一种基于Presto的化纤行业数据集成处理方法与流程
本发明涉及大数据集成方法,尤其涉及一种基于presto的化纤行业数据集成处理方法。
背景技术:
1、大数据集成包括大数据采集和大数据整合。大数据采集主要是通过各种技术手段将分散的海量内容数据(文本、音频、视频等)、行为数据(访问、查询、搜索、会话、表单等)、工业生产数据(传感器数据、监控数据)等从业务系统中收集出来。
2、大数据整合的目标是将各种分布的、异构的数据源中的数据抽取后,进行清洗、转换,最后加载到数据仓库或数据集市中,作为数据分析处理和挖掘的基础。
3、由于大数据本身具有分散、海量、高速、异质的特征,采集难度较大,用户需要根据自身的业务、逻辑需求对大数据进行分析和挖掘,这也要求后台对数据处理的能力要与用户需求所匹配,化纤行业指数数据来源于网络爬虫数据采集、业务系统产生的数据等,往往一个指标数据会存在多数据源,会出现数据值在多数据源上会有差异化呈现,对于如何治理这些存在差异化的数据,现有的技术灵活性较差。
4、目前,传统的数据仓库通常需要将数据先导入到存储系统中,然后再进行查询分析。这种方式存在一定的延迟,无法满足实时数据分析的需求。olap查询是一种针对分析处理的查询方式。它用于对数据进行多维分析。olap查询注重的是查询效率和数据分析的准确性,它要求系统能够处理大量的数据,并且能够快速地返回查询结果。presto是一款开源的mpp架构的olap查询引擎,可针对不同数据源执行大容量数据集的一款分布式sql执行引擎。presto可以接入多种数据源,并且支持跨数据源的级联查询,基于内存运算,速度快,实用性高。
技术实现思路
1、为了解决上述的技术问题,本发明的目的是提供一种基于presto的化纤行业数据集成处理方法,该方法可以保证数据的实时性,并实现系统的统一性;另外,可根据业务需求的变化进行扩展,实现异构环境多数据源的集成的可配置,用系统间数据交换的灵活性,保证多种数据在同一平台的兼容,具有良好的可扩展性。
2、为了实现上述的目的,本发明采用了以下的技术方案:
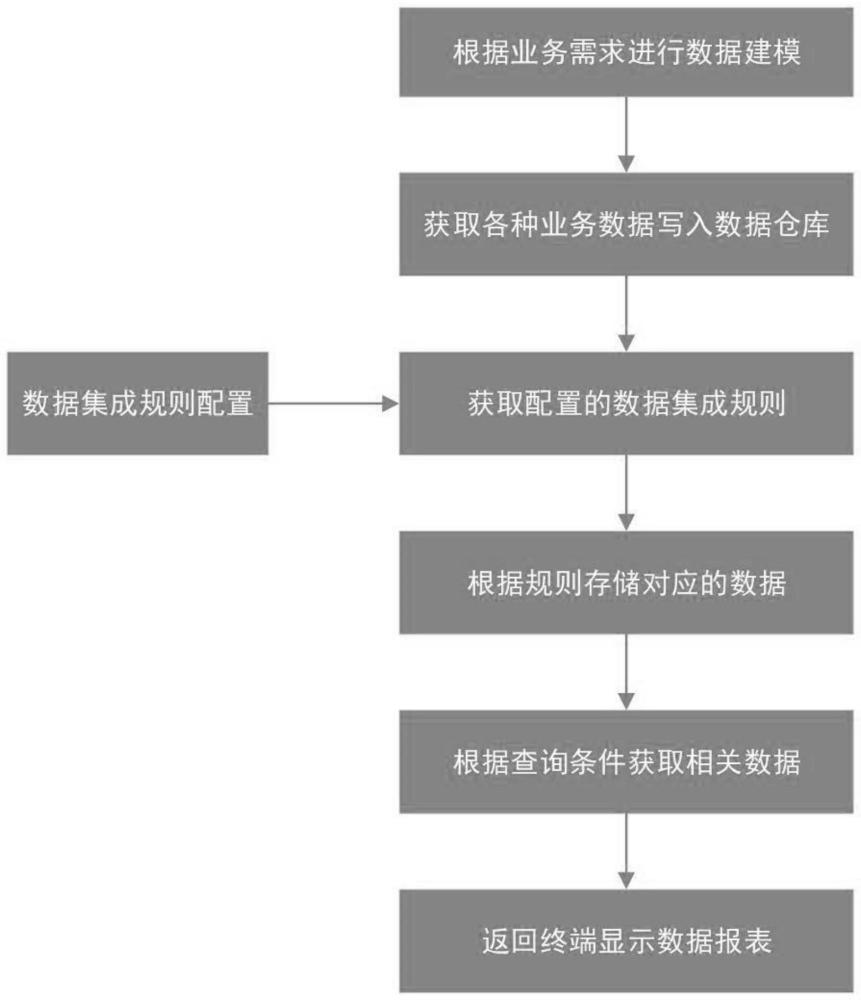
3、一种基于presto的化纤行业数据集成处理方法,该方法包括以下的步骤:
4、1)将各个化纤行业数据系统中的数据按主题进行相似性组合,对所有的业务数据进行分类建模,在数据仓库中建立维度表与事实表;
5、2)获取业务数据写入数据仓库中的数据表;
6、3)数据集成规则配置,在可视化界面设置数据集成规则的配置,或者通过调用内部的接口进行数据集成规则设置;所述数据集成规则包括主题库存储位置规则、数据优先级规则和复合指数运算规则;
7、4)根据主题库存储位置规则获取数据源对应的存储位置,将获取的数据按配置的规则进行数据仓库不同的数据表中存储;
8、5)根据数据优先级规则,对化纤行业指数数据的优先级进行定义,从而进行优先判定;
9、6)确定化纤行业指数数据的优先级,根据复合指数运算规则计算出复合指数同一事实内的值;
