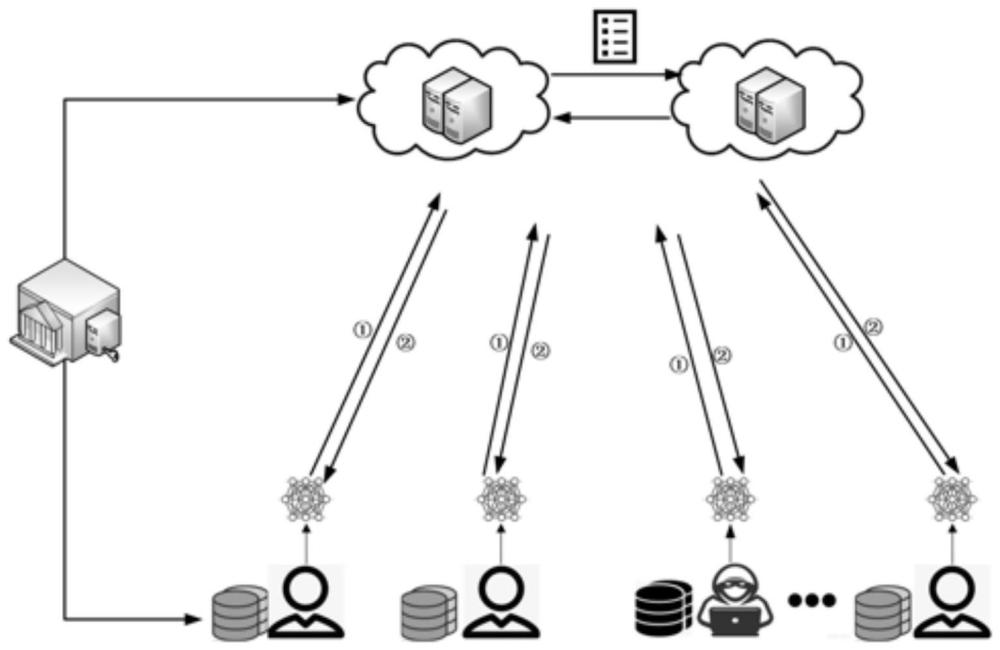
3、在隐私保护方面,传统fl服务器只使用唯一的中心化服务器来聚合并更新全局模型,不诚实的服务器因其在中心化训练框架的绝对领导性可以在履行聚合更新全局模型的职责时直接接触客户端本地模型并进一步获取客户端本地数据信息,而且当服务器出故障时训练进程将完全瘫痪。传统的基于安全多方计算和同态加密的方法虽可以保证服务器无法直接接触本地模型,但同样带来了更多的计算和通信负担。本方法设置了双服务器聚合框架,通过模型拆分将模型分解成多个加噪子模型并分发给相应的服务器,这样服务器无法通过残缺模糊的本地模型推断出客户端的数据隐私。因此本方法更适用于通信和计算资源不足的边缘计算场景中。
4、目前针对恶意攻击和隐私保护问题的相关研究文献如下:
5、1.2020年,bagdasaryan等人在《how to backdoor federated learning》中,提出了使用后门数据构造后门攻击的方法,该攻击方法使用约束和归一化技术在后门数据上训练攻击模型,导致全局模型在输入含有语义后门的样本时输出错误的标签,并且在输入其他样本时保持高准确率输出,从而达到恶意操作全局模型的目标。
6、2.2020年,fang等人在《local model poisoning attacks to byzantine-robustfederated learning》中,提出针对传统的鲁棒聚合算法的中毒攻击方式,通过缩短多个恶意客户端本地模型和中毒模型的欧式距离,导致krum鲁棒聚合算法最终会选择中毒模型用于更新全局模型,证明了传统鲁棒聚合算法无法防范此种攻击方式。
7、3.2019年,zhu等人在《deep leakage from gradients》中,提出一种使用模型参数信息还原出训练样本的方法,通过优化假样本、假标签生成的假梯度和真实模型梯度的损失成功生成了目标样本,完成了从模型窃取客户端本地数据隐私的功能。该隐私窃取方式适合于能够接触所有本地模型的服务器端,导致了客户端在服务器端被窃取本地数据隐私的问题。
8、4.2021年,jin等人在《cross-cluster federated learning and blockchainfor internet of medical things》将区块链引入医疗物联网中,通过地理位置对设备划分集群并提出了hstcon和defcon两套共识机制,实现了单集群和跨集群fl安全框架。但是依然存在恶意客户端过多时操作训练过程导致训练瘫痪的隐患。
9、综上所述,虽然联邦学习在隐私保护和鲁棒聚合方面取得了很大进展,但仍存在以下问题:
10、1.现有的鲁棒聚合算法虽然可以防御一些恶意客户端的中毒攻击,保证训练的有效推进,但在面对新颖的攻击手段时,无法维持全局模型的性能甚至导致训练过程被恶意操控。
11、2.传统的中心化训练框架中服务器不受客户端信任,存在服务器窃取隐私的问题,并且当服务器发生故障时训练会陷入停滞。需要提出包含多个服务器的去中心化训练框架并结合新的通信机制来保证不诚实服务器无法直接接触模型。
12、3.使用加密手段来保护数据隐私需要考虑诸多因素,例如,距离、节点算力、通信链路质量等,大多现有文献采取不同方式进行加密,但都会带来巨大的计算和通信负担,不适用于节点资源受限的现实需要。
技术实现思路
1、针对上述现有技术问题,本发明提供了一种基于双服务器信誉评估机制的鲁棒安全训练方法。用于处理模型训练过程中,恶意客户端破坏模型性能以及服务器直接接触本地模型窃取隐私的问题。根据客户端在服务器端根数据集上历史轮次和当前轮次表现,提出衡量客户端可靠性的方法,即客户端信誉评估的选择机制;并根据双服务器框架去中心化特点,提出结合模型拆分的聚合机制,即基于双服务器框架的鲁棒聚合算法。
