时间冗余优化的多区域分类视频超分辨率重建方法
本发明属于计算机视觉领域,涉及一种时间冗余优化的多区域分类视频超分辨率重建方法。
背景技术:
1、利用深度学习技术解决视频超分辨率(video super-resolution,vsr)问题已成为一个重要且备受关注的热点问题。已有相当多的学者提出了基于深度学习的网络以解决此类问题。目前对于视频超分辨率重建这一领域的研究可以根据帧间信息的利用方式——是否对齐,分为两大类:即对齐方法和非对齐方法;还可以根据框架的不同将其划分为滑动窗口框架和递归框架两类。这些方法在视频超分辨率重建领域得到了广泛的应用和发展。
2、对齐方法通过提取运动信息,使得相邻帧与当前帧对齐,常用的对齐方法主要是运动估计和运动补偿(motion estimation and motion compensation,memc)以及可变形卷积。运动估计和运动补偿被广泛地研究用于视频处理。在视频超分辨率中,主要采用运动估计和运动补偿来表示连续lr(low resolution)帧之间的时间相关性。通常情况下,运动估计模块将两个帧作为输入,并产生光流矢量场,用光流来表示两帧之间的运动信息。运动补偿模块用于根据运动信息在图像之间进行图像变换,使相邻帧在空间上与当前帧对齐。
3、xintao wang等人提出的增强型可变形视频恢复(edvr)网络就是应用可变形卷积的一个很好示例。当需要恢复的视频中包含遮挡、大运动和严重模糊时,光流这一方法就变得不准确了。因此,它提出了两个关键模块:金字塔、级联和可变形对齐模块(pcd)和时空注意融合模块(tsa),分别用于解决视频中的大运动和有效融合多帧。yapeng tian等人提出的时间可变形对齐网络(tdan),将可变形卷积应用于目标帧和相邻帧,获得相应的偏移量,然后根据偏移量扭曲相邻帧,使相邻帧与目标帧对齐。
4、非对齐方法不需要对齐相邻帧,这类方法主要利用空间或时空信息进行特征提取。非对齐方法主要分为四种类型:2d卷积方法(2d conv)、3d卷积方法、循环卷积神经网络和基于非局部网络的方法。takashi isobe等人提出的时域注意机制(tga)通过帧速率组以分层的方式有效融合了时空信息,通过使用2d密集块和3d单元的组内融合和组间注意力机制以生成最终的高分辨率图像。
5、滑动窗口框架指的是网络每次输入的帧数固定,一次只能处理几帧图像,视频中的每个帧通过使用短时间窗口内的帧来进行恢复。早期的方法预测低分辨率帧之间的光流,并执行空间扭曲以用于对准。后来的方法采取一种更为复杂的隐式对齐方法。例如,tdan采用可变形卷积(dcns)去对齐不同层的帧。edvr进一步以多尺度方式使用dcn,以实现更精确的对齐。递归框架试图通过传播潜在特征来利用长期依赖关系,能够将前面帧的有效信息传播到后续帧中,更加有利于后续视频帧的恢复。例如,rsdn采用单向传播,带有递归细节结构块和隐藏状态自适应模块,以增强对外观变化和错误累积的鲁棒性。kelvinc.k.chan等人提出了basic vsr,该工作证明了双向传播相对于单向传播的重要性,以更好地利用时间特征。kelvin c.k.chan等人提出的basicvsr++对basic vsr进一步改进,提出二阶网格传播和光流引导的可变形对齐,实现了在大约相同参数量的情况下大幅增加网络性能。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种时间冗余优化的多区域分类视频超分辨率重建方法。
2、为达到上述目的,本发明提供如下技术方案:
3、时间冗余优化的多区域分类视频超分辨率重建方法,该方法为:
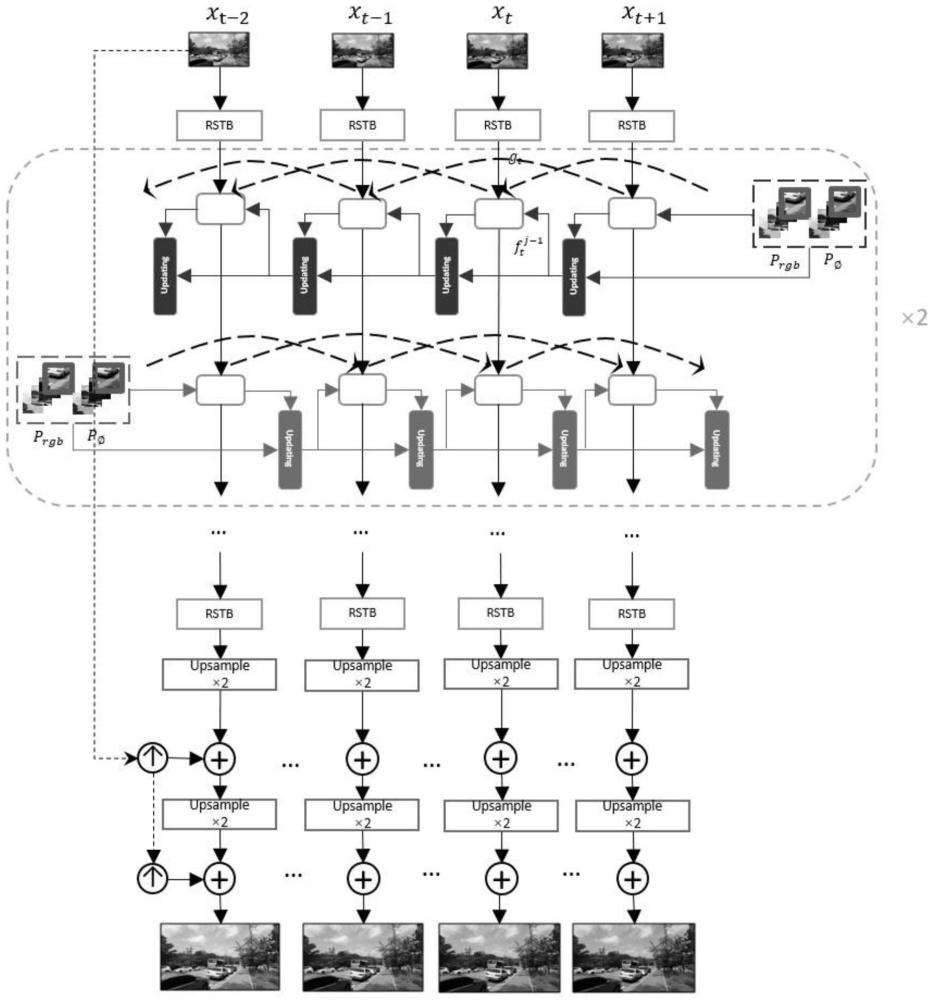
