一种针对小微企业贷款申请反欺诈检测的方法与流程
本发明涉及一种反欺诈检测的方法,具体为一种针对小微企业贷款申请反欺诈检测的方法,属于金融风控。
背景技术:
1、据相关统计,目前我国的小微企业数量已达1亿户,这些小微企业在国民经济中发挥着多方面的重要作用,对促进经济增长、就业和社会发展都具有重要贡献。相对于大中型企业,小微企业在市场的竞争中处于弱势地位,增加了小微企业在融资方面的难度,导致其很难保证经营的稳定性和持续性。
2、为了支持和鼓励小微企业的发展,政府提供了一系列的扶持政策,尤其在小微企业贷款和融资方面,政府号召金融机构提供低息贷款、信贷担保和融资计划,以帮助小微企业获得资金。为此,商业银行针对小微企业的信贷业务持续扩张,发行了各种信贷产品。截至2022年末,中国银行业金融机构用于小微企业的贷款余额(包括小微企业贷款、个体工商户贷款和小微企业主贷款)达到59.7万亿元,其中单户授信总额1000万元及以下的普惠型小微企业贷款余额为23.6万亿元,同比增速23.6%。但在信贷业务方面,小微企业具有先天的缺陷,财务制度不规范,不能提供准确完整的财务数据,这种非对称数据信息使得银行不能准确把握
3、小微企业的实质性信贷风险,增加了许多银行对小微企业信贷产品管理的困难。小微信贷欺诈风险就是银行要亟需解决的一个困难。
4、针对小微企业欺诈问题,银行的主要解决方案是黑白名单甄别、自动决策的规则引擎,还包括基于数据分析和机器学习算法识别异常模式和高风险指标,这些方案和技术仍在探索过程中。由于现在新的欺诈方式层出不穷,比如欺诈行为倾向团伙化,隐蔽化,导致传统的反欺诈方法很难应对新的变化,对银行和贷款企业造成不必要的损失。
技术实现思路
1、本发明的目的就在于为了解决上述至少一个技术问题而提供一种针对小微企业贷款申请反欺诈检测的方法,在特征工程方面引入了关系图谱的方法,将图特征信息引入模型训练中,提高了模型的准确率。同时采用了lightgbm作为训练方法,提高了训练效率,为模型的在线使用提供了可能。
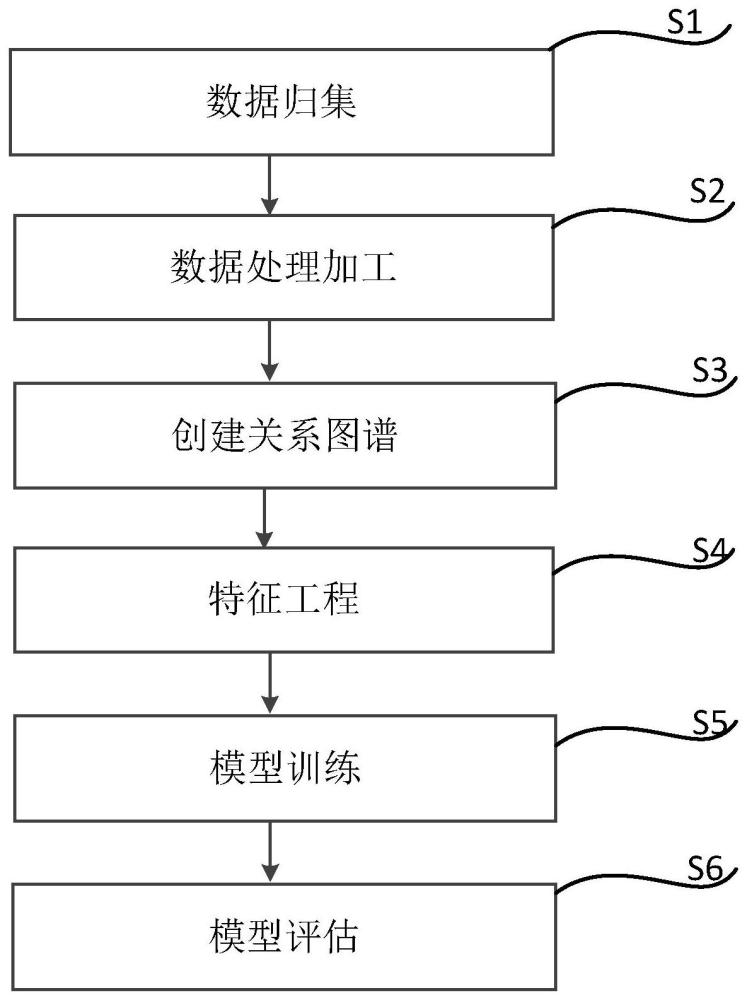
2、本发明通过以下技术方案来实现上述目的:一种针对小微企业贷款申请反欺诈检测的方法,包括以下步骤:
3、s1、数据归集:该步骤是为了创建反欺诈检测模型而收集所需的企业及企业干系人的相关数据,其中企业干系人包含企业的法人、实控人、实控人配偶、自然人股东、高管;涉及以下7个数据维度:
4、1)企业基础信息:企业编号、注册地址、行业分类、法人信息;
5、2)企业工商数据:企业照面信息、企业股东信息、企业高管信息、企业变更信息、企业投融资信息;
6、3)干系人基本信息:个人编号、性别、学历、婚姻状况、子女状况;
7、4)企业交易信息:进项发票信息、销项发票信息;
8、5)企业征信:企业黑名单、第三方企业征信;
9、6)干系人征信:个人征信、个人黑名单;
10、7)企业税务信息:企业税务基本信息、完税信息、欠税信息、增值税信息;
11、s2、数据处理加工:针对步骤s1所归集的数据进行数据集成、数据清洗、探索性数据分析、数据预处理等操作;
12、s3、创建关系图谱:本步骤内容主要包含提取企业和干系人实体、提取实体间关系、创建关系图谱;
13、s4、特征工程:在步骤s2的基础上,进行欺诈行为的定义,筛选企业信息和干系人信息的属性信息,利用步骤s3构建的企业关系图谱提取图特征信息,最终得到企业的特征数据集;
14、s5、模型训练:将步骤s3整理的特征数据集输入到lightgbm机器学习方法中,并通过网格搜索的调参方法训练模型;
15、s6、模型评估:对于步骤s5得到的模型进行泛化能力、稳定性和区分能力的评估。