10、7)对于度量数据指标,生成按日、按周、按月、按季、按年的多维统计数据,并将结果集存入数据仓库;
11、8)根据接口请求数据的查询条件,将查询分成当天的查询条件和/或历史的时间段的查询条件分别进行,并返回结果;
12、9)根据返回结果的数据集,并在平台之上做具体应用。
13、作为优选,所述步骤1)中化纤行业数据系统包括浙江萧山化学纤维产业大脑有限公司的化纤智联应用系统、化纤产业大脑平台、化纤大脑大数据仓库系统、化纤大脑erp系统、化纤大脑mes系统。
14、作为优选,所述步骤2)中业务数据主要通过以下几个渠道获取数据:
15、1)业务数据库中的业务数据,通过业务系统中运行的业务场景获取数据;
16、2)收集业务系统内部生成的日志信息,对日志文件进行解析获取数据;
17、3)通过传感器等其他智能终端自动采集信号、图片等信息来获取数据;
18、4)通过网络爬虫或网站公开api等方式从网络上获取数据,将非结构化数据、半结构化数据从网络上提取出来,存储到数据仓库中;
19、作为再优选,步骤2)中通过对数据进行包括清洗、去重、格式化的操作来确保数据的质量,将处理过的数据存储到数据库或数据仓库。
20、作为优选,所述步骤3)中数据集成规则配置包括:
21、1)主题库存储位置规则配置:设置数据源相应数据对应主题库相应数据表的对照关系,根据所选择的数据表,获取表的字段属性,再对数据表的字段作对应关系;同时设置分区规则表达式,设置某个业务日期字段,根据日期格式yyyymmdd做表达式配置或依据固定值进行设置,最终数据根据业务日期配置存储到对应的分区;
22、2)数据优先级规则配置:获取数据仓库中数据采集来源维度表,通过调整数据来源上下顺序来设置数据源的优先级,新增未配置的数据来源优先级最低;获取数据仓库中化纤指标维度表的指标数据,选择数据采集来源,并调整数据来源上下顺序来设置某个指标使用的数据源以及相应数据源的优先级;若指标未设置优先级顺序,则默认使用数据源的优先级顺序;
23、3)复合指数运算规则配置:创建复合指数,设置复合指数的名称、是否应用日周月季年多维统计数据的生成,选择参与运算的化纤指标维度表的指数数据,使用算术运算符、括号等符号及固定值设置表达式规则,复合指数的计算就可以通过表达式计算结果值;优选,所述的复合指数包括效益价差指数和汇总指数,效益价差指数包括石脑油价差、pta加工价差,汇总指数包括聚酯类产品出口汇总指数。
24、作为优选,所述步骤4)中根据数据集成规则配置将不同的字段设置到事实表或者维度表对应的位置,并根据对字段的特殊设置,调用不同的数据处理接口;如字段需要进行敏感字段进行脱敏处理,则调用自定义的脱敏方法进行数据的脱敏,最后将处理好的数据存储到数据仓库中。
