一种水环境在线监测数据真伪智能识别系统及方法与流程
本发明涉及水环境监管,具体涉及一种水环境在线监测数据真伪智能识别系统及方法。
背景技术:
1、环境监测数据是客观评价环境质量状况、反映污染治理成效、实施环境管理与决策的基本依据,是推进生态文明建设和生态环境保护的重要支撑,然而近年来生态环境监测数据弄虚作假行为频发。但监测数据造假手段花样百出、狡猾隐蔽,仅依靠人工很难察觉,且目前生态环境监测数据造假智能识别技术尚处于摸索阶段。
2、目前主要有两种识别在线监测数据造假行为的手段。
3、第一,人工异常巡查。依靠大量人工对在线监测数据进行异常巡查,并对相关企业的环评报告、自动监控验收文件、检测报告等文件进行复查,寻找蛛丝马迹。
4、第二,设备参数监控。通过对在线监控数据、现场设备运行参数数据、现场设备运行状态数据、现场情况影像监控数据的收集和监控,查看设备参数有无修改来发现数据造假行为。
5、但是,人工异常巡查手段需要依靠数据管理员每日进行数据监管平台线上巡查,耗时耗力,且容易忽略隐蔽的数据造假行为,效率低下;设备参数监控手段主要针对通过修改设备运行参数伪造监测数据的数据造假行为,仅可以屏蔽80%左右的参数修改造假行为,且无法捕捉篡改设备运行参数以外的数据弄虚作假行为。
技术实现思路
1、本发明的目的在于提供一种水环境在线监测数据真伪智能识别系统及方法,解决以下技术问题:
2、如何提供一种能够对水环境检测数据进行有效且高效真伪识别的智能识别系统。
3、本发明的目的可以通过以下技术方案实现:
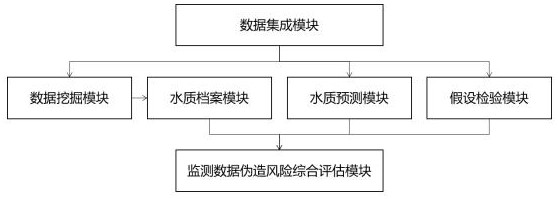
4、一种水环境在线监测数据真伪智能识别系统,包括:
5、数据集成模块,用于水质数据和气象数据的数据接入、数据清洗转换打宽以及数据入仓入湖;
6、其中,水质数据包括氨氮、总磷、化学需氧量、高锰酸盐指数水质指标浓度,气象数据包括降雨量、气温、风速;
7、其中,所述数据清洗包括识别和删除重复信息、处理无效值和缺失值,所述数据转换包括数据值域转换、数据粒度转换和属性构造,所述数据打宽是将同一水质监测对象的水质数据与多源气象数据进行关联匹配;
8、数据挖掘模块,与所述数据集成模块连接,用于根据指定标准规范对监测对象的水质历史监测数据进行分析,基于时间序列分解模型找出水质演变规律,挖掘各水质指标之间的关联规则,并将关于所述监测对象的探索结果上传至水质档案模块;
9、所述水质档案模块,与所述数据挖掘模块连接,用于接受所述探索结果,将河流、湖库、污染源等的水质现状和演变规律以及水质指标之间的关联规则保存到nosql数据库,形成监测对象的水质档案;所述水质档案定期更新,以供即时查看;
10、水质预测模块,与所述数据集成模块连接,用于对监测对象的未来水质进行预测,划定水质的理论预期范围;
11、假设检验模块,与所述数据集成模块连接,用于检验所述水质数据是否存在造假行为;
12、监测数据伪造风险综合评估模块,与所述水质档案模块、所述水质预测模块和所述假设检验模块连接,用于根据所述水质档案模块、所述水质预测模块、所述假设检验模块的分析结果,综合评估水质监测数据伪造风险。
13、作为本发明进一步的方案:一种水环境在线监测数据真伪智能识别方法,包括:
14、进行水质数据和气象数据的数据接入、数据清洗转换打宽以及数据入仓入湖;
15、其中,水质数据包括氨氮、总磷、化学需氧量、高锰酸盐指数等水质指标浓度,气象数据包括降雨量、气温、风速等;
16、其中,所述数据清洗包括识别和删除重复信息、处理无效值和缺失值,所述数据转换包括数据值域转换、数据粒度转换和属性构造,所述数据打宽是将同一水质监测对象的水质数据与多源气象数据进行关联匹配;
17、根据指定标准规范对监测对象的水质历史监测数据进行分析,基于时间序列分解模型找出水质演变规律,挖掘各水质指标之间的关联规则,并将关于所述监测对象的探索结果上传至水质档案模块;