2、实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
3、一种联邦学习中基于双服务器信誉评估机制的鲁棒安全训练方法包括以下步骤:
4、步骤一:建立双服务器训练框架并初始化
5、所述双服务器训练框架由若干客户端,双服务器s1和s2,密钥注册中心组成。其中各个组件的功能分别为:客户端随机分布在物理环境中采集用户本地数据并使用本地数据参与模型训练,再执行模型拆分步骤后将加噪子模型发送至服务器,服务器s1和s2负责接收客户端本地模型并相互通信聚合得到全局模型,密钥注册中心负责为参与模型训练的客户端及节点生成密钥并分发;服务器训练框架阶段还包括客户端分类假设,模型初始化及参数选择步骤。
6、步骤二:本地模型拆分及加噪
7、客户端在训练得到本地模型后,先将其拆分成两个子模型再分别加入噪声,并将两个加噪子模型分别发送给对应的双服务器s1和s2。
8、步骤三:基于双服务器框架的鲁棒聚合算法
9、客户端在将子模型发送后,双服务器s1和s2接收到对应子模型,为保证服务器无法通过子模型通信记录推理出本地模型,服务器需要多次互相通信聚合本地模型并获取其在根数据集上的客户端模型分数,从而筛选出性能优异的本地模型进入聚合模型池中并更新全局模型。
10、步骤四:基于客户端信誉评估的选择机制
11、双服务器s1和s2通过记录客户端本地模型在根数据集上的性能表现,并更新其信誉分数。在选择参与每轮训练的客户端应体现服务器对于良性客户端的倾向,双服务器s1和s2根据客户端信誉分数进行随机加权选择,从而确定下一轮参与模型训练的客户端。
12、上述步骤一中,模型初始化及参数选择,客户端分类假设具体方法如下:
13、(1)模型初始化及参数选择:
14、设置参与训练客户端总数为100,每轮选择10%的客户端参与训练,共计训练1000轮,本地训练5个epoch,批量大小为10,学习率为0.01。全局模型选取mnist_2nn,数据集使用mnist手写数字识别数据集。对于服务器根数据集d0,选取测试样本集前100个数据,且每个类别在d0中的分布占比是均匀的。
15、(2)客户端分类考虑到现实场景需要:
16、主要存在两种类型的客户端,一种是诚实参与fl训练期望模型性能优异从而获益的良性客户端,另一种则是期望通过上传中毒模型来降低模型性能的恶意客户端。其中恶意客户端攻击方式具体实现如下:
17、1)中毒攻击:恶意客户端期望在不被服务器察觉的情况下实施中毒攻击。本文假设攻击方式为标签反转,该方法使得全局模型对特定类别精度较低同时对其他类别保持高精度的结果。
18、2)数据泄露:该类威胁主要是由于本地模型在上传过程中被攻击者接收,从而推测出客户端本地数据隐私。
19、3)推理攻击:服务器在接收到客户端使用本地数据训练的本地模型时会通过观察模型的输出来获取关于客户端训练数据的敏感信息。
20、上述步骤二中,客户端本地模型具体拆分步骤如下:
21、(1)以客户端clienti为例,首先客户端使用本地数据在全局模型上训练得到本地模型wi。
22、(2)随后客户端随机选取拆分比例,并将本地模型按照所选拆分比例将其拆分成两个子模型,拆分公式如下:
23、wi=v1wi+v2wi
24、其中wi为客户端本地模型,v1和v2表示客户端本地模型拆分比例,且有v1+v2=1。
25、(3)然后客户端生成噪声并分别向两个子模型添加正噪声和负噪声,最终生成用于服务器聚合本地模型的子模型。加噪方式如下:
