基于RISC-V向量处理器架构的滑动窗口2D卷积计算方法与流程
本发明属于通信,具体涉及risc-v(开源指令集架构)向量处理器架构的滑动窗口2d卷积计算方法。
背景技术:
1、在智能安防、智能影像设备、家居设备、手持设备、机器人、自动驾驶等等领域,卷积神经网络在整个智能化的方案中起到了至关重要的作用,是人工智能(ai)应用的核心。而卷积神经网络中高度并行化的矩阵以及卷积计算占总体计算量的90%以上。
2、目前已经有大量商业上很成功的通用图形处理器(gpgpu)和专用集成电路(asic)的加速器方案。而在中央处理器(cpu)上的加速方案却寥寥无几。而在传统意义上普遍认为cpu不擅长去处理数据高度并行计算,cpu算力提升随之而来要求是对于其内部和外部带宽的扩容,这成本是巨大的,而获取的算力提升往往得不偿失。
3、在计算机视觉领域,卷积算子和矩阵乘算子在整个网络中的计算比重巨大。现有方法基于向量指令集或者单指令多数据指令集(simd)对于卷积的处理大多在寄存器当中对数据进行频繁的移动和拷贝,造成了巨大的访存压力以及产生了很多无意义的cpu时钟消耗,也会由于拷贝指令与计算指令中数据的耦合造成数据冒险,进而在处理器多级流水线处理中产生气泡,最终降低程序的执行效率。
4、在高性能计算领域,访存是最大的性能制约,滑动窗口指令则可以规避上文所述的数据频繁移动和拷贝,并且利用卷积计算中数据的空间局部性,提升对已经加载到高速缓冲存储器(cache)、缓存器(register)等高速存储区数据的复用,从而降低对动态随机存储器(dram)的频繁访问,减少访存的时间消耗。
5、综上,设计合理的滑动窗口指令能够充分压榨cpu在ai领域中的性能,在现有的向量扩展(rvv)指令和硬件架构的基础上,构建专用指令、采用较低成本的cpu扩展指令实现矩阵乘以及滑动窗口,去获取高能效比的算力。
技术实现思路
1、本发明的目的在于公开了基于risc-v向量处理器架构的滑动窗口2d卷积计算方法,实现了数据的复用,通过滑动窗口指令,有效避免了数据从cache或内存到寄存器中的拷贝、移动,减少了数据的访存消耗。
2、为了达到上述目的,本发明采用如下方案:
3、基于risc-v向量处理器架构的滑动窗口2d卷积计算方法,包括如下步骤:
4、(1)给定输入矩阵a和输入矩阵b,设定输出矩阵c的尺寸大小;
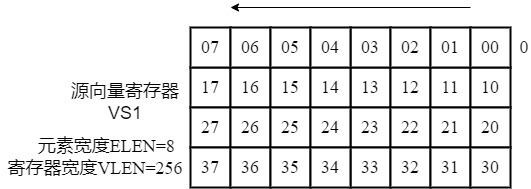
5、(2)输入矩阵a分别在源向量寄存器vs1和源向量寄存器vs1+1中进行映射,输入矩阵b在源向量寄存器vs2中进行映射;
6、(3)根据输入矩阵a在源向量寄存器vs1和源向量寄存器vs1+1中的映射和输入矩阵b在源向量寄存器vs2中的映射,计算输出矩阵c,并将该计算定义为矩阵乘法指令,将输出矩阵c储存在目标向量寄存器vd中;
7、(4)根据输入矩阵a的矩阵参数确定窗口的大小,根据滑动方向和偏移量在源向量寄存器vs1和源向量寄存器vs1+1内的矩阵上对滑动窗口进行滑动并定义为滑动窗口指令;
8、(5)通过矩阵乘法指令和滑动窗口指令对2d卷积进行计算并累加。
9、优选的,步骤(1)中,输入矩阵a的数据类型为8bits整型数据,给定单个向量寄存器中的位数为256bits,矩阵尺寸大小为4×8,单个输入矩阵为32×8bits,输入矩阵a记为a4×8;输入矩阵b的数据类型为8bits整型数据,给定单个向量寄存器中的位数为256bits,矩阵尺寸大小为8×4,单个输入矩阵为32×8bits,输入矩阵b记为b8×4;输出矩阵c的数据类型为32bits整型数据,矩阵尺寸大小为4×4,单个输出矩阵为32×16bits,输出矩阵c记为c4×4。
10、优选的,步骤(2)中,输入矩阵a中元素在源向量寄存器vs1中储存的映射方式为:
11、f: ai(vs1)i,i∈{00,...,07,10,...,17,20,...,27,30,...,37},其中vs1表示源向量寄存器vs1,a表示输入矩阵a中的元素,i表示源向量寄存器vs1中第i个元素,表示输入矩阵a中元素映射到源向量寄存器vs1中;
12、输入矩阵a中元素在源向量寄存器vs1+1中储存的映射方式为:
