一种优先级字典树的数据结构及其最长前缀匹配方法与流程
本发明涉及计算机,尤其涉及一种优先级字典树的数据结构及其最长前缀匹配方法。
背景技术:
1、最长前缀匹配机制(longestprefixmatchalgorithm)是目前行业内几乎所有的路由器都缺省采用的一种路由查询机制。在ip转发过程中,当网络芯片收到一个ip数据包时,它使用目的ip地址通过转发信息库搜索找到所有匹配的条目。当确定条目是否匹配时,它使用存储在转发信息库中的前缀长度来屏蔽掉与比较无关的目标地址位。这些重叠前缀在转发表中非常常见,可以为数据包提供最佳路径,因为它通过多个路由器到达目的地。
2、早期阶段,最长前缀匹配机制使用传统字典树(trie)数据结构。传统二叉字典树的节点中存储着前缀、节点值、父指针、左子节点指针、右子节点指针。传统字典树存储二进制ip地址前缀会产生大量的无意义的空节点,需要大量内存。在空间使用和查找效率上存在大量的资源浪费。传统字典树浪费的节点数目在最坏的情况下与ip地址最大长度成正比,即传统字典树中的非空节点存储的前缀长度都是最大长度,体现在传统字典树数据结构中,有意义的节点都是前缀集合中层数最深的叶子节点,其他全是空节点。同时,互联网流量的快速增长要求路由器执行高速数据包转发。所引发数据包到达率和路由表大小正在急剧增加,以至于地址查找是最具挑战性的任务之一。
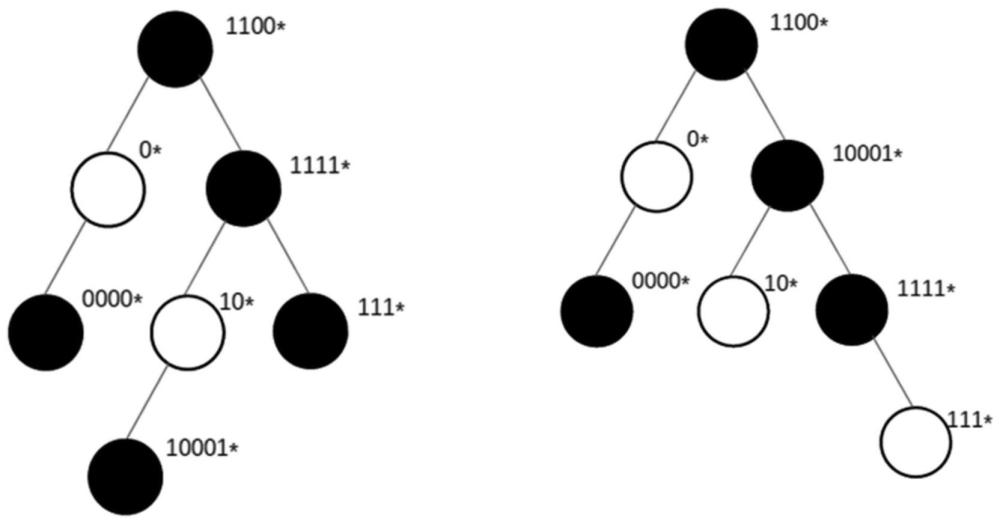
3、如图1所示为传统字典树存储前缀的数据结构,图1中黑色节点代表无存储内容的空节点,白色节点是真实存储前缀的节点。故图1只存储了:0*,0000*,10*,10001*,1100*,111*,1111*七个前缀。不难看出,节点中前缀长度一定等于节点在字典树数据结构中的层数,因此传统字典树存储二进制ip地址前缀会产生大量的无意义的空节点,需要大量内存。在空间使用和查找效率上存在大量的资源浪费。
4、针对上述技术问题,本发明提出一种优先级字典树的数据结构及其最长前缀匹配方法。
技术实现思路
1、本发明的目的是针对现有技术的缺陷,提供了一种优先级字典树的数据结构及其最长前缀匹配方法,能够有效提高查找ip地址最长前缀的效率,减少查找请求的周期,同时减少存储前缀表的内存空间。
2、为了实现以上目的,本发明采用以下技术方案:
3、一种优先级字典树的数据结构,包括:为优先级字典树中的每个节点前缀定义特征值区间,基于特征值区间定义增加字典树中节点的方法,并搭建优先级字典树的数据结构。
4、进一步的,所述搭建优先级字典树的树结构中还包括基于特征值区间定义更新字典树中节点的方法。
5、进一步的,所述搭建优先级字典树的树结构中还包括基于特征值区间定义删减树中节点的方法。
6、进一步的,所述定义特征值区间具体为:
7、特征值区间的下限计算公式,表示为
8、
9、特征值区间的上限计算公式,表示为:
10、
11、其中,li表示特征值区间的下限;ui表示特征值区间的上限;k表示二进制表示的前缀值的比特位;n表示前缀长度;bk表示二进制表示的前缀值的第k位数值;n表示优先级字典树理论上全部前缀集的最大前缀长度。
12、进一步的,所述定义增加字典树中节点的方法以及定义更新字典树中节点的方法,具体为:
13、a1.给定要增加的优先级字典树中节点的前缀,根据前缀的二进制数值,确定优先级字典树的节点路径,并以优先级字典树的根节点为入口,将根节点作为当前比较节点;
14、a2.判断当前比较节点是否为空节点,若是,则将待添加前缀增加到当前比较节点,并为当前比较节点定义属性,算法结束;若否,则执行步骤a3;
