字词频度统计方法及装置与流程
本发明涉及一种字词频度统计方法及装置,属于信息处理和数据统计的。
背景技术:
1、对字词频度的统计分析,尤其是在中文环境中,通过揭示汉语词汇的各种统计特性,可以使人们对每个汉字或词语在实际应用中的地位有一个比较清楚的认识,对于社会各个方面的汉语使用都具有很大的指导作用。比如,在少儿的语文教育、特殊人群的语言学习或者针对外国人的汉语教学中,课程要完成一定数量的字词教学任务,那么在一定的时期内应该完成哪些中文字词的学习才能达到预期效果,以解决最常用文字的阅读和使用,最大可能地掌握语言驾驭能力具有显而易见的作用;再如,在现代海量文本信息的处理中,为提高中文语境中字词检索的效率,往往也需要对中文字词的频度进行精准地统计,以便进一步生成相应的词云图、频率表等数据分析结果,这对于基于文本的全文检索效率以及互联网搜索引擎的检索效率均具有重大意义。以上举例的情景中,这就必须运用字词频度的统计成果作指导,增加其科学性和实用性,避免主观臆测。我国也早在20世纪20年代就进行过汉语词汇的统计研究,自70年代末以来,我国开始利用计算机进行汉语词汇的自动统计和分析,而且统计单位也从单字扩展到了词语,大大地提高了统计的效率和规模,将汉语词汇统计研究提高到一个新的水平,还以此为基础编制了各种频率词典、词表,并对现代汉语的常用字、常用词、构词规则等进行了多方面的研究。总之,在文本语料信息海量的情况下,如何以较少的算力资源消耗、快速获取字词频度统计结果是一项非常重要的工作。
2、目前,对于给定的字词集和语料库,统计字词集中每一单字和词语在整个语料库内所有文档文本中的出现次数,通常的技术解决思路是,将字词集中的每个单字和词语线性化地排列为相应条数的记录,然后针对字词集中的每个单字或词语,在语料库内的所有文档文本中检索其出现次数,最后汇总数据,导出作为统计对象的、字词集中每个单字或词语在整个语料库中出现次数的报表。为实现上述方案思路,一种典型的字词频度统计方法是,字词集所涉及的所有字词条目及其统计次数分别以字串数组和整型数组的线性结构存储,在进行字词频度的统计时,依次读取字串数组中存储的每一数组元素,即作为统计对象的字词集中的每一字词条目,并且对于每一字词条目,都需要遍历整个语料库中所有的文档文本一次,通过与文档文本内的字串进行对比的方法,统计出作为统计对象的一个字词条目在语料库中的出现总次数,直至字词集中的所有字词条目在整个语料库中各自出现总次数统计完毕,并将之记录在整型数组的对应位置作为任务输出结果,整型数组中每一数组元素分别代表字串数组对应位序存储的一个字词条目的出现次数,显然上述技术方案所消耗的时间复杂度t(m*n)=o(m*n),这里的m、n分别代表语料库和字词集的规模大小(下同),由于语料库的规模m和字词集的规模n通常都较大,因此字词频度统计的工作将十分繁重。