一种多种信息源的多模态大模型构建系统的制作方法
本发明属于人工智能,尤其涉及一种多种信息源的多模态大模型构建系统。
背景技术:
1、模态是指一些表达或感知事物的方式,每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉,听觉,视觉,嗅觉;信息的媒介,有语音、视频、文字等;多种多样的传感器,如雷达、红外、加速度计等。以上的每一种都可以称为一种模态。
2、相较于图像、语音、文本等多媒体(multi-media)数据划分形式,“模态”是一个更为细粒度的概念,同一媒介下可存在不同的模态。例如,可以把两种不同的语言当做是两种模态,甚至在两种不同情况下采集到的数据集,亦可认为是两种模态。多模态即是从多个模态表达或感知事物,区别于以往人工智能大模型大部分采用了纯文字形式进行构建的方式,多模态机器学习则是从包括多种模态的数据中学习并且提升大模型自身的算法。这其中涉及多模态数据的表征、翻译、对齐、融合以及协同学习,目前相关领域急切需要提出更为高效以及兼容性更强的多模态大模型构建方法以及构建系统的技术方案,以进一步发展人工智能的更多应用。
3、根据已公开的技术方案,公告号为cn107340859b的技术方案提出一种多模态虚拟机器人的多模态交互方法,其通过识别用户输入的多模态信息并以三维的虚拟形象进行信息的反馈以形成与用户的互动;公开号为wo2023277722a1的技术方案提出一种多模态神经网络模型,通过设置有多模态神经网络设置编码器、解码器等功能单元,使得各种模态的信息可以被分别处理并进行高效融合;公开号为us20230125036a1的技术方案提出一种处理用户多模态输入的交互系统,用户可以采用多种模态作为向系统输入指令的方式,并由交互系统处理这些用户输入后对后端的应用程序进行控制以实现用户的指令。
4、以上技术方案均提出应用能处理多模态输入的模型的应用方式,但对于这种能处理多模态信息的大模型的构建方式以及训练方式,目前提及的技术方案不到,并且无法进行更广泛的推广应用。因此尚需要提出更为有效的构建技术方案。
5、背景技术的前述论述仅意图便于理解本发明。此论述并不认可或承认提及的材料中的任一种公共常识的一部分。
技术实现思路
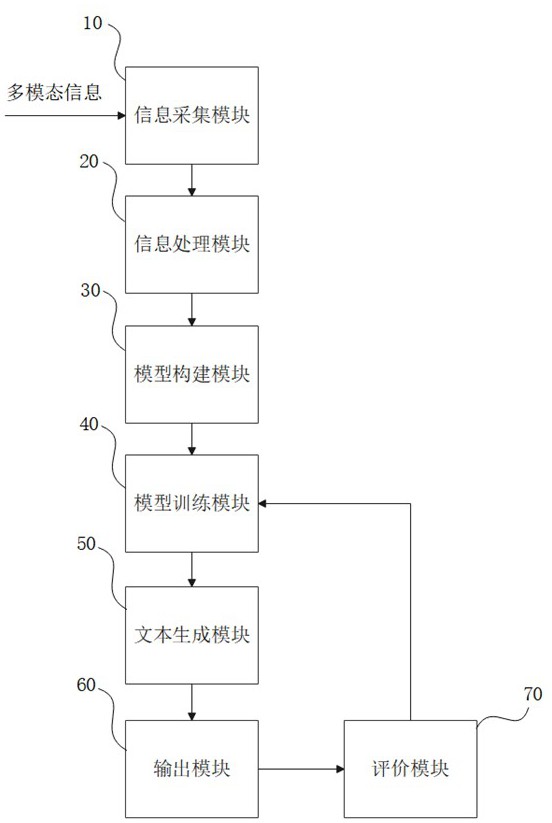
1、本发明的目的在于,公开了一种多种信息源的多模态大模型构建系统,属于人工智能技术领域。所述构建系统包括收集和处理目标人物的多种模态信息,并构建具备该目标人物语言语音特征的自生成式语音大模型。构建系统包括信息采集、处理、模型构建、训练、文本生成、输出和评价模块。通过模型的训练,使模型学习目标人物的语音、语言和情感特征,并生成模拟目标人物语言风格和情感特征的文本。同时,系统中的评价模块在训练过程中评价模型生成的语音和/或语言文本与目标人物特征的差异,并将评价结果反馈到模型训练模块优化模型,并最终获得满足用户要求的多模态大模型。
2、本发明采用如下技术方案:
3、一种多种信息源的多模态大模型构建系统,所述构建系统基于一个目标人物进行多模态信息的收集和处理,并构建具备所述目标人物的语言语音特征的自生成式语音大模型;所述构建系统包括:
4、信息采集模块,被配置为采集目标人物的多种模态信息,所述多种模态信息包括语音信息、图像信息和文本信息;
5、信息处理模块,被配置为对所述多模态信息进行预处理,所述预处理包括语音识别、图像分类、文本分词、情感特征识别,并对每个特征的表现的进行数值量化,获得预处理信息;
6、模型构建模块,被配置为基于所述预处理信息构建初始模型;
7、模型训练模块,被配置为训练所述初始模型,通过训练使所述初始模型学习目标人物的语音、语言和情感特征,从而获得一个或以上的预训练模型;
8、文本生成模块,被配置为利用所述预训练模型生成模拟目标人物语言风格和情感特征的文本;
9、输出模块,被配置为使用语音合成技术,读出由所述文本生成模块所生成的文本;
10、其中,所述构建系统还包括:
11、评价模块,被配置为在模型训练过程中,评价所述预训练模型所生成的语音和/或语言文本与目标人物的特征的差异;其后,将评价结果反馈到所述模型训练模块,以减少所述预训练模型所生成的语音和/或语言文本与目标人物的特征的差异为目标,继续对所述预训练模型进行训练以优化预训练模型;
