一种基于LSTM与U-Net融合网络的大豆种植区遥感提取方法
本发明涉及遥感影像处理,具体来说是一种基于lstm与u-net融合网络的大豆种植区遥感提取方法。
背景技术:
1、我国作为农业大国,主要农作物种植普遍具有空间区域范围大、区域间物候差异明显等特点。作物监测难度大,导致我国全面准确、精细的大豆分布数据匮乏,所以作物监测方法的效率和精度亟需提升。
2、遥感数据源的丰富和人工智能领域的崛起促进了作物监测研究的发展。遥感作物监测技术从统计与分析方法等无监督算法、决策树和随机森林等传统机器学习算法,发展至深度学习驱动的智能化监测算法。以卷积神经网络(cnn)、循环神经网络(rnn)、transformer为主的深度学习方法在农作物分类领域得到广泛应用。与传统机器学习算法只学习到农作物“表层”特征相比,深度学习通过“黑箱操作”可以实现更深层次抽象特征的提取与挖掘。
3、传统的大豆提取方法对特征(时相和波段)的依赖度较高,算法在不同地区应用时需要对特征进行优选,兼顾高精度的同时很难保证模型的时空泛化性;基于多时相的深度学习方法将作物生长周期所有信息输入模型,通过计算机算力挖掘数据的深层次特征直接提取大豆的分布,算法精度高并且在不同地区、年份迁移时仍然保持良好的大豆提取效果。传统机器学习方法能够实现的精度有限,而深度学习相比传统方法能实现精度的显著提升,因此具有巨大的应用潜力。
4、目前卫星遥感平台下的研究区主要集中在机械化程度高、农田分布规整和大豆种植集中连片的大规模产区,例如美国、巴西、阿根廷以及中国东北地区,对于以散户种植为主、种植结构较为复杂的地区鲜有关注,例如我国黄淮海和长江流域大豆主产区。该地区天气状况多变,云覆盖频繁,农田景观破碎,作物混杂种植严重,对作物监测带来了巨大挑战。
5、因此,迫切需要基于遥感平台探索出适合此类地区的高精度大豆遥感识别方法。
技术实现思路
1、本发明的目的是为了解决现有技术中机器学习方法提取精度有限、模型时空泛化能力不高的缺陷,提供一种基于lstm与u-net融合网络的大豆种植区遥感提取方法来解决上述问题。
2、为了实现上述目的,本发明的技术方案如下:
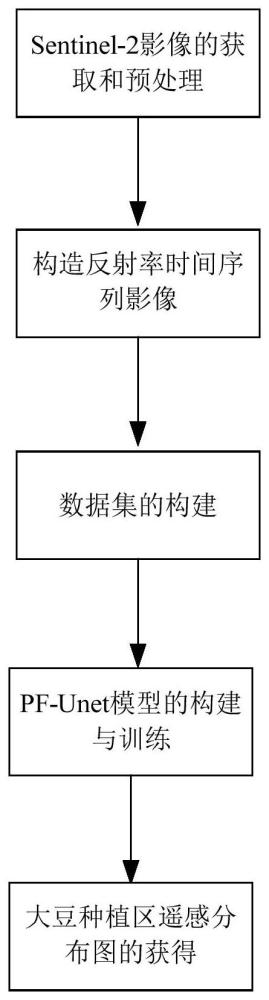
3、一种基于lstm与u-net融合网络的大豆种植区遥感提取方法,包括以下步骤:
4、sentinel-2影像的获取和预处理:根据研究区的大豆生长时间,获得研究区sentinel-2影像,对时间范围内的影像进行去云处理,得到有缺失无云干扰的sentinel-2影像;
5、构造反射率时间序列影像:使用线性插值、savitzky-golay滤波器滤波、等间隔平均值合成方法处理缺失的sentinel-2影像,构造研究区大豆整个生长季的完整波段反射率时间序列影像;
6、数据集的构建:基于目视解析人工标注或现有的大豆产品构造模型训练的标签,将研究区划分训练、验证和测试区,并将时间序列和标签裁切成图块,得到深度学习的所需的数据集;
7、pf-unet模型的构建与训练:构造pf-unet模型,将训练集和验证集输入pf-unet模型进行训练,每轮训练都更新模型参数,保存多轮训练过程中验证集上表现最佳的模型参数;
8、大豆种植区遥感分布图的获得:使用pf-unet模型对测试集数据进行模型推理,得到样方的大豆分布图,使用预测结果和真值标签进行对比,评估模型的精度。
9、所述sentinel-2影像的获取和预处理包括以下步骤:
10、通过农业调查得到研究区大豆物候期,获取大豆生长期时间跨度内研究区所有sentinel-2影像;