4、在tromcn网络结构中,给定一个低质量视频帧序列t,h,w,c分别表示视频的长度、高度、宽度和通道数,视频超分辨率的目标是重建高质量视频帧序列其中s表示比例因子;在特征提取之前,将输入的视频帧分成64×64的块重叠8个像素取块;在特征提取模块中,使用残差的swin transformer模块提取特征fsf:
5、fsf=hrstb(xlq)
6、其中,hrstb代表特征提取模块,然后特征提取模块经过特征对齐和融合得到:
7、fmsf=hmrc(fsf)
8、其中,hmrc表示特征对齐和融合模块,该模块采用二阶网格的模式进行特征传播,采用基于流的可形变对齐方式进行特征的对齐,然后将学习到的特征经过级联的上采样模块,得到:
9、fup=hup(fmsf)
10、其中,hup表示上采样模块的上采样操作,使用的上采样方式是级联两个×2的亚像素卷积层(pixelshuffle),fup是经过上采样之后得到的特征;然后再将fup输入到重构层中生成最终的超分辨率视频帧:
11、yhq=hr(fup)=htromcn(xlq)
12、其中,hr和htromcn分别表示重建层操作和本次发明提出的tromcn网络;
13、对于训练,使用charbonnier损失函数进行优化,yhq表示重建的图像,yat表示真实的高分辨率图像,∈表示常量。
14、可选的,所述特征提取模块中,对于一个视频帧xt,在进行特征提取之前,将视频帧分成大小为64×64的块重叠8个像素,经过rstb模块提取特征之后得到特征;采用残差的swin transformer模块来提取特征,捕捉长距离依赖,聚合高频信息,提取出具有上下文关联性的特征表示,以分块后的图像为输入,经过一个普通的卷积层后,再经过l个残差结构的swin transformer模块和一个卷积块提取特征,得到提取后的特征单个stl模块表示swin transformer layer,特征提取阶段的公式为:
15、
16、其中,表示浅层特征提取模块提取后的特征,hrstb(·)表示残差的swintransformer模块,hconv(·)表示一个普通的卷积层;表示分块后的图像。
17、可选的,所述特征对齐和融合模块中,特征传播模块采用动态传播,其中当前帧的每一个块接收来自不同帧的信息,采用包含和的分支来恢复来自不同帧的块的有效信息;和分别表示n个重叠块和对应块的隐藏状态;
18、使用光流的平均值来表示运动状态,其公式为:
19、
20、其中flow(·)表示光流估计,|·|表示绝对值,mean表示平均值计算,表示参考块和对应相邻块之间的运动状态;通过设定阈值γ并将其与计算出的光流相比较来判断当前块的相邻块是否能提供有效的帧间信息;比较公式如下:
21、
22、当计算出的光流大于阈值时,认为相邻块提供有用的信息帮助恢复当前块,将其信息采纳,传播给当前块;反之,当计算出的光流小于阈值时,认为这两个块逐像素点之间的移动幅度小,重合像素多,存在时间冗余,容易出现模糊和噪点,这个帧的信息将被丢弃,以避免有用信息的消失;设定两个阈值γ1=0.2,γ2=0.3,分别对应一阶和二阶传播;将更新后的和传播到下一帧;经过特征传播,得到n个块的特征,串联一个rstb模块并将n个块重新合成为一个完整的特征图ht。
23、可选的,所述上采样分为三个类别:基于线性插值的上采样、基于深度学习的上采样以及unpooling方法。
24、本发明的有益效果在于:本发明提出的网络具有更强大的特征提取能力和特征对齐的能力以及减少时间冗余的能力,能够重建出更高质量的高分辨率图像。
25、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!