基于自然语言处理和深度学习的航空风险等级识别方法
本发明涉及持续适航风险管控,尤其涉及一种基于自然语言处理和深度学习的航空风险等级识别方法。
背景技术:
1、目前针对航空安全的应对策略通常有两种方案。方案一是通过提升飞机自身系统的可靠性来降低发生事故的概率。然而,航空系统是一个复杂的系统,航空安全不仅仅与飞机本身的系统相关,当发生事故时管制员的指令和飞机操作员的一系列补救操作与最终飞机安全密切相关。方案二是提升交通管制员和飞机操作人员的事故应对能力,即当事故发生时,交通管制员和飞机操作员需要根据当时现状立刻采取一系列补救措施,使得飞机脱离险境,然而这就需要航空人员拥有与不同事故对应响应的储备知识。
2、航空安全报告系统(asrs)是目前被广泛使用的、由世界各地的空中交通管制员、飞行员、航空局和机组人员自愿提交事故报告的解决方案。为了让航空人员能够针对性的根据不同风险类别事故进行系统性的学习,需要将这些报告进行分类。随着深度学习的快速发展,其在海量的数据中具备优秀的特征学习能力,一些学者尝试将其用于asrs报告分类。目前针对航空安全报告风险识别的算法较少,主要采用的包括支持向量机、卷积神经网络以及长短时记忆网络。asrs报告数据主要由结构型数据和非结构型数据组成,其中,结构型数据通常缺失大量数据,因此研究价值较低,而非结构化属性则是包含有关事故现场环境描述和飞机操作人员的相关操作的文本信息,基本没有数据缺失。因此,学者回去单独研究asrs报告的文本信息,其中最重要的部分则是文本信息词向量的表达能力。
3、目前,绝大部分针对文本信息的处理则是通过结合词编码技术进行解决,所采用的语言模型多为静态编码技术,如,word2vec,tf-idf和one-hot。然而,tf-idf虽然可以重视语料库中出现频率较多的词汇,但是却不能反应文本的上下文的信息,one-hot技术则会出现维度灾难和特征较为稀疏的问题。word2vec编码技术实际上就是做了一个查字典的操作,但是该方式不能区分多义词,因为每个词汇对应的编码是确定的,例如“这个飞行员水平太差”和“请将飞行高度维持在水平高度2500m以上”,其中“水平”虽然所表示的含义不一样,但是采用word2vec技术的编码是相同的,无法很好地表达句子的语义。此外,asrs报告还存在样本分布不平衡的问题,目前针对该问题采用的技术主要是上采样,即通过随机复制少数类样本以增强该类别数据的特征学习,然而该方式容易使得模型产生过拟合现象。
4、基于以上分析可知,由于航空是安全性极高的,因此高风险情况描述的航空安全报告较少,而通过简单的复制来处理样本不平衡方式,会使得模型发生过拟合的情况。因此需要一种能够为飞机操作人员和空中管制人员提供辅助决策,减轻asrs报告风险等级判定中航空专家的工作量。
技术实现思路
1、本发明的实施例提供一种基于自然语言处理和深度学习的航空风险等级识别方法,能够为飞机操作人员和空中管制人员提供辅助决策,减轻asrs报告风险等级判定中航空专家的工作量。
2、所提供的基于自然语言处理和深度学习的航空风险等级识别方法的大致方案,包括:
3、s1、获取asrs(航空安全报告系统)数据,所述asrs数据包括:结构型数据和文本型数据,所述结构型数据包括用于记载事件判定信息的result属性列,所述文本型数据包括用于事件全程的详细描述的narrative列和用于事件的简单总结的synopsis列;其中,结构型数据是”result”,其中包括34个事件判定信息,文本型数据包括”narrative”和”synopsis”两列,前者是事件全程的详细描述,后者是事件的简单总结。
4、s2、利用所述结构型数据对asrs数据进行风险等级划分,并得到风险等级标签;其中,利用所述结构型”result”属性中的事件判定信息将asrs数据进行风险等级划分,获取标签。