11、使用sentinel-2云概率数据集对sentinel-2影像进行去云,设置云概率阈值为30%,并且采用双线性插值法将影像重采样到10m分辨率,得到有缺失无云干扰的sentinel-2影像,即去云后的时间序列影像。
12、所述构造反射率时间序列影像包括以下步骤:
13、对去云后的时间序列影像进行线性插值,以补全云污染的区域:
14、缺失像素在分别向前后的时间窗口中寻找最近高质量的观测值,采用线性插值填补当前的缺失值,计算公式如下:
15、
16、其中,yt是t时刻的插值的时间序列,是影像缺失的t时刻插值时间窗口内向前和向后最近的高质量像素的波段反射率,tm、tn分别是t时刻插值时间窗口内向前和向后最近的高质量像素的时刻,线性插值后得到空间全覆盖的时间序列波段反射率影像数据;
17、对于插值后的时间序列,使用s-g滤波算法进行平滑和滤波,计算公式如下:
18、
19、其中,yi是滤波后的时间序列,xk+i是插值时间序列,hi是滤波器系数,由多项式阶数查表得,n是2m+1的滑窗宽度,m是窗口的半宽度;
20、将滤波后的时间序列中相邻的两个时相进行平均值合成,以压缩原始数据的规模,得到时相数量减半的反射率时间序列影像。
21、所述数据集的构建包括以下步骤:
22、下载覆盖研究区的3m分辨率planet影像,对该影像进行目视解译,标记出典型作物的样本点,使用随机森林算法执行分类得到大豆农田的详细分布,并且重采样到10m分辨率作为真值标签;
23、将研究区划分为多个区块,按比例划分出训练区、验证区和测试区;对于训练区和验证区,采用随机采样在单个区块中进行采样,提取采样点邻域的数据构造样本,邻域大小为w,通过随机采样可以扩充数据集的数量;对于测试区,采用滑窗的方法裁切数据,滑窗步长为w/2。
24、所述pf-unet模型的构建与训练包括以下步骤:
25、构造pf-unet深度学习模型,其将unet和lstm网络进行融合;
26、在pf-unet在跳跃连接中引入convlstm块,用于提取多尺度的时序特征,并将其与解码器的特征图进行连接,增强对原始数据中的时序信息的提取能力;其包含5个模块:输入模块、编码器、跳跃连接块、解码器和输出模块;
27、设定输入模块:pf-unet模型的输入数据是从卫星图像中裁剪的图像切片,输入数据的大小为12×64×64×10,表示时相数、宽度、高度和通道数,每个像素的大小为12×10,有10个特征,分别为sentinel-2的蓝、绿、红、红边1、红边2、红边3、近红外、窄带近红外、短波红外1和短波红外2共10个波段反射率,每个特征包含12个时间序列图像;
28、设定编码器:编码器包含4个timedistributed卷积块和3个timedistributed池化层,
29、卷积块包含2个结构相同、道数相等的2d卷积层,卷积核大小为3×3,步幅为1,填充为2,每个卷积层后面连接批量归一化层和relu激活函数层,然后和下一层相连,池化层为2×2最大池化层,
30、将池化层和卷积块利用timedistributed层封装为timedistributed卷积块和timedistributed池化层,使其处理时间序列影像数据;
31、timedistributed卷积块对每个时相单独进行卷积,多时相间的卷积层参数是共享的,4个timedistributed卷积块的通道数分别为32、64、128、256,输入数据经过timedistributed卷积块通道数进行翻倍,经过timedistributed池化层特征图大小减半,经过4次卷积块和3次池化,最终输出大小为12×8×8×256的高级抽象特征;