25、作为优选,所述步骤5)中所述的化纤行业指数包括价格指数、进出口指数、海运指数和内销指数;价格指数包括wti原油期货价格、涤纶poy 150d/48f价格;进出口指数包括涤纶工业丝、涤纶短纤进出口量及进出口金额;海运指数包括沿海成品油运价指数、波罗的海运费指数;内销指数包括如纺织品服装商品零售类值和社会消费品零售总额;优选,步骤5)中编写presto自定义函数,根据设置的优先级规则获取数据的优先级,在系统里通过调用presto进行当前数据优先级的查询,由返回的结果数据确定数据的优先级并进行数据的封装存储。
26、作为优选,所述步骤6)中通过已有的指数根据复合指数运算规则确定复合指数计算方式,遍历设置的复合指数运算规则,通过编写的presto自定义函数,逐个计算出复合指数在同一时间事实内相应的值,并对presto的查询返回结果封装成结果集存储到数据库中,确定复合指数的值,存入数据仓库的事实表中,对于复合指数,若当前是首次进行规则的运算,则将该复合指数纳入指数的维度表中。
27、作为优选,所述步骤7)中度量的数据指标包括px负荷指数、meg负荷指数;在presto查询中,对设置的指数进行按日的汇总统计,并将结果集存入数据仓库的数据表中;再通过指数的日统计数据,汇总指数的周统计数据、月统计数据;最后通过月度统计数据汇总季度统计数据和年度统计数据,并存入数据仓库。
28、作为优选,所述步骤8)中包括:
29、8.1)若请求的数据段包含当天的查询条件,则向presto查询引擎请求业务数据库的数据,业务数据库对应的数据源为mysql数据源,实时获取当天的数据,并调用presto自定义函数计算出当天优先级数据,返回结果;
30、8.2)若请求的数据段包含历史的时间段内,则向presto查询引擎请求数据仓库的数据,数据仓库对应的数据源为hive数据源,数据仓库已经通过前置处理存储各种数据源的数据及对应的优先级,获取优先级最高的数据,返回结果;
31、8.3)若查询条件同时包含两个时间段的数据,则将当天的查询通过presto查询引擎请求到业务数据库中,将历史时间段的查询通过presto查询引擎请求到数据仓库,两边结合其他数据查询条件同时请求数据,最后结合两边的执行分析结果,将最终结果封装成数据集返回到终端。
32、作为优选,所述步骤9)具体应用包括:基于平台做统计分析,展示各种可视化图表及数据报表等内容;通过集成平台为数据仓库提供数据服务,将返回的数据集作为结果返回;在门户系统上使用数据集成平台,将所述相关的数据内容作为分析结果。
33、本发明由于采用了上述的技术方案,具有以下效果:
34、1、平台可以实时的反应底层数据源数据的变化,便于给用户提供及时、准备的信息,保证数据的实时性;
35、2、整个平台通过统一的规则配置,便于数据的转换和异构数据源的集成,同时提供统一的数据访问接口,使各个场景通过统一的接口调用,实现系统的统一性;
36、3、可根据业务需求的变化进行扩展,实现异构环境多数据源的集成的可配置,用系统间数据交换的灵活性,保证多种数据在同一平台的兼容,具有良好的可扩展性。
- 还没有人留言评论。精彩留言会获得点赞!