15、a3.判断当前比较节点中的前缀特征值区间与待添加前缀特征值区间的上限和下限是否都相同,若是,则更新当前比较节点中的节点值,算法结束;若否,则执行步骤a4;
16、a4.判断当前比较节点的层数是否等于待添加前缀的前缀长度,若是,则执行步骤a6;若待添加前缀的前缀长度大于当前比较节点的层数,则执行步骤a5;
17、a5.判断当前比较节点的前缀特征值区间是否包含待添加前缀特征值区间,若是,则执行步骤a6;
18、a6.将待添加前缀更新到当前比较节点,并为当前比较节点定义属性,当前比较节点中的原前缀更新为待添加前缀;
19、a7.按照待添加前缀的二进制表达式确定下一个通向优先级字典树中的节点,并将通向的节点作为当前比较节点,继续执行步骤a2,直到算法结束。
20、进一步的,所述定义删减字典树中节点的方法,具体为:
21、b1.给定要删减的优先级字典树中节点的前缀,通过精准匹配算法定位到优先级字典树中的节点,并将节点作为待删除节点;
22、b2.判断待删除节点是否为叶子节点,若是,则删除待删除节点,算法结束;若否,则执行步骤b3;
23、b3.为待删除节点寻找完美替代节点;
24、b4.将完美替代节点的前缀置于待删除节点中,并将完美替代节点作为待删除节点,继续执行步骤b2,直到完美替代节点被递归为叶子节点,算法结束。
25、进一步的,所述步骤b3具体包括:
26、b31.给定优先级字典树中特定的非叶子节点;
27、b32.判断给定的非叶子节点是否存在左子节点,若否,则执行步骤b33;
28、b33.判断给定的非叶子节点是否存在右子节点,若否,则执行步骤b37;若是,则将右子节点作为初始节点,并执行步骤b34;
29、b34.判断初始节点是否为普通节点,若否,则执行步骤b36;若是,则执行步骤b35;
30、b35.判断初始节点是否为叶子节点,若否,则将当前初始节点的任一子节点更新为新的初始节点,并继续执行步骤b34;若是,则执行步骤b36;
31、b36.记录当前初始节点;
32、b37.挑选节点前缀长度较长的节点作为完美替代节点。
33、进一步的,所述步骤b32中还包括若给定的非叶子节点存在左子节点,则将左子节点作为初始节点,并执行以下步骤:
34、b321.判断初始节点是否为普通节点,若否,则执行步骤b323;若是,则执行步骤b322;
35、b322.判断初始节点是否为叶子节点,若否,则将当前初始节点的任一子节点更新为新的初始节点,并继续执行步骤b321;若是,则执行步骤b323;
36、b323.记录当前初始节点,并执行步骤b33。
37、相应的,还包括一种基于优先级字典树数据结构的最长前缀匹配方法,包括:
38、s1.对给定的ip地址在指定含有前缀集信息的优先级字典树中寻找最长前缀,并以优先级字典树的根节点为入口,将根节点作为当前比较节点;
39、s2.判断当前比较节点中的前缀特征值区间是否包含ip地址的特征值,若否,则执行s4;若是,则当前比较节点中的前缀为ip地址的前缀,记录当前比较节点信息,并执行步骤s3;
40、s3.判断当前比较节点是否为优先级节点,若是,则执行步骤s6;若否,则执行步骤s4;
41、s4.更新当前比较节点;
42、s5.判断当前比较节点是否为空节点,若否,则执行步骤s2;若是,则执行步骤s6;
43、s6.将最后一次记录的比较节点中的前缀作为ip地址的最长前缀。
44、进一步的,所述步骤s6中还包括若对优先级字典树的搜索过程中没有记录记录比较节点的前缀,则没有ip地址的最长前缀。
45、与现有技术相比,本发明可以利用字典树中的空节点,并且让空节点中恰恰存储前缀长度长的前缀,大大节省了最长前缀匹配的算法效率,并且摒弃了全部冗余的空节点,节省了大量的存储空间。
- 还没有人留言评论。精彩留言会获得点赞!