32、设定跳跃连接块:每个跳跃连接块包含一个convlstm层,
33、设定convlstm层的卷积核为1×1,convlstm单元数量和输入数据的通道数相等,convlstm层返回最终时间步长的隐藏状态作为输出,其中,最高层的跳跃连接块的输入大小为12×64×64×32,其convlstm单元的数量为32,输出大小为64×64×32;
34、跳跃连接块将编码器和解码器连接起来,整个网络包含4个跳跃连接块,其内部convlstm单元的数量分别为32、64、128、256,由高到低4个跳跃连接块的输出大小分别为64×64×32、32×32×64、16×16×128、8×8×256;
35、多个跳跃连接块提取多尺度的时序特征;
36、设定解码器:其包含3个2×2上卷积层和3个卷积块,3个卷积块的通道数分别为128、64和32,每次上卷积特征图大小均翻倍,解码器结合跳跃连接块输出的多级时序特征,最终将图像恢复为原始大小,即64×64×32;
37、设定输出模块:输出模块包含一个2d卷积层,分别为1×1卷积核、通道数为1和sigmoid层,其对解码器输出的时空复合特征分类,得到软分类结果,使用0.5作为阈值,得到大豆分布结果;
38、将训练集输入pf-unet模型进行训练:
39、使用adam优化器更新参数,输入数据批次大小为8,损失函数为交叉熵损失函数;对于二分类问题,其公式如下:
40、l=-(y*log(p)+(1-y)*log(1-p)) (3)
41、其中,l表示交叉熵损失函数的值,y表示真实值即标签,p表示预测值,即模型输出的概率,log表示自然对数;
42、优化器的初始学习率设置0.0001,为了加速模型的收敛每5个epoch学习率衰减为之前的50%,模型训练30个epoch,每轮训练均更新模型参数,同时在验证集上计算损失,保存多轮训练过程中验证集上损失最小的模型参数。
43、所述大豆种植区遥感分布图的获得包括以下步骤:
44、将测试集内的数据输入训练后的pf-unet模型,每个样本预测结果仅保留中心w/2×w/2大小的区域,所有预测结果按顺序拼接在一起得到测试区域内完整的大豆分布图;
45、使用预测结果和真值标签进行对比,计算出总体精度oa、召回率recall、精度precision和kappa,4个指标评估模型的提取精度,它们的公式如下:
46、
47、
48、
49、
50、
51、
52、其中,tp是真值为大豆,分类后仍为大豆的像素数量;fn是真值为大豆,分类后为非大豆的像素数量;fp是真值为非大豆,分类后为大豆的像素数量;tn是真值为非大豆,分类后为非大豆的像素数量;po表示观察到的准确率,pe表示预期的准确率;n为测试样方内像素的总数量。
53、有益效果
54、本发明的一种基于lstm与u-net融合网络的大豆种植区遥感提取方法,与现有技术相比进行缺失值插值、s-g滤波以及等间隔均值合成,有效减小了云污染对整个时间序列影像的影响,生成空间全覆盖的时间序列波段反射率影像数据;通过将卷积神经网络u-net和长短期记忆网络lstm融合,提出了pf-unet(u-net with phenological feature)深度学习网络,可以从多个尺度提取时间序列中的特征,相比于u-net、lstm和tfbs模型,大豆种植区遥感提取精度更高;该网络在大豆跨年份提取方面展现出更高的潜力,使用前一年的样本进行训练得到的模型,可应用于邻近年份的大豆分布提取,并且相较于其他模型,跨年份提取的精度更高。
- 还没有人留言评论。精彩留言会获得点赞!