作为本领域技术人员很容易想到的一种优化方案是,字词集所涉及的所有字词条目在字串数组中以字典顺序排列,在进行字词频度的统计时,在语料库中的所有文档文本内,由文档文本的首字符开始,依次读取各字符位置开始且不同长度的多个不同字串,然后针对所读取的每一个字串,均遍历整个字词集以读取其中的所有字词条目,当所读取的一个文档字串与字词集中的某个单字或词语匹配时,则该单字或词语对应的统计总次数加1,最终语料库中的所有文档文本读取完毕,字词频度统计工作也完成,由于在遍历字词集时,其中的所有字词条目以字典顺序方式排列,在字词集中完全可以采取折半查找的方式进行匹配运算,这使得字词频度统计的整体效率有了提升,该进一步优化的技术解决方案所消耗的时间复杂度从而由t(m*n)=o(m*n)降低为t(m*n)=o(m*log2n)。但其中的问题是,在实践中为了避免字词频度统计结果的片面性,语料库的规模m必须要远大于字词集的规模n,因此上述优化方案对于字词频度统计的效率改善非常有限。导致现有技术中前述两种典型解决方案效率不尽人意的原因,可以归结为字词集中各单字和词语存储结构的设计上,若能对其作出合理布局并针对性地采取更加合理的算法,字词频度统计效率仍存在较大的提高空间,这也正是提出本发明技术方案的出发点所在。
技术实现思路
1、本发明所要解决的技术问题是,对于给定的语料库和字词集,尤其是在二者数量规模较大的情况下,如何以较高的效率,统计字词集中每一字词条目在整个语料库中各自出现的总次数,其目的是在字词频度统计的技术领域提供一种较为满意的技术解决方案,以便进一步地将其应用于文字教学、字词检索等的相关技术领域。
2、为了解决上述提出的技术问题,本发明提供了一种字词频度统计方法和装置,并采取如下技术方案:
3、第一方面,本发明提供了一种字词频度统计方法,统计字词集中每一个字词条目在整个语料库中各自出现的总次数,所述方法包括:
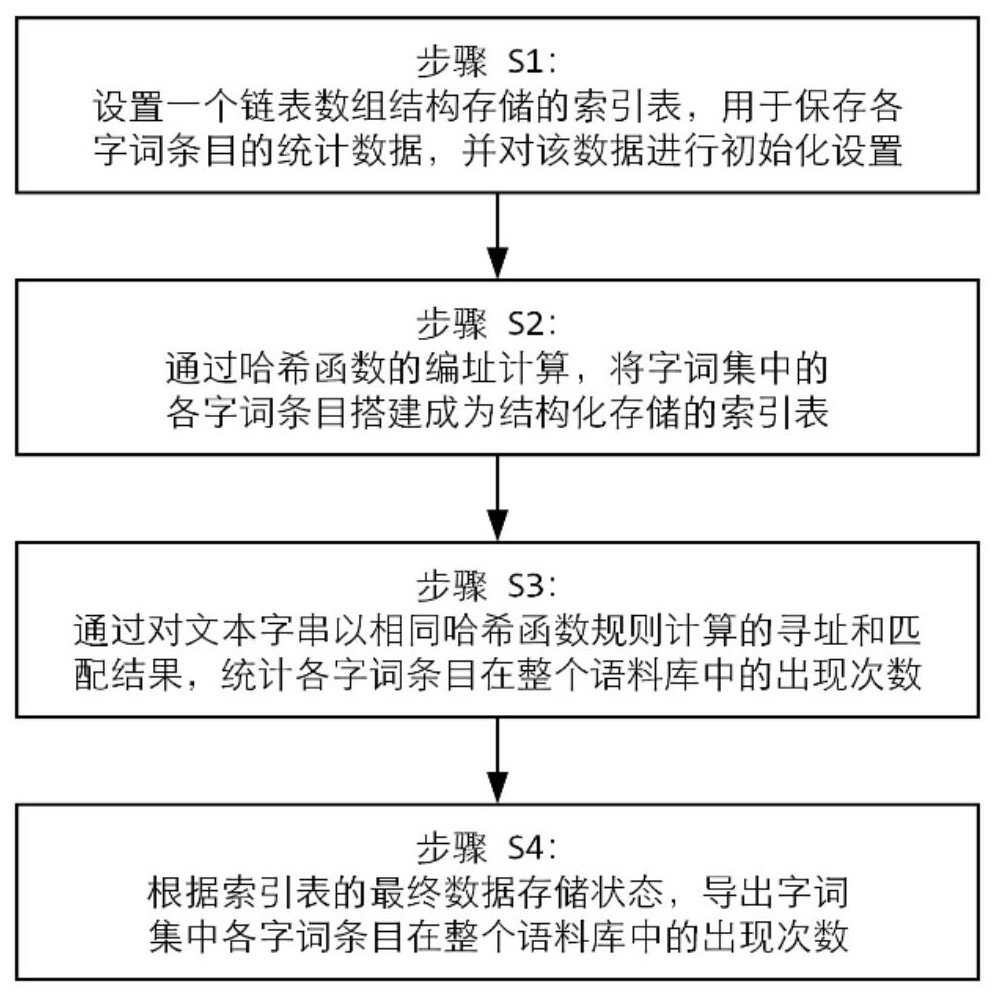
4、步骤s1:设置一个链表数组结构存储的索引表index[],其中每个数组元素均对应存储一个线性链表的头指针并初始化取值为null,所述线性链表内的各结点均包括用于存储所述字词集中所述一个字词条目的字串s、用于存储所述一个字词条目在所述整个语料库中出现次数的数值t和当前结点之后继结点存储位置的指针n这三个域;
5、步骤s2:针对所述字词集中的所述每一个字词条目,首先利用哈希函数计算其码值c1,然后新创建一个结点并将该结点的字串域s赋值为所述一个字词条目、数值域t赋值为0,最后将该结点插入由数组元素index[c1]所指示的一条线性链表中,所述哈希函数为c1=hash(u1,u2,u3……ui),式中c1为非负整数,i为所述一个字词条目构成中的字符数量,i的最大值即所述字词集中每一字词条目内字符构成数量的最大值记为l,u1、u2、u3……ui为所述一个字词条目内依次构成中各字符表示的二进制unicode编码中部分数位所对应的数值;
6、步骤s3:扫描所述整个语料库中每一文件的文本,针对其中连续字符构成数量不超过所述l的所有文本字串,首先利用与前面相同的哈希函数规则,计算这些文本字串的非负整数码值c2,然后针对其中每一文本字串及其对应计算的码值c2,均依次读取数组元素index[c2]所指示一个线性链表中的各结点,若结点中s域内的字串与该每一文本字串对比完全相同,则该结点中的t域数值增加1;
7、步骤s4:针对所述索引表index[]中各非null值数组元素所指示的线性链表,依次读取并输出其中每一结点内的s域字串和t域数值,其中s域字串构成作为频度统计对象的所述一个字词条目,t域数值对应构成其在所述整个语料库中出现的总次数。