12、优选地,所述信息处理模块包括文本特征提取单元,所述文本特征提取单元被配置为对目标人物的语言文本进行分词,生成两两文本记录对,并提取文本特征,包括判断文本记录中的词元在配对记录中是否出现,以及词元的相似度分数等。
13、优选地,所述信息处理模块还包括语音特征提取单元,被配置为对目标人物的语音进行特征提取,获得语音特征;
14、其中,所述语音特征提取单元,包括
15、采用语音识别技术,获取语音的字面文本,用于分析目标人物的语音的以下一项或多项特征:音高特征、语速特征、语调特征、音色特征等语音参数;还包括
16、采用视频数据,使用唇形分析、口形匹配技术,提取目标人物的发音口形特征;
17、优选地,所述评价模块包括:
18、评价模型:用于评价所述预训练模型的生成内容;
19、模型训练单元,用于训练所述评价模型;
20、评分单元,用于针对目标人物语音样本,使用经训练的模型生成语音相似度分数;
21、优选地,所述评价模型由所述模型构建模块利用所提取的文本特征以及语音特征构建;并且,所述评价模型包括文本评价子模型和语音评价子模型;
22、其中,所述文本评价子模型以及所述语音评价子模型均包括采用卷积神经网络层次结构并包含跳跃连接;
23、优选地,所述评价模型包括将目标人物所具有的多个特征视为独立的变量,记为c1,c2, ..., ci,每个变量的数值对应于特征量化后的数值;
24、设定目标人物第i个特征ci的实际值为xi,由所述评价模型计算一个预训练模型的生成内容中该特征ci的评价值为yi;定义一个函数l如下:
25、;
26、上式中,wi为对应于特征ci的权重值,在所述预训练模型的训练过程中不断优化后设定;w0_i为由用户根据自身对特征ci的关注程度进行自定义;λ1和λ2为正则化参数;
27、通过在训练所述预训练模型中找到一组权重值w1,w2,...,wi,使得函数l的数值尽可能小;并且进一步通过正则化参数λ1和λ2的调整,使函数l具备足够泛化能力,并且使所述预训练模型具备生成的内容满足用户对其中一个或多个特征的偏好的能力;
28、进一步的,提出一种多种信息源的多模态大模型构建方法;所述一种多种信息源的多模态大模型构建系统;所述构建方法包括以下步骤:
29、s100:采集目标人物的多种模态信息,所述多种模态信息包括语音信息、图像信息和文本信息;
30、s200:对所述多模态信息进行预处理,所述预处理包括语音识别、图像分类、文本分词、情感特征识别,并对每个特征的表现进行数值量化,获得预处理信息;
31、s300:基于所述预处理信息构建初始模型;
32、s400:训练所述初始模型,通过训练使所述初始模型学习目标人物的语音、语言和情感特征,从而获得一个或以上的预训练模型;
33、s500:利用所述预训练模型生成模拟目标人物语言风格和情感特征的文本;
34、并且,还包括采用以下步骤用于验证和优化所述预训练模型,以获得合乎用户要求的多模态大模型;
35、s600:使用语音合成技术,读出由所述文本生成模块所生成的文本;
36、s700:在模型训练过程中,评价所述预训练模型所生成的语音和/或语言文本与目标人物的特征的差异,其后,将评价结果反馈到所述模型训练模块,以减少所述预训练模型所生成的语音和/或语言文本与目标人物的特征的差异为目标,继续对所述预训练模型进行训练以优化预训练模型。
37、本发明所取得的有益效果是:
38、本发明的构建系统能够接收并处理多种模态的信息,例如语音、图像和文本,从而使所构建的大模型能够生成丰富的、多维度的人物特征表示;这种构建方式不仅能够更全面地理解和学习目标人物的特性,也可以在各种模态之间实现互补和增强,从而提升模型的生成质量和实用性;
39、本发明的构建系统通过设置评价模块,可以在训练过程中自我评价和调整模型性能;这种反馈机制使模型有能力自我优化和改进,大大提升了训练效率和模型质量;此外,自我优化机制也使模型具有良好的鲁棒性和泛化能力,能够应对各种复杂和变化的应用场景;
40、本发明的构建系统以及构建方法可以根据目标人物的具体特性进行高度自定义的训练和生成,使生成的文本能够准确模拟目标人物的语言风格和情感特征;这种高度自定义的能力使得所构建的大模型在各种个性化和定制化的应用场景中都具有很高的价值,例如虚拟助手、语音合成、智能客服等。
41、本发明的本发明的管理系统中各软、硬件部分采用了模块化设计,方便今后的升级或者更换相关的软、硬件环境,降低了使用的成本。
- 还没有人留言评论。精彩留言会获得点赞!