13、f: ai(vs1+1)i,i∈{00,...,07,10,...,17,20,...,27,30,...,37},其中vs1+1表示源向量寄存器vs1+1,a表示输入矩阵a中的元素,i表示源向量寄存器vs1+1中第i个元素,表示输入矩阵a中元素映射到源向量寄存器vs1+1中。
14、优选的,步骤(2)中,输入矩阵b中元素在源向量寄存器vs2储存的映射方式为:fg,其中g为矩阵转置映射,其表达式为:g:bijbji,bij∈b8×4,表示函数映射复合运算,b表示输入矩阵b中的元素,i表示输入矩阵b行坐标,j表示输入矩阵b列坐标,bijbji表示输入矩阵b中第i行第j列的元素和第j列第i行的元素交换。
15、优选的,步骤(3)中,给定输入矩阵a4×8和b8×4,输出矩阵c4×4的计算公式如下所示:,
16、i∈{0,1,2,3},j∈{0,1,2,3},k∈{0,1,2,3,4,5,6,7},
17、其中c表示输出矩阵c中的元素,i表示输出矩阵c行坐标,j表示输出矩阵c列坐标,a表示输入矩阵a中的元素,b表示输入矩阵b中的元素,k表示输入矩阵a的列数或者输入矩阵b的行数。
18、优选的,步骤(3)中,目标向量寄存器vd包括目标向量低位寄存器vd(l)和目标向量高位寄存器vd(h),输出矩阵c在目标向量低位寄存器vd(l)和目标向量高位寄存器vd(h)的储存方式为:输出矩阵c中第0-7位元素即00,01,02,03,10,11,12,13放在目标向量低位寄存器vd(l),第8-15位元素即20,21,22,23,30,31,32,33放在目标向量高位寄存器vd(h)。
19、优选的,步骤(4)中,输入矩阵a分为两个输入矩阵a14×8和a24×8,其中a14×8存放在源向量寄存器vs1中,a24×8存放在源向量寄存器vs1+1中。
20、优选的,步骤(4)中,在源向量寄存器vs1和源向量寄存器vs1+1中滑动窗口尺寸大小为4×8,滑动方向为从上到下,偏移量为8个元素。
21、优选的,步骤(5)中,卷积计算的具体步骤为:
22、a. 源向量寄存器vs1和源向量寄存器vs1+1用来存输入特征图,源向量寄存器vs2用来存放卷积核,目标向量寄存器vd用来存放累积的输出特征图;
23、b. 源向量寄存器 vs1的一行和源向量寄存器vs2的一列做内积得到一个32bit的元素,并与目标向量寄存器vd中对应位置数据累加,首先执行有符号-有符号矩阵乘法指令计算得到无偏移的矩阵计算结果存放在目标向量寄存器vd中,然后滑动窗口执行偏移8元素的有符号-有符号矩阵乘法指令得到偏移量为8元素的矩阵计算结果,并和上述在目标向量寄存器vd中的结果累加,然后滑动窗口执行偏移16元素的有符号-有符号矩阵乘法指令得到偏移量为16元素的矩阵计算结果,并和上述在目标向量寄存器vd中的结果累加,直至一行的结果计算完毕;
24、c.按照步骤b计算剩余行并累积结果。
25、优选的,步骤(5)中,当滑动的方向元素个数小于8,进行填充补0,此时,源向量寄存器vs1中的值从上一轮中源向量寄存器vs1+1寄存器中搬运,源向量寄存器vs1+1的值全置为0。
26、由于采用上述技术方案,本发明具有以下有益效果:
27、本发明实现了数据的复用,通过滑动窗口指令,有效避免了数据从cache或内存到寄存器中的拷贝、移动,减少了数据的访存消耗。利用卷积计算的空间局部性,提升了cache、register等高速存储复用,降低了对dram的访问,从而达到采用较低成本的cpu扩展指令去获取高效比的算力。通过加速视觉领域当中消耗占比最大的算子,突破现有模型推理的性能瓶颈,从而实现在边缘端模型推理的加速。
28、基于当下模型量化技术相对成熟的背景,对于输入矩阵a和输入矩阵b元素,使用8bit整型存储,输入矩阵使用位宽为256bit的向量寄存器存储32个8bit数值,而输出矩阵输出使用2个256bit位宽的向量寄存器存储16个32bit数值。
29、综上构建出4×8×4的矩阵乘情况(c4×4= a4×8×b8×4),对输入矩阵在向量寄存器中进行映射,其中输入矩阵a按照hw展开(即先按照行再按列展开)的方式映射,输入矩阵b按照wh展开(先按照列再按行展开)的方式映射。根据本方案设计的ai指令,可以在单指令下计算得到4×4大小尺寸的输出矩阵c。根据本发明设计的移位指令,可以实现矩阵乘的滑窗效果。
- 还没有人留言评论。精彩留言会获得点赞!