8、优选地,所述索引表index[]的下标编址范围为0~65535,所述c1和所述c2均为大于等于0且小于65536的整数,所述步骤s2中二进制unicode编码中部分数位所对应的数值为所述二进制unicode编码中低16位所对应的数值。
9、优选地,所述c1=hash(u1,u2,u3……ui)的计算规则是c1=u1+u2+u3+……+ui,并且当由该计算规则所计算产生的结果值大于或等于2^16时,则c1调整取值为所述结果值的二进制数值表示中低16位数所对应的数值。
10、优选地,所述c1=hash(u1,u2,u3……ui)的计算规则是c1=|u1-u2-u3-……-ui|,或者c1=|ui-ui-1-ui-2-……-u1|,并且当由该计算规则所计算产生的结果值大于或等于2^16时,则c1调整取值为所述结果值的二进制数值表示中低16位数所对应的数值。
11、优选地,所述步骤s2中将该结点插入由数组元素index[c1]所指示的一条线性链表中,其插入方法是,先将该结点中的n指针域赋值为数组元素index[c1]的数值,然后将数组元素index[c1]的数值更新为该结点在新创建时所产生的自身保存位置的指针数值。
12、优选地,在所述步骤s2和所述步骤s3中,还包括字符编码形式转换的子步骤:在利用所述哈希函数计算所述每一个字词条目的码值c1之前以及在利用所述哈希函数计算所述其中每一文本字串的码值c2之前,将所述每一个字词条目和所述其中每一文本字串中所涉各字符的编码,由其他非unicode形式的编码转化为unicode形式的编码。
13、优选地,在所述步骤s4中,还包括计算字词条目频度百分数的子步骤:针对所述字词集中的所述每一个字词条目,将其在所述整个语料库中的出现总次数,除以所述整个语料库中的字符总数,以计算出字词集中每一个字词条目在整个语料库中出现频度的百分数。
14、第二方面,本发明提供了一种字词频度统计装置,统计字词集中每一个字词条目在整个语料库中各自出现的总次数,所述装置包括:
15、模块m1,用于:设置一个链表数组结构存储的索引表index[],其中每个数组元素均对应存储一个线性链表的头指针并初始化取值为null,所述线性链表内的各结点均包括用于存储所述字词集中所述一个字词条目的字串s、用于存储所述一个字词条目在所述整个语料库中出现次数的数值t和当前结点之后继结点存储位置的指针n这三个域;
16、模块m2,用于:针对所述字词集中的所述每一个字词条目,首先利用哈希函数计算其码值c1,然后新创建一个结点并将该结点的字串域s赋值为所述一个字词条目、数值域t赋值为0,最后将该结点插入由数组元素index[c1]所指示的一条线性链表中,所述哈希函数为c1=hash(u1,u2,u3……ui),式中c1为非负整数,i为所述一个字词条目构成中的字符数量,i的最大值即所述字词集中每一字词条目内字符构成数量的最大值记为l,u1、u2、u3……ui为所述一个字词条目内依次构成中各字符表示的二进制unicode编码中部分数位所对应的数值;