5、s3、将经过风险等级划分的asrs数据作为样本数据,并通过语义相似度模型(sbert),获取asrs数据中长文本内容的编码;
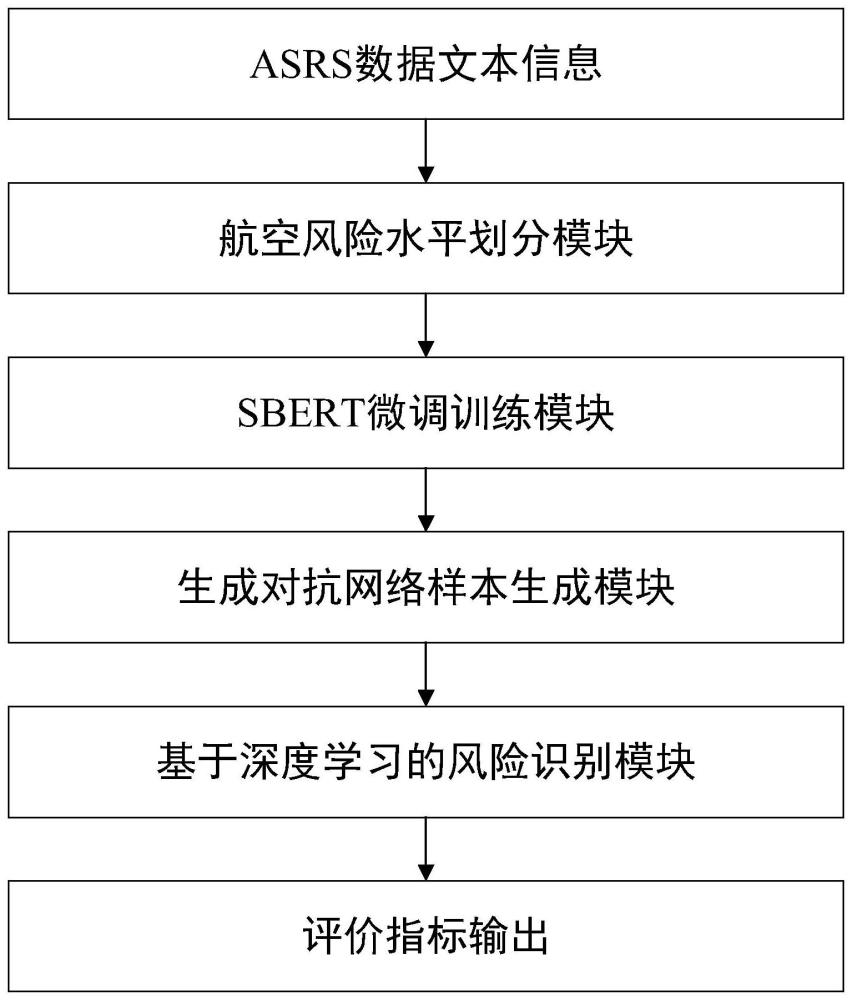
6、s4、利用所述样本数据构建航空风险识别模型,通过所述航空风险识别模型识别航空风险等级。例如:通过所述航空风险识别模型识别航空风险等级的具体方式,包括:创建风险等级标签。根据asrs报告中结构型数据中“result”属性的内容,将样本分为低风险、中等风险、中等风险、中等风险、中等高风险、高风险五个等级,并赋予相应的“1~5”标签。如图1。之后,sbert微调及语义编码。结合asrs报告中非结构型数据中的narrative列、synopsis列以及步骤1得到的标签label,将预训练的sbert模型进行微调。然后使用微调后的模型对asrs数据中的文本信息(narrative列、synopsis列)进行编码(将英文句子进行数字化)。然后,样本不平衡处理。由步骤1将数据进行标签化后发现样本存在不平衡问题,其中高风险水平和中低风险水平的样本数量明显少于其他风险水平类型的样本,这会造成风险识别模型对这两类样本的识别性能较低的情况。因此,需要对这两种风险水平类型的样本进行数据增强,本发明通过gan仿照这两类样本的真实数据,通过生成器生成近似这两种类型的样本,以解决样本不平衡问题。为了使得生成器和鉴别器适用于处理asrs中的文本信息,(文本是由单词或字符按照一定的顺序组成的,每个单词或字符都与前后的内容有关联。lstm可以利用其内部的状态和门结构,记忆和提取文本中的长期依赖关系,从而捕捉文本的语义和结构信息。)采用lstm和rnn构建生成器和鉴别器。数据增强之后,将整个数据集分为训练集、验证集和测试集8:1:1。接着特征学习。采用双向长短时记忆网络(bilstm)和注意力机制搭建风险识别模型的特征学习部分(主要是针对narrative和synopsis两列文本信息编码后的特征进行学习)。最后分类及验证。采用softmax函数完成分类任务,评判风险等级。最后,结合训练集、验证集和评价指标,对所提风险识别模型的性能进行验证。
7、本实施例中,在s2中,包括:将result属性列中的34个事件判定结果分为5个风险水平等级,包括:低风险、中低风险、中风险、中高风险和高风险,并依次设置对应每个风险水平等级的数字标签,比如“1~5”。
8、在s3中,所述通过语义相似度模型(sbert),获取asrs中长文本内容的编码,包括:构建基于sbert模型的微调训练模型,并通过所述微调训练模型对sbert模型进行微调;其中,采用asrs数据对语义相似度模型(sbert)进行微调,获取asrs中长文本内容的编码。通过微调后的sbert模型,获取asrs数据中的narrative列和synopsis列两各自的编码信息。所述构建基于sbert模型的微调训练模型,大致来说,可以包括将narrative列和synopsis列的文本信息作为输入,并进行平均池化操作得到句子向量;将所得到的句子向量输入softmax分类器中,得到相似度标签的概率分布;最后使用交叉熵损失函数来衡量预测分布和真实分布之间的差异,并更新sbert模型的模型参数。具体来说,则可以实现为a1-a10环节:
9、a1、导入所需的库,所述所需的库包括pandas、sentence_transformers和torch;
10、a2、加载预训练的sbert模型,所述预训练的sbert模型为基于minilm的句子嵌入模型all-minilm-l12-v2,用于生成高质量的句子向量;