16、作为本发明再进一步的方案:s2方法具有以下步骤:
17、s21、数据集成:将多个数据源构成一个统一的数据结构。不同的数据源既有结构化数据,也有非结构化的数据,数据集成将数据统一转化为结构化的数据,并存储在一个数据库中;
18、s22、数据清洗:清除数据中的脏数据,包括数据源自身及数据集成后产生的格式不一致、单位不一致、数据冗余问题;
19、s23、探索性数据分析:对数据进行简单的计算统计量,了解原始数据的情况,观察数据中缺失值的情况、异常值的情况和变量分布情况;
20、s24、数据预处理:对于缺失值、异常值等进行处理。
21、作为本发明再进一步的方案:s3方法具有以下步骤:
22、s31、实体和属性抽取;以企业和企业干系人为实体,提取这些实体的属性信息;
23、s32、实体间关系抽取;根据业务需求,本发明将企业风险分为了两大类:包含企业和企业的关系、企业和干系人的关系两大类;其中企业和企业的关系包括担保关系、控股关系、交易关系,企业和干系人的关系包括控股关系、高管关系、实控人关系、亲属关系;
24、s33、关系图谱的构建;根据步骤s31抽取的实体作为节点,以步骤s32抽取的关系作为线创建无向关系图谱;
25、s34、在图数据库neo4j中实现关系图谱的创建和保存。
26、作为本发明再进一步的方案:s33具体包括:点与点之间的权重设定规则如下,以节点u和节点v为例:
27、s331、根据以下规则计算出点与点之间的权重,记为w1[u,v];
28、1.由银行员工“手动”发现的已确认的欺诈交易,权重为1;
29、2.一家企业是另一家企业的股东,权重为0.8;
30、3.一家企业的受益人是另一家公司的受益人或受益人的亲属,权重为0.6;
31、4.企业的注册地址或办公地址相同,权重为0.3;
32、5.相关企业之间存在资金转移,权重为0.05;
33、s332、根据区域重叠sorenson方法计算权重,记为w2[u,v];计算公式如下:
34、
35、公式中分子计算节点u和节点v之间的共同邻居。分母是一个标准化常数,是节点u和节点v度数的总和;
36、s333计算最后权重w[u,v];公式如下:
37、
38、作为本发明再进一步的方案:s4方法具有以下步骤:
39、s41、欺诈行为定义;本发明将企业欺诈行为定义为银行内部及相关部门披露该申请贷款的企业及企业干系人在申请贷款后有严重违规记录建立的欺诈标签,并将该标签作为目标变量;
40、s42、属特征提取;企业节点的属性信息主要来自企业信息和干系人信息中对于刻画企业画像有效的字段;
41、s43、网络特征提取
42、基于步骤s33所构建的关联知识图谱,提取三个维度的图特征:
43、度(degree):计算每个网络节点的连接的边数;
44、接近中心性(closeness):是网络中中心性的度量,计算为该节点与图中所有其他节点之间的最短路径长度之和的倒数;
45、信息图(infomap):是一种根据最小熵原理,推导出的“抱团”情况的聚类算法;
46、s44、特征集汇总
47、将步骤s42和s43产生的属性信息合并到一张表中,形成了一张包含102字段的宽表。
48、作为本发明再进一步的方案:s42具体包括:
49、s421、企业属性提取;企业属性是从企业基础信息、企业工商信息、征信信息、交易信息、税务信息、涉诉信息中提取刻画企业风险的数据维度,共提取了56个属性;
50、s422、干系人属性提取;在企业干系人的处理上,实际控制人和其他干系人是分开处理的;实际控制人和企业的关系是一对一,而且实际控制人对于企业的影响更大,直接将实际控制人属性和企业属性做拼接,形成属性宽表。而其他干系人和企业的关系是多对一的,对其他干系人的属性做了聚合操作,根据属性性质不同选用不同的聚合方法,包括了取最大值、最小值、中位数、众数、均值、求和等方式,共提取了43个属性。