26、
27、其中和是拆分加噪后得到的两个子模型,ζi表示ζi是clienti随机生成的生噪声,不同的客户端会添加服从于不同分布或参数的噪声,这样恶意攻击者就无法推理出噪声的添加规律。在将两个加噪子模型分别发送给s1和s2之后,服务器将会进行模型聚合更新。
28、上述步骤三中,服务器相互通信步骤,客户端模型分数具体实现方式如下:
29、(1)服务器相互通信多次获得模型在根数据集上的分数:
30、1)服务器每轮全局训练选取m个客户端上传本地模型,并从中随机选取k个客户端本地模型用于计算模型分数,剩余m-k=r个客户端本地模型做为备用本地模型。
31、2)服务器s2接收全部m个子模型计算模型之和除去每一个客户端子模型之和服务器s2将发送给服务器s1;。
32、3)服务器s1接收全部子模型同样计算模型之和除去每一个客户端子模型之和以及(其中为服务器s1从备用本地模型中随机挑选);服务器s1生成一随机数r∈[1,γ],再将发送给服务器s2并命名为
33、4)服务器s2组合和并测试其在根数据集上的精度acc-i,然后将其返回给服务器s1。
34、5)重复步骤2和3共γ次;服务器s1和服务器s2共通信γ次,在通信次数为r时,服务器s1发送真正的并只保存该轮通信中服务器s2返回的acc-i。
35、6)服务器s1组合和并测试其在根数据集上的精度accavg,计算得到客户端i的模型分数socrei。
36、(2)客户端模型分数与其本地模型在服务器根数据集上的表现有关:
37、scorei=accavg-acc-i
38、
39、其中,g(.)为模型精度测量函数,accavg对应的是将所有本地模型聚合平均后所测量得到的模型精度,acc-i对应的是将本地模型wi排除后再进行聚合平均后所测得的模型精度。当scorei大于0时表明本轮训练wi对于全局模型产生正面影响,而当scorei小于0时则表明本轮训练wi对于全局模型产生负面影响。
40、上述步骤四中,客户端信誉分数更新,客户端加权随机选择具体实现如下:
41、(1)客户端信誉分数更行与客户端本轮分数和历史信誉值有关:
42、
43、其中,为第t轮全局训练开始前第i个客户端的信誉值,e-β为衰减函数对历史声誉进行加权,β为衰减因子,θ1,θ2为设置的阈值。当scorei>θ1>0表明客户端i贡献的本地模型在聚合模型中起到了超出阈值θ1的正向作用。scorei<θ2<0同理。而对于不处于这两个区间的scorei表明其对应客户端在本轮并未对全局模型做出太多贡献同时也并未毒害全局模型,因此不对其信誉值进行额外增加或削减。
44、(2)客户端加权随机选择方式与其信誉值有关:
45、服务器对所有客户端的信誉值求和并计算每个客户端的信誉值比例,服务器生成一个0到总信誉值之间的随机数r。将该随机数从第一个客户端开始遍历,并累加遍历过的客户端的信誉值。如果随机数r小于等于累加值,则选择客户端;否则继续遍历。重复上述步骤,直到选出m个客户端为止。越是行为诚实的客户端被选中参与全局训练的概率也就越大,并且也能获取更多参与训练的奖励;同时也给予了由于计算错误、传输过程出错、又或者是数据质量不好的客户端在参与了一轮全局训练但表现较差后更多的容忍度。
46、本发明的有益效果如下:
47、本发明首先结合客户端本地模型本轮和历史轮次在服务器根数据集上的表现,提出基于客户端信誉评估的选择机制。此外,提出基于双服务器框架的鲁棒聚合算法,保护模型数据隐私。本方法适用于存在恶意客户端参与训练及客户端对服务器不信任的场景,具有较高的鲁棒性且容易实现。
- 还没有人留言评论。精彩留言会获得点赞!