一种基于机器学习的物流信息查询方法、装置及系统与流程
本发明涉及物流,尤其是涉及到一种基于机器学习的物流信息查询方法、装置及系统。
背景技术:
1、现有技术中利用自然语言直接查询物流信息系统存在词汇覆盖面有限的问题。因为物流信息系统中的数据结构和字段都是事先定义好的,与自然语言的表达存在差距。这会导致使用自然语言作为查询时无法准确匹配查询意图和物流信息系统中的数据,无法获取到完整且准确的物流信息。
2、我们注意到生成对抗网络可以通过对抗训练的方式获得查询物流信息系统的内在映射特征,实现从无标注数据到产生逼真物流信息的过程。生成对抗网络的生成器学习到编码真实分布信息的潜在表示。这样,生成对抗网络可以不依赖自然语言的表达,直接建模物流信息系统中的模式,产生信息查询所需的关键数据特征,从而实现准确查询。
3、此外,结合注意力机制的生成对抗网络可以在训练过程中关注物流信息中的关键字段,对比号、地点、状态等最重要的特征。注意力机制使得生成的信息更加真实,也增强了判别器正确判断真伪信息的能力。最终形成的查询系统可以更加精确地捕捉信息特征,实现对物流信息的准确无偏查询。
4、所以,利用生成对抗学习尤其是注意力机制的生成对抗网络,可以有效解决现有技术中利用自然语言直接查询的词汇匹配有限,查询结果不准确的问题。
5、鉴于此,我们提出了一种基于机器学习的物流信息查询方法、装置、及系统。
技术实现思路
1、鉴于现有技术中利用自然语言进行物流信息查询中的问题,本发明提供了一种基于机器学习的物流信息查询方法,具体包括如下步骤:
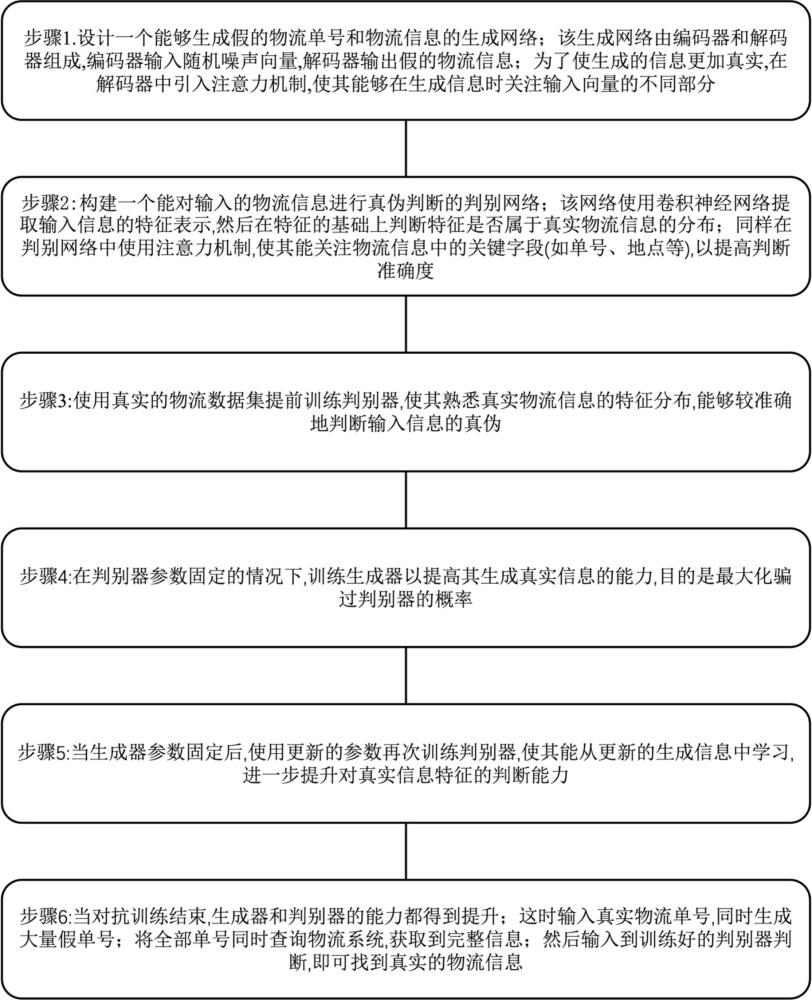
2、步骤1:设计一个能够生成假的物流单号和物流信息的生成网络;该生成网络由编码器和解码器组成,编码器输入随机噪声向量,解码器输出假的物流信息;为了使生成的信息更加真实,在解码器中引入注意力机制,使其能够在生成信息时关注输入向量的不同部分。
3、具体包括如下步骤:
4、步骤1.1:生成网络的输入为随机噪声向量z,其中每个元素服从高斯分布或均匀分布;生成网络的输出为假的物流信息,其中包含m个字段,每个字段用一个向量xi表示,即生成网络输出为向量序列(x1,x2,...,xm);
5、步骤1.2:编码器结构设计 编码器由多层全连接层组成,每层使用relu激活函数;第l层编码器的变换公式如下:hl = relu(wlh(l-1)+bl) 其中wl和bl分别为第l层的权重矩阵和偏置向量;编码器的最后一层输出即为映射到隐空间的向量h;
6、步骤1.3:对于解码器的第i步,定义注意力权重:αi,j = softmax(vttanh(w1hi+w2hj)) 其中v, w1和w2为学习的参数;注意力权重反映了解码器在当前步关注输入向量h的不同部分;
7、步骤1.4:基于注意力机制,解码器在第i步的输入为:ci = σjαi,jhj 解码器将ci通过多层网络映射为输出向量xi;
8、步骤1.5:生成网络的优化目标为最小化所生成物流信息被判别器判断为假的概率,即最小化交叉熵损失。
9、步骤2:构建一个能对输入的物流信息进行真伪判断的判别网络;该网络使用卷积神经网络提取输入信息的特征表示,然后在特征的基础上判断特征是否属于真实物流信息的分布;同样在判别网络中使用注意力机制,使其能关注物流信息中的关键字段(如单号、地点等),以提高判断准确度。
10、具体包括如下步骤:
11、步骤2.1:判别网络的输入为物流信息,包含m个字段,每个字段是一个向量;输入记为(x1,x2,...,xm),判别网络输出一个概率p∈[0,1],表示输入信息被判断为真实物流信息的概率;
12、步骤2.2:判别网络使用卷积神经网络提取输入各字段的特征;对第i个字段xi,通过卷积层提取特征:fi = relu(conv(xi)) 其中conv表示卷积操作;
13、步骤2.3:定义注意力权重:βi = softmax(uttanh(wfi + b)) 其中u,w,b为学习参数;注意力权重反映了不同字段对判断结果的重要性;最终得到特征融合:f = σiβifi;
14、步骤2.4:得到融合特征f后,通过多层全连接网络得到真伪概率:p = sigmoid(w'f + b'),其中w'和b'为全连接层参数;真伪判断的优化目标是最大化判断正确的对数似然。