51、作为本发明再进一步的方案:s5的具体流程如下:
52、使用lightgbm方法进行构建模型,在构建过程中需要将企业特征数据集输入到lightgbm模型,然后对模型进行训练优化,并对模型从准确率和泛化能力两个方面进行评估;
53、s51、lightgbm概述
54、lightgbm是一种基于梯度提升框架的机器学习算法,采用了集成学习方法,通过训练多个弱学习器来构建一个强大的模型,用于解决回归和分类问题;
55、在解决传统gbdt中效率低下问题时,lightgbm引进goss和efb两种算法得以在保持模型效果的前提下提升了计算的效率;
56、s52、反欺诈模型测试
57、在对模型稳定性和泛化能力评估上,使用oot(out-of-timetesting)测试方法和交叉验证的方法;在评估模型区分能力时选用了auc和ks指标。
58、作为本发明再进一步的方案:goss算法具体包括:
59、goss是一种在减少数据量且能保证精度的平衡算法;goss是通过区分不同梯度的实例,保留较大梯度实例同时对较小梯度随机采样的方式减少计算量,从而达到提升效率的目的;goss工作的流程如下:
60、输入:训练数据,迭代步数d,大梯度数据的采样率a,小梯度数据的采样率b,损失函数和弱学习器的类型选用决策树;
61、输出:训练好地强学习器;
62、(1)根据样本点的梯度的绝对值对它们进行降序排序;
63、(2)对排序后的结果选取前a*100的样本生成一个大梯度样本点的子集;
64、(3)对剩下的样本集合(1-a)100的样本,随机地选取b(1-a)*100个样本点,生成一个小梯度样本点的集合;
65、(4)将大梯度样本和采样的小梯度样本合并;
66、(5)将小梯度样本乘上一个权重系数;
67、(6)使用上述的采样的样本,学习一个新的弱学习器;
68、(7)不断地重复(1)~(6)步骤直到达到规定的迭代次数或者收敛为止。
69、作为本发明再进一步的方案:efb算法具体包括:
70、efb是通过特征捆绑的方式减少特征维度,其实就是一种降维技术,来提升计算效率;efb算法的步骤如下:
71、1)将特征按照非零值的个数进行排序;
72、2)计算不同特征之间的冲突比率;
73、3)遍历每个特征并尝试合并特征,使冲突比率最小化;
74、s52lightgbm算法优化
75、使用python第三方库lightgbm所提供的算法进行模型的训练;在训练过程中从模型准确率、效率、泛化能力等方面进行参数优化;其中在准确率方面包含的参数有num_leaves,learning_rate;在效率方面包的参数有:bagging_fraction,feature_fraction,max_bin,save_binary。在泛化能力方面的参数有:lambda_l1,min_data_in_leaf,max_depth。
76、本发明的有益效果是:
77、1.本发明为企业申请贷款的反欺诈检测提供了一套可行的操作方法,拓展了金融机构在反欺诈领域的解决方案,帮助银行提供更加高效、可靠的金融服务。
78、2.在技术效果方面,本发明通过构建关系图谱提取图特征信息,结合企业属性特征进行建模,增加了模型的效果。本发明所训练的反欺诈检测模型相较于仅仅使用企业属性的训练模型在准确率和泛化能力都有所提升,ks达到0.52,auc达到了0.82。
79、3.该发明帮助金融机构降低了信贷风险,减少欺诈行为对金融体系的损害。这有助于减少不良贷款的数量,提高信贷业务质量,减少了债务违约的风险,提高了银行的盈利能力和稳定性。
- 还没有人留言评论。精彩留言会获得点赞!