11、a3、通过pandas库的read_csv读取asrs数据中的narrative列的文本信息、synopsis列的文本信息和标签列,并存储在一个dataframe对象中,所述标签列中记录风险等级标签;
12、a4、将asrs数据的每一行数据转换为inputexample对象,其中,通过sentence_transformers库提供的inputexample类创建对象,inputexample类接受每一行数据中的narrative列的文本信息、synopsis列的文本信息和标签列的信息作为输入参数;其中,遍历数据集的每一行,将每一行数据转换为inputexample对象,包含两个文本信息和一个标签。本发明使用sentence_transformers库提供的inputexample类来创建对象,该类接受两个文本信息和一个标签作为参数。本发明将所有的inputexample对象存储在一个列表中,以便后续处理。
13、a5、通过分词器对a4中的输入参数进行分词处理并添加特殊标记[cls]和[sep],之后采用sentence_transformers库提供的berttokenizer类创建分词器对象;其中,使用预训练的分词器对文本信息进行分词,并添加特殊标记[cls]和[sep],使用sentence_transformers库提供的berttokenizer类来创建分词器对象,该类接受预训练模型的名称作为参数,并使用all-minilm-l12-v2作为预训练模型。然后通过分词器对象的tokenize方法对每个文本信息进行分词,并在每个文本信息的开头添加[cls]标记,在每个文本信息的结尾添加[sep]标记。这些标记可以帮助模型识别输入序列的开始和结束,以及两个文本信息之间的边界。
14、a6、将经过所述分词器分词后的文本信息转换为数字id,并统一序列长度,其中,所谓的统一序列长度,可以进行padding或truncating,使得所有输入序列长度相同;
15、a7、创建tensorflow数据集对象,其中包含所述数字id、注意力掩码和风险等级标签,并设置了批次大小;其中,注意力掩码指的是一个二进制张量,用于指示哪些位置是填充的,哪些位置是真实的。填充的位置在注意力计算时会被忽略,以避免对模型的输出造成干扰。注意力掩码的形状是[批次大小,序列长度],其中1表示真实的位置,0表示填充的位置。例如,如果一个输入序列的长度是10,而序列长度是12,那么它的注意力掩码就是[1,1,1,1,1,1,1,1,1,1,0,0]。
16、a8、采用softmaxloss作为损失函数计算narrative列的文本信息与synopsis列的文本信息之间的交叉熵损失,进行分类任务;
17、a9、对sbert模型进行数轮训练,得到微调后的sbert模型,并设置了warmup步骤,以逐渐增加学习率;
18、a10、保存微调后的sbert模型。
19、本实施例中,采用生成对抗网络(gan)生成少数类别的样本,解决asrs数据中的样本不平衡问题的方式,大致包括:改进生成器和鉴别器的网络结构,使其更适用于文本特征的学习,具体来说,将gan中生成器和鉴别器原本的全连层网络改进为长短时回归神经网络(lstm-rnn),捕获asrs文本信息中的时间依赖性;根据生成对抗网络构建对抗学习模式,获取生成器的生成样本作为少数类样本的补充。
20、在s3之后,通过生成对抗网络(gan),针对所述样本数据生成少数类别的样本,通过所述少数类别的样本完善得到平衡后的所述样本数据,解决asrs数据中的样本不平衡问题;其中,长期短期递归神经网络(lstm-rnn)已经被证明能够通过记忆时间单元的时间步长来学习复杂的时间序列。在发明中,为了处理asrs中文本类型数据,gan的生成器和鉴别器都被lstm-rnn取代。本发明中生成对抗网络所采用的gan成本函数如下:
21、表示潜在空间的噪声分布,
22、x~pdata(x)表示x是一个随机变量,它服从真实数据的分布pdata(x)。x表示从真实数据中随机抽取的一个样本,z表示潜在空间的随机噪声,pz(z)表示潜在空间噪声分布,pdata(x)表示真实数据分布,。ex~pada(x)表示真实数据的期望,表示随机噪声的期望,d表示鉴别器,g表示生成器;
23、具体的,所述生成对抗网络的鉴别器的损失函数为:
24、xi表示应该被识别为真实的训练样本,i=1,...,m,i为样本编号,m为最大样本数,glstm-rnn(zi)表示生成的应该被识别为假的样本,zi表示潜在空间的随机噪声,dlstm-rnn表示由lstm和rnn组成的鉴别器,glstm-rnn(zi)表示由lstm和rnn组成的生成器,并用来将随机噪声仿照真实样本生成数据;
25、所述生成对抗网络的生成器的损失函数为:
26、
27、本实施例中,利用深度学习优秀的特征学习性能,构建航空风险识别模型,包括:采用双向长短时记忆网络进行文本信息特征的学习,并引入注意力机制实现特征向量的优化;利用损失函数和softmax分类器实现风险识别,具体的,采用交叉熵损失函数,并且在其后加入l2正则项,避免风险识别模型出现过拟合的情况。,所述航空风险识别模型包括:bilstm层、注意力机制层和分类器;在模型中,通过所述bilstm层用于从asrs报告中提取特征,所提取的特征表示为:和分别代表两个方向上的lstm的隐藏层的输出;通过注意力机制层,将权重分配给bilstm的隐藏层输出,表示为:
28、
29、其中,c表示bilstm隐藏层特征加权后的输出,t表示表示每条样本特征的个数,αt表示归一化的注意力权重矩阵。
30、在所述分类器中,包括:通过softmax函数计算asrs报告的极性判别:p=softmax(wsc+bs),ws为权重矩阵;bs为偏置;融入l2正则项,得到融合后的损失函数l为:f是asrs类别总数,yld是数据l的真实标签类型,λ为正则系数,θ为风险预测模型参数,相当于权重和偏置,pld代表经过风险预测模型将数据l预测为种类d的概率。
31、在所述分类器中,包括:通过五维向量来表示:经过所述风险预测模型处理后得到的,数据属于不同类别的概率值:
32、是对概率分布进行归一化,使得所有概率之和为1,f为5,pld是通过softmax函数预测样本l属于类别d的概率,即给定一个输入l,针对该输入估算出其属于每个类别d概率值,表示风险识别模型预测样本属于不同风险等级类别的指数函数。
33、在所述航空风险识别模型中,通过准确率、精度、召回率和f1值作为模型性能量化指标,表示为:
34、
35、
36、
37、
38、其中,tn表示正确识别的负标签数量,tp表示为正确识别的正标签数量,fp表示错误识别的负标签数量,fn表示错误识别的正标签数量。
39、本发明实施例提供的基于自然语言处理和深度学习的航空风险等级识别方法,可以为飞机操作人员和空中管制人员提供辅助决策。首先获取航空安全报告系统(asrs)数据,利用asrs数据中的”result”属性,对asrs数据进行风险水平等级划分;采用asrs数据对语义相似度模型(sbert)进行微调,获取asrs中长文本内容的编码;采用生成对抗网络(gan)生成少数类别的样本,解决asrs数据中的样本不平衡问题;利用深度学习优秀的特征学习性能,构建航空风险识别模型。能够为飞机操作人员和空中管制人员提供辅助决策,减轻asrs报告风险等级判定中航空专家的工作量。
- 还没有人留言评论。精彩留言会获得点赞!