17、模块m3,用于:扫描所述整个语料库中每一文件的文本,针对其中连续字符构成数量不超过所述l的所有文本字串,首先利用与前面相同的哈希函数规则,计算这些文本字串的非负整数码值c2,然后针对其中每一文本字串及其对应计算的码值c2,均依次读取数组元素index[c2]所指示一个线性链表中的各结点,若结点中s域内的字串与该每一文本字串对比完全相同,则该结点中的t域数值增加1;
18、模块m4,用于:针对所述索引表index[]中各非null值数组元素所指示的线性链表,依次读取并输出其中每一结点内的s域字串和t域数值,其中s域字串构成作为频度统计对象的所述一个字词条目,t域数值对应构成其在所述整个语料库中出现的总次数。
19、优选地,在所述模块m2和所述模块m3中,还包括字符编码形式转换的子模块,用于:在利用所述哈希函数计算所述每一个字词条目的码值c1之前以及在利用所述哈希函数计算所述其中每一文本字串的码值c2之前,将所述每一个字词条目和所述其中每一文本字串中所涉各字符的编码,由其他非unicode形式的编码转化为unicode形式的编码。
20、优选地,在所述模块m4中,还包括计算字词条目频度百分数的子模块,用于:针对所述字词集中的所述每一个字词条目,将其在所述整个语料库中的出现总次数,除以所述整个语料库中的字符总数,以计算出字词集中每一个字词条目在整个语料库中出现频度的百分数。
21、本发明的技术方案所产生的有益效果,如下所述:
22、在字词频度统计的技术方案设计中,对整个语料库的遍历过程通常是在所难免的,其技术方案设计的效率优化方向,可以是对字词集中每一字词条目的索引或定位策略上,即针对将在语料库中发现存在的字词统计条目,如何找到保存其出现总次数的数据保存位置即寻址方式,这是影响检索效率的一个重要因素。在现有技术中,通过逐一查找或折半查找的方式对字词集中的每一字词条目进行定位;而在本发明中,将字词集中的所有字词条目通过哈希函数规则结构化地搭建成为一个索引表,在遍历读取语料库中各文件内的文本时,对于扫描形成的每一文本字串,利用相同的哈希函数规则产生数据元素的寻址位置并由此直接读取索引表中相应位置一个链表,然后在该链表内有限数量的结点中查找作为统计对象的一个字词条目,并且在哈希函数计算时,直接利用所涉字符自身在计算机保存中所天然使用的unicode编码信息,实现由字词集中的字词条目或文件中的文本字串到索引表中特定一个线性链表的直接映射,由于寻址效率的提高,相对于现有技术,本发明技术方案的字词频度统计效率也相应地有所提高。
23、在本发明提出的技术方案中,对于在语料库中各文件的文本内所读取的每一个文本字串而言,当将之与字词集中作为统计对象的所有字词条目进行匹配的遍历中,无需逐一条目地查找,而是利用每一文本字串自身所天然携带的编码信息再结合哈希函数计算,对字词集索引表中特定位置的某个字词条目进行快速读取,即使由文本字串所直接映射的一个链表内的结点数量可能非唯一,但其总数量也是有限的,因此本发明的技术方案可将字词频度统计方法的时间复杂度t(m*n),由现有技术中的o(m*n)或o(m*log2n)降低为o(m),本发明的技术方案也将特别适合于字词集中字词条目数量较多、语料库规模较大情形下对字词频度进行统计的应用场景,也更具实际价值意义。
- 还没有人留言评论。精彩留言会获得点赞!