18、根据所述探索结果,将河流、湖库、污染源等的水质现状和演变规律以及水质指标之间的关联规则保存到nosql数据库,形成监测对象的水质档案;定期更新所述水质档案,以供即时查看;
19、对监测对象的未来水质进行预测,划定水质的理论预期范围;
20、检验所述水质数据是否存在造假行为;
21、根据所述水质档案模块、所述水质预测模块、所述假设检验模块的分析结果,综合评估水质监测数据伪造风险。
22、作为本发明进一步的方案:所述基于时间序列分解模型找出水质演变规律的方法包括:
23、获取指定污染物浓度的浓度时间序列;
24、根据公式将所述污染物的所述浓度时间序列分解为三部分;
25、其中,为长期趋势项,用来刻画污染物浓度明显的递增或递减的长期趋势;为季节项,用来刻画每年相同季节污染物浓度的相同幅度和方向的稳定的周期变化;为不规则变动,用来刻画不可预期的偶然因素对污染物浓度的影响。
26、作为本发明进一步的方案:所述挖掘各水质指标之间的关联规则的方法包括:
27、获取n种污染物浓度之间的关联度,将第 k种污染物浓度时间序列记为;
28、根据公式:,计算得到第i种污染物浓度和第种污染物浓度的简单相关系数;
29、其中,为与的协方差,为的方差,为的方差;
30、根据公式,计算得到排除第h种污染物影响后第i种污染物浓度和第种污染物浓度的相关系数;
31、根据公式,计算得到排除第h种和第m种污染物影响后第i种污染物和第种污染物浓度的相关系数。
32、作为本发明进一步的方案:所述检验所述水质数据是否存在造假行为的方法包括:
33、根据benford定律的表达公式,计算首位有效数字所出现的概率;
34、统计监测对象水质监测数据中1-9作为首位有效数字所出现的频率,记为;
35、利用公式,计算得到数据造假风险系数,若大于阈值,则认为数据不符合benford定律,存在数据造假的可能性较大;否则认为数据符合benford定律,数据为自然生成,没有经过人工修饰。
36、作为本发明进一步的方案:所述检验所述水质数据是否存在造假行为的方法包括:
37、利用公式,计算得到数据造假比例dfr;其中,dfr的取值范围为,dfr的值越大表示数据造假相对规模越大。
38、作为本发明进一步的方案:所述根据所述水质档案模块、所述水质预测模块、所述假设检验模块的分析结果,综合评估水质监测数据伪造风险的方法包括:
39、根据以下3个条件建立水质在线监测数据弄虚作假3级风险预警:
40、条件一:根据所述水质档案判断数据指标范围是否正常,业务特征数据关联是否合理;
41、条件二:比对基于融合集成多源数据和lstm的水质预测模型给出的预测值与实时监测值的差异,判断监测数据是否满足预期数据模型;
42、条件三:根据benford定律假设检验结果,判断存在数据造假的可能性;
43、若不满足条件的数量为1,则为低风险;
44、若不满足条件的数量为2,则为中风险;
45、若不满足条件的数量为3,则为高风险。
46、本发明的有益效果:本发明中数据挖掘模块和水质档案模块通过对水质在线监测大数据进行深度分析,发现数据中隐藏的模式和关系,将原始数据转化为对监测对象水质系统科学的认知,形成监测对象的“水质档案”。一方面,可助力水质在线监测数据弄虚作假行为智能识别;另一方面,使得相关管理人员能够随时查看和掌握排污单位、自然水体的水质现状及演变特征,从而对污染源及水环境进行科学治理。监测数据伪造风险综合评估模块通过有机结合水质档案模块、水质预测模块、假设检验模块的分析结果,综合评估水质在线监测数据伪造风险,并建立3级风险预警,克服了单一评估方法所得结果的偶然性,提高了评估结果的鲁棒性和可靠性,实现了水质在线监测数据造假智能识别和自动预警,为水环境执法检查提供技术支撑和决策支持,推进智慧环境监管体系逐步完善。
- 还没有人留言评论。精彩留言会获得点赞!