基于性别一致性的语言模型超长距离能力测试方法及系统
本发明涉及神经语言模型测试,尤其涉及一种基于性别一致性的语言模型超长距离能力测试方法及系统。
背景技术:
1、神经语言模型需要处理、生成或理解不同长度的句子,评估其理解相应长度上下文语境的能力,判断模型在长期记忆/语义理解方面的能力强弱,对模型的选择尤为重要。模型的长距离记忆能力对众多自然语言处理任务都非常重要,包括机器翻译、语音识别、问答系统、对话系统等。因为基于大模型的生成式对话系统可能需要追溯之前的多轮对话历史或搜索引擎等反馈的补充信息,语言模型的长距离关系处理能力对于基于预训练大模型的对话系统更为重要。测试语言模型的长距离能力可以直接反应模型处理长文本输入的能力,并有效利用其中信息的性能,结果对评估模型在具体下游任务上的能力有直接参考价值。
2、神经语言模型长距离能力测试通常需要构建具有长距离关系的测试集,并设计相应的测试方法。通过按照测试方法在测试集上测试神经语言模型,以准确率等测试指标帮助研究人员更好地分析对比此模型有效利用长文本序列中信息的能力,评估不同模型的性能。
3、目前神经语言模型捕获长距离依赖能力的测试方法(例如:lingeval97)主要通过语法的主谓一致性,来测试动词的形式是否与主语的数量(单数或复数)一致,进而评估神经语言模型学习长距离依赖关系的能力。测试集构建首先收集正确的句子,并修改其动词的形式产生错误样例。测试时将正确的句子和错误样例分别输入语言模型,因为语言模型应赋予正确的动词形式更高的分数或概率,所以可以通过检查模型预测结果中动词形式正确的比例,作为准确率评估模型捕获长距离关系的能力,以主语和动词之间词语的数量作为距离。
4、在评估神经语言模型学习长距离依赖关系能力的问题上,如图1所示(横坐标:主语和谓语动词直接的词数,纵坐标:对应距离测试样例数量。),lingeval97数据集中有相当大比例的距离在15之内,仅有1.6%的测试样例的距离超过15,最长的测试距离是53且只有一个样例。这表明lingeval97数据集中的大多数依赖关系都属于中短等长度的距离,在相对较长的距离上测试样本数量非常有限,难以获得可靠的测试结果。
5、现代大语言模型(large language models,llms)拥有巨大的模型容量并从大量训练数据获取知识,中短距离依赖处理能力极强,现有测试集难以反映显著差异。而对话系统的实际应用又需要模型具备从非常长的对话历史或搜索引擎结果中捕获有用信息的能力,之前的测试集也无法满足评估模型捕捉超长距离依赖关系能力的需求。
技术实现思路
1、为此,本发明实施例提供了一种基于性别一致性的语言模型超长距离能力测试方法及系统,用于解决现有技术中测试集无法满足评估模型捕捉超长距离依赖关系能力的需求的问题。
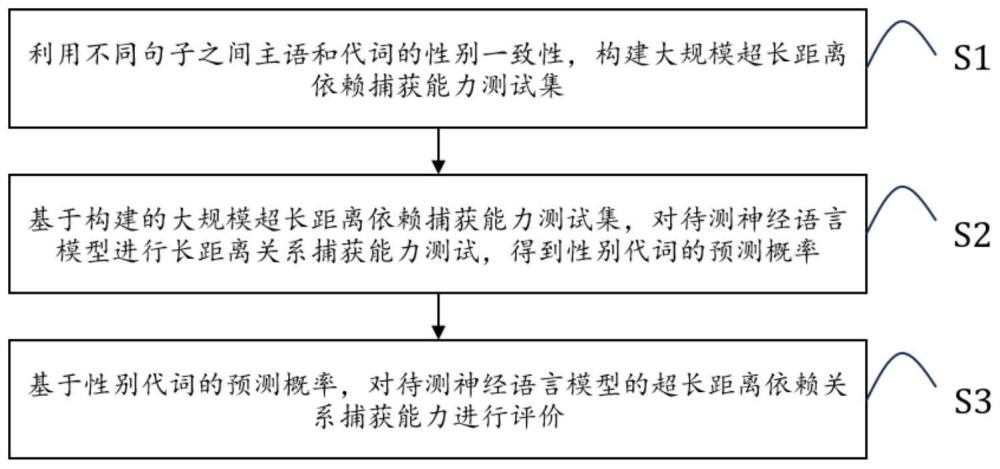
2、为了解决上述问题,本发明实施例提供一种基于性别一致性的语言模型超长距离能力测试方法,所述方法包括:
3、s1:利用不同句子之间主语和代词的性别一致性,构建大规模超长距离依赖关系捕获能力测试集,具体包括:
4、s11:构建带有性别信息的主语集合s,合适的搭配动词集合v,以及名词复数集合n;
5、s12:对于指定距离,将随机抽取主语、动词和所需数量的名词,生成一个测试样例,并对设定范围内的每一个距离,自动创建设定数量的测试样例;
6、s13:依据主语的性别为测试样例自动生成相应的标签,得到大规模超长距离依赖关系捕获能力测试集;
7、s2:基于构建的大规模超长距离依赖关系捕获能力测试集,对待测神经语言模型进行长距离依赖关系捕获能力测试,得到性别代词的预测概率;
8、s3:基于性别代词的预测概率,对待测神经语言模型的超长距离依赖关系捕获能力进行评价。
9、优选地,步骤s12中,对于指定距离,将随机抽取主语、动词和所需数量的名词,生成一个测试样例,并对设定范围内的每一个距离,自动创建设定数量的测试样例的方法为:
10、指定距离k的测试样例数量d,随机从主语集合s和动词集合v均匀采样生成d个主语和动词,并针对每个测试样例从名词集合n中随机抽取k个名词进行扩展。
11、优选地,所述测试样例由特殊的句子开头标记<s>、定冠词“the”、具有语法性别的主语、单数形式的动词、预期距离的复数名词和句末标点符号组成。
12、优选地,所述主语集合s包含10个单词,分别为boy,man,father,sir,gentleman,girl,woman,mother,madam,lady。
13、优选地,所述动词集合v中包含4个动词,分别为likes,hates,dislikes,knows。
14、优选地,步骤s2中,基于构建的大规模超长距离依赖关系捕获能力测试集,对待测神经语言模型进行长距离依赖关系捕获能力测试,得到性别代词的预测概率的方法为:
15、将大规模超长距离依赖关系捕获能力测试集中指定距离的测试样例输入待测神经语言模型中,并在测试语句输入结束时,即输入句号时,从模型下一个词语的预测概率分布中抽取性别代词的预测概率,其中性别代词为"he"或"she"。
16、优选地,步骤s3中,基于性别代词的预测概率,对待测神经语言模型的超长距离依赖关系捕获能力进行评价的方法为:
17、基于性别代词的预测概率,与主语的性别进行比对,将一致的性别代词作为正确答案,通过比对的准确率衡量待测神经语言模型捕获该指定距离依赖关系的能力。
18、本发明实施例还提供了一种基于性别一致性的语言模型超长距离能力测试系统,所述系统用于实现上述所述的基于性别一致性的语言模型超长距离能力测试方法,具体包括:
19、测试集构建模块,用于利用不同句子之间主语和代词的性别一致性,构建大规模超长距离依赖关系捕获能力测试集,具体包括:
20、构建带有性别信息的主语集合s,合适的搭配动词集合v,以及名词复数集合n;
21、对于指定距离,将随机抽取主语、动词和所需数量的名词,生成一个测试样例,并对设定范围内的每一个距离,自动创建设定数量的测试样例;
22、依据主语的性别为测试样例自动生成相应的标签,得到大规模超长距离依赖关系捕获能力测试集;
23、模型测试模块,用于基于构建的大规模超长距离依赖关系捕获能力测试集,对待测神经语言模型进行长距离依赖关系捕获能力测试,得到性别代词的预测概率;
24、模型评价模块,用于基于性别代词的预测概率,对待测神经语言模型的超长距离依赖关系捕获能力进行评价。
25、本发明实施例还提供了一种电子设备,所述电子设备包括处理器、存储器和总线系统,所述处理器和存储器通过该总线系统相连,所述存储器用于存储指令,所述处理器用于执行存储器存储的指令,以实现上述所述的基于性别一致性的语言模型超长距离能力测试方法。
26、本发明实施例还提供了一种计算机存储介质,所述计算机存储介质存储有计算机软件产品,所述计算机软件产品包括的若干指令,用以使得一台计算机设备执行上述所述的基于性别一致性的语言模型超长距离能力测试方法。
27、从以上技术方案可以看出,本发明申请具有以下优点:
28、本发明实施例提供一种基于性别一致性的语言模型超长距离能力测试方法及系统,通过利用不同句子之间主语和代词的性别一致性,构建大规模超长距离依赖关系捕获能力测试集;基于构建的大规模超长距离依赖关系捕获能力测试集,对待测神经语言模型进行长距离依赖关系捕获能力测试,得到性别代词的预测概率;基于性别代词的预测概率,对待测神经语言模型的超长距离依赖关系捕获能力进行评价。本发明利用不同句子之间主语和代词的性别一致性,提出了一种大规模超长距离依赖关系捕获能力测试集的自动构建方法,可以简单有效地自动生成任意数量的包含任意指定长度依赖关系的测试样例,并提出相应的测试方法,解决了模型超长距离依赖关系捕获能力难以可靠测试的问题。
- 还没有人留言评论。精彩留言会获得点赞!