文本识别方法、装置、设备、计算机存储介质及程序产品与流程
本技术属于文本识别,尤其涉及一种文本识别方法、装置、设备、计算机存储介质及程序产品。
背景技术:
1、目前在文本识别的技术领域中,文本识别算法在通过神经网络进行识别前一般都需要对文本进行分词,常规的分词一般是通过语言库进行直接识别。举例来说,常规的分词方法一般是按照文字的顺序在前后顺序在语言库中进行一一匹配,匹配完成后,再读取下一个字向量。这样的方法虽然能够完整常规文本的识别目的。但是在一些长语句中,由于汉语文字在不同的语境下,文字的组合与语义的表达均会有所差异,因此,常规的识别会导致神经网络在识别的过程中出现语义识别精准度低等缺陷。
2、基于此,业界仍然亟待一种新型的用户文本识别方案,以有效提高文本语义的识别精度。
技术实现思路
1、本技术实施例提供一种文本识别方法、装置、设备、计算机存储介质及程序产品,能够更为有效地提高文本语义的识别精度。
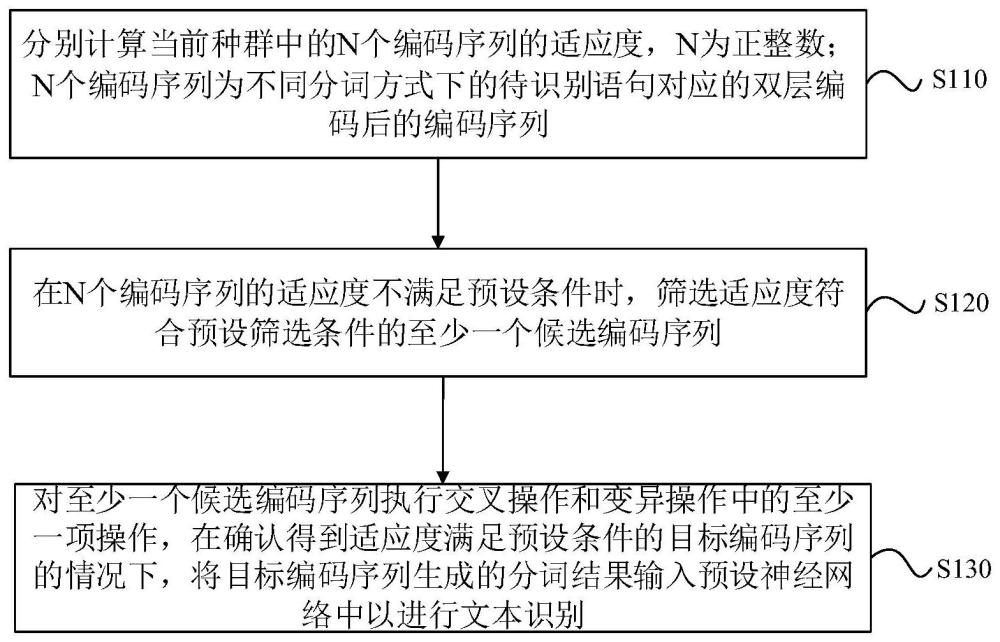
2、第一方面,本技术实施例提供一种文本识别方法,该文本识别方法包括:
3、分别计算当前种群中的n个编码序列的适应度,n为正整数;n个编码序列为不同分词方式下的待识别语句对应的双层编码后的编码序列;
4、在n个编码序列的适应度不满足预设条件时,筛选适应度符合预设筛选条件的至少一个候选编码序列;
5、对至少一个候选编码序列执行交叉操作和变异操作中的至少一项操作,在确认得到适应度满足预设条件的目标编码序列的情况下,将目标编码序列生成的分词结果输入预设神经网络中以进行文本识别。
6、根据本技术的一些实施例,可选的,双层编码中的第一层编码为待识别语句中的分词向量的顺序的编码;双层编码中的第二层编码用于记忆待识别语句中的字向量和分词向量的位置。
7、根据本技术的一些实施例,可选的,在计算当前种群中的n个编码序列的适应度之前,该文本识别方法还包括:
8、对待识别语句进行不同分词处理,得到n种分词结果;
9、分别对n种分词结果中的分词向量的顺序进行第一层编码,得到与n种分词结果一一对应的n个初始编码序列;
10、对n种分词结果中的字向量和分词向量的位置进行第二层编码,得到n个编码序列。
11、根据本技术的一些实施例,可选的,对n种分词结果中的字向量和分词向量的位置进行第二层编码,得到n个编码序列,包括:
12、对n种分词结果中的字向量和分词向量的位置进行第二层编码,并基于n个初始编码序列对第二层编码后的二层编码序列进行固定编码长度截取,得到n个编码序列。
13、根据本技术的一些实施例,可选的,对待识别语句进行不同分词处理,得到n种分词结果,包括:
14、将待识别语句转换为对应的多个字向量;
15、在多个字向量之间随机插入至少一个分词向量,并依据分词向量将连续的字向量合并为词向量,得到n种分词结果。
16、根据本技术的一些实施例,可选的,在并依据分词向量将连续的字向量合并为词向量,得到n种分词结果之后,该文本识别方法还包括:
17、将目标分词结果中的词向量与预设语言库中的词汇进行匹配,得到目标分词结果在预设语言库中能够匹配到的词向量数量;
18、基于词向量数量,确定目标分词结果对应的逆匹配度;其中,n种分词结果中包括目标分词结果。
19、根据本技术的一些实施例,可选的,对至少一个候选编码序列执行交叉操作和变异操作中的至少一项操作,包括:
20、对比两个候选编码序列上的字向量和分词向量之间的位置,分别截取一段编码序列以相互替换,得到执行交叉操作后的两个编码序列;
21、其中,两个候选编码序列中的其中一项候选编码序列所截取的编码序列中字向量和分词向量的数量同于另一项候选编码序列中所截取的编码序列中字向量和分词向量的数量。
22、根据本技术的一些实施例,可选的,对至少一个候选编码序列执行交叉操作和变异操作中的至少一项操作,包括:
23、随机生成m个随机数;m小于候选编码序列上的向量的数量,且m为候选编码序列的逆匹配度的值向上取偶数;
24、将候选编码序列上对应位置的m个字向量或分词向量进行相互交换,并进行迭代;
25、在当前迭代次数是否大于或等于候选编码序列的逆匹配度的情况下,确定得到变异操作后的编码序列。
26、根据本技术的一些实施例,可选的,至少一个候选编码序列包括父代编码序列和历史编码序列中的至少一项;
27、其中,父代编码序列为n个编码序列中的编码序列,历史编码序列为历史种群中的编码序列。
28、根据本技术的一些实施例,可选的,在对至少一个候选编码序列执行交叉操作和变异操作中的至少一项操作之后,该文本识别方法还包括:
29、删除包括至少连续两个分词向量的编码序列;
30、分别计算剩余编码序列的适应度,并判断是否存在适应度满足预设条件的编码序列;
31、在存在适应度满足预设条件的编码序列的情况下,确认得到目标编码序列。
32、根据本技术的一些实施例,可选的,分别计算当前种群中的n个编码序列的适应度,包括:
33、检测当前种群的迭代次数是否小于预设迭代次数阈值;
34、在当前种群的迭代次数小于预设迭代次数阈值的情况下,分别计算当前种群中的n个编码序列的适应度;
35、在检测当前种群的迭代次数是否小于预设迭代次数阈值之后,该文本识别方法还包括:
36、在当前种群的迭代次数大于或等于预设迭代次数阈值,且n个编码序列的适应度不满足预设条件时,对待识别语句中分词向量的数量进行更新选择,以重新生成新的编码序列。
37、基于相同的发明构思,第二方面,本技术实施例提供了一种文本识别装置,该文本识别装置包括:
38、第一计算模块,用于分别计算当前种群中的n个编码序列的适应度,n为正整数;n个编码序列为不同分词方式下的待识别语句对应的双层编码后的编码序列;
39、第一筛选模块,用于在n个编码序列的适应度不满足预设条件时,筛选适应度符合预设筛选条件的至少一个候选编码序列;
40、第一处理模块,用于对至少一个候选编码序列执行交叉操作和变异操作中的至少一项操作,在确认得到适应度满足预设条件的目标编码序列的情况下,将目标编码序列生成的分词结果输入预设神经网络中以进行文本识别。
41、第三方面,本技术实施例提供了一种文本识别设备,该文本识别设备包括:
42、处理器以及存储有计算机程序指令的存储器;
43、所述处理器执行所述计算机程序指令时实现如上述本技术实施例中任意一项提供的文本识别方法。
44、第四方面,本技术实施例提供了一种计算机存储介质,该计算机可读存储介质上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现如上述本技术实施例中任意一项提供的文本识别方法。
45、第五方面,本技术实施例提供了一种计算机程序产品,计算机程序产品中的指令由电子设备的处理器执行时,使得所述电子设备执行如上述本技术实施例中任意一项提供的文本识别方法。
46、本技术实施例提供的一种文本识别方法、装置、设备、计算机存储介质及程序产品,通过分别计算当前种群中的n个编码序列的适应度,n个编码序列为不同分词方式下的待识别语句对应的双层编码后的编码序列;在n个编码序列的适应度不满足预设条件时,筛选适应度符合预设筛选条件的至少一个候选编码序列,再对至少一个候选编码序列执行交叉操作和变异操作中的至少一项操作。这样,当在确认得到适应度满足预设条件的目标编码序列的情况下,可以将目标编码序列生成的分词结果输入预设神经网络中以进行文本识别。通过上述描述可知,本技术实施例的一种文本识别方法、装置、设备、计算机存储介质及程序产品,通过结合遗传算法的逻辑,在神经网络对文本识别前,通过遗传算法对文本进行精准分词,从而有利于提高后续神经网络的训练以及识别精度,进而能够更为有效地提高文本语义的识别精度。
- 还没有人留言评论。精彩留言会获得点赞!