15、步骤3:使用真实的物流数据集提前训练判别器,使其熟悉真实物流信息的特征分布,能够较准确地判断输入信息的真伪。
16、具体包括如下步骤:
17、步骤3.1:收集大量真实的物流单号和物流信息,构建判别器的训练数据集;数据集包括输入字段:(单号、地点、状态等),以及标签(真/假);
18、步骤3.2:初始化判别网络中的卷积层、全连接层等所有的权重矩阵和偏置向量;权重矩阵初始化为小的随机数,偏置向量初始化为0;
19、步骤3.3:判别器的训练目标是最大化判断真实物流信息为真的概率,同时最大化判断假的信息为假的概率;损失函数定义为二元交叉熵损失:l = -[ylogp + (1-y)log(1-p)] 其中y为真实标签,p为判断结果;
20、步骤3.4:使用rmsprop自适应学习率的优化算法来更新判别器中的参数,通过梯度下降法不断减小损失函数,优化判别效果;
21、步骤3.5:设置训练的early stopping策略;当模型在验证集上的指标(如accuracy)连续n个epoch不再改善,则终止训练,避免过拟合,保存效果最好的模型参数。
22、步骤4:在判别器参数固定的情况下,训练生成器以提高其生成真实信息的能力,目的是最大化骗过判别器的概率。
23、具体包括如下步骤:
24、步骤4.1:在判别器的参数(卷积层和全连接层权重)不变的情况下,只优化生成器的参数;
25、步骤4.2:生成网络的目标是生成逼真的假信息来欺骗判别器;因此其损失函数定义为:l_g = -log(d(g(z))) 其中g表示生成器模型,d表示判别器模型,z是生成器的随机噪声输入;损失函数表示最大化欺骗判别器判断为真实的概率;
26、步骤4.3:将随机噪声向量输入生成器生成假的物流信息,然后将这些假信息输入判别器计算生成器损失函数l_g;基于l_g通过梯度下降更新生成器中的编码器和解码器的模型参数,最小化l_g,优化生成逼真假信息的能力。
27、步骤5:当生成器参数固定后,使用更新的参数再次训练判别器,使其能从更新的生成信息中学习,进一步提升对真实信息特征的判断能力。
28、具体包括如下步骤:
29、步骤5.1:在生成器的模型参数固定的条件下,只优化判别器中的参数;
30、步骤5.2:使用在步骤4中优化过的参数的生成器,输入随机噪声生成新的假的物流数据;
31、步骤5.3:将生成器生成的新的假数据与真实物流数据组合,构建判别器的新训练集,用于重新训练;
32、步骤5.4:使用步骤5.3构建的包含真假数据的新训练集,对判别器所有的网络层参数进行更新优化,最大化判断真实和假数据的能力。
33、步骤6:当对抗训练结束,生成器和判别器的能力都得到提升;这时输入真实物流单号,同时生成大量假单号;将全部单号同时查询物流系统,获取到完整信息;然后输入到训练好的判别器判断,即可找到真实的物流信息。
34、具体包括如下步骤:
35、步骤6.1:在查询时,提供真实需要查询物流信息的单号,记为id_real;
36、步骤6.2:使用随机函数生成n个假的物流单号,记为{id_fake1, id_fake2,...,id_faken};
37、步骤6.3:将以上n+1个真假单号组合在一起,同时查询物流信息系统,获取每一个单号对应的完整物流信息;
38、步骤6.4:将查询获得的包含真假数据的物流信息集合同时输入到预先训练好的判别器中;判别器会输出每个信息属于真实物流的概率;
39、步骤6.5:对判别器输出的n+1个真实概率进行比较,概率值最高的即对应真实物流单号id_real的信息,这样完成了正确的物流信息查询。
40、本发明还提出了一种基于机器学习的物流信息查询装置,所述装置为提供查询界面的任何电子设备,所述电子设备用以执行上述物流信息查询方法。
41、本发明还提出了一种基于机器学习的物流信息查询系统,所述系统包括前端子系统,传输子系统以及后端子系统,所述前端子系统用来接收物流信息查询请求,所属传输子系统将所述物流信息查询请求传输至所述后端子系统,所述后端子系统用来执行如上述的物流信息查询方法,并将查询结果通过所述传输子系统传回到前端子系统。
- 还没有人留言评论。精彩留言会获得点赞!