基于本地知识库的农业领域知识问答系统及方法与流程
本发明涉及自然语言处理,尤其涉及一种基于本地知识库的农业领域知识问答系统及方法。
背景技术:
1、知识问答系统是一种基于自然语言处理及人工智能技术的应用,根据用户提问的问题,通过分析计算,从知识库或者语料库中检索到最相关的答案。该系统首先将用户输入的问题进行预处理,包括分词、词性标注及命名实体识别等,然后通过向量检索技术从知识库中检索到最相关的答案,目前,传统农业已经逐步向科技农业转变,在农业客服领域中,针对海量的农业知识问题及农业技能问题,给出快速且准确的响应是迫切要解决的问题。当前智能问答系统基于通用领域的知识库,这类知识库的特点是资料易搜集,但是其中关于农业领域的详细资料甚少,且回复相对宽泛,不具备实际应用和科普的农业价值,同时,现有智能问答系统一般基于文本问答库的对话系统,直接通过问题对知识库中的答案进行匹配,导致知识库检索压力过大,且检索得到的答案信息过于冗余直板,无法被用户直接接收理解。基于本地知识库的问答系统在进行文本嵌入向量时对计算机的运行内存要求极高,在内存不大的服务器上上传知识库时容易造成程序崩溃。
2、通过构建农业领域的本地知识库,获取丰富的农业相关知识及信息,搭建组织化、结构化的数据集合,为农业领域的专业人员、农民及决策者提供方便快捷的信息资源,基于批处理解决问答系统在进行文本嵌入时容易出现的程序崩溃问题,同时,结合大语言模型使得到的问题答案更加精准易理解。
技术实现思路
1、本发明针对现有技术中的缺点,提供了一种基于本地知识库的农业领域知识问答系统及方法。
2、为了解决上述问题,本发明通过下述技术方案得以解决:
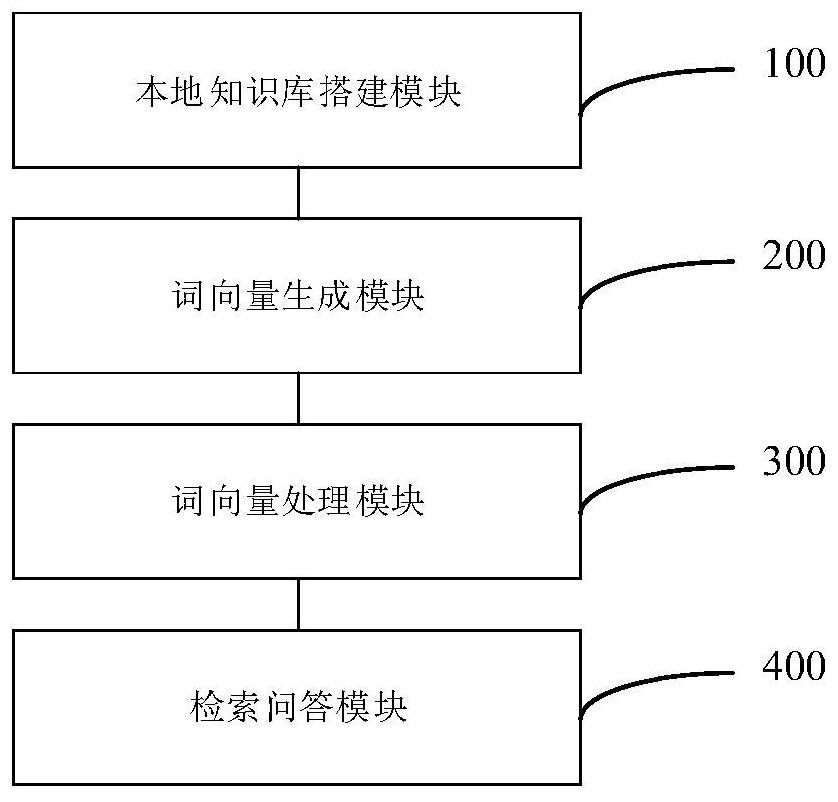
3、一种基于本地知识库的农业领域知识问答系统,包括本地知识库搭建模块、词向量生成模块、词向量处理模块及检索问答模块;
4、所述本地知识库搭建模块,用于通过获得农业知识信息形成知识文档,基于知识文档搭建本地知识库;
5、所述词向量生成模块,用于对本地知识库中所有知识文档进行预处理得到知识词语,对所述知识词语进行批处理,采用词向量模型将知识词语映射到向量空间,得到词向量,对词向量进行合并形成初始词向量库;
6、所述词向量处理模块,用于通过初始词向量库构建初始词向量矩阵,对初始词向量矩阵进行均值中心化及降维处理,得到降维词向量矩阵,通过对降维词向量矩阵进行索引化,得到索引向量;
7、所述检索问答模块,用于将待回答问题进行预处理,得到问题向量,基于问题向量结合索引向量检索降维词向量矩阵,得到答案向量,将问题向量及答案向量输入至知识问答模型得到问题答案。
8、作为一种可实施方式,所述农业知识信息包括作物养殖信息、土壤水资源信息、农业机械设备信息、病虫害防治信息、农产品加工贮藏信息、农村经济政策信息及气象气候信息。
9、作为一种可实施方式,所述预处理为切分处理,所述切分处理按照标点符号、空格及文档类型对知识文档进行切分。
10、作为一种可实施方式,所述对所述知识词语进行批处理,包括以下步骤:
11、基于所述知识词语得到文本实际长度,基于文本实际长度,得到每批次导入的数据量,表示如下:
12、
13、
14、lmaxsize=lcpu*0.8
15、其中,lbatch表示每批次输入的数据量,ldocs表示输入的字符总长度,li表示每一行的文本长度,lmaxsize表示最大输入阈值,lcpu表示当前服务器的总运行内存。
16、作为一种可实施方式,所述基于初始词向量知识库构建初始词向量矩阵,对初始词向量矩阵进行均值中心化及降维处理,得到降维词向量矩阵,包括以下步骤:
17、获取初始词向量知识库中所有词向量,基于所述词向量构成初始词向量矩阵,其中,每一行代表一个词的词向量,每一列代表词向量的维度;
18、对初始词向量矩阵进行均值中心化操作,得到标准向量矩阵,其中,所述标准词向量矩阵服从标准正态分布;
19、采用降维算法对标准词向量矩阵进行降维操作,降低标准词向量矩阵维度且保留标准词向量矩阵的表达内容,得到降维词向量矩阵。
20、作为一种可实施方式,所述对初始词向量矩阵进行均值中心化操作,得到标准向量矩阵,表示如下:
21、
22、
23、
24、其中,xij表示第i个样本的第j列向量,μj表示每一列特征的均值,m表示行数,σj表示每一列特征的标准差,zij表示标准向量矩阵中第i个样本的第j列向量。
25、作为一种可实施方式,所述采用降维算法对标准词向量矩阵进行降维操作,表示如下:
26、
27、cijvn=λnvn
28、y=x·vl
29、vl={v1,v2,...,vl}
30、其中,cij表示协方差矩阵,zki表示正态向量矩阵中第k个样本的第i列向量,zkj表示正态向量矩阵中第k个样本的第j列向量,表示正态向量矩阵中第i行特征的均值,表示正态向量矩阵中第j行特征的均值,λn表示特征值,vn表示对应的特征向量,y表示降维词向量矩阵,vl表示v1,v2,...,vl构成的特征向量矩阵,l表示预设阈值。
31、作为一种可实施方式,所述将问题向量及答案向量输入至知识问答模型得到问题答案,包括:
32、所述问题向量与降维词向量矩阵中所包含降维词向量维度一致;
33、设置降维词向量矩阵的子空间数量,基于子空间数量对降维词向量矩阵进行聚类,得到降维词向量子集;
34、基于问题向量,构建问题索引,选择降维词向量子集并进行检索,得到与问题向量匹配度最高的检索词向量,所述匹配度最高的检索词向量即为答案向量,其中,所述答案向量为与问题向量之间的l2距离最小的检索词向量;
35、所述距离表示如下:
36、
37、其中,qj表示问题向量q在维度j上对应的元素,xij表示索引向量xi在维度j上对应的元素,l2(q,xi)表示距离,imin表示答案向量对应索引,
38、一种基于本地知识库的农业领域知识问答方法,包括以下步骤:
39、通过获得农业知识信息形成知识文档,基于知识文档搭建本地知识库;
40、对本地知识库中所有知识文档进行预处理得到知识词语,对所述知识词语进行批处理,采用词向量模型将知识词语映射到向量空间,得到词向量,对词向量进行合并形成初始词向量库;
41、通过初始词向量库构建初始词向量矩阵,对初始词向量矩阵进行均值中心化及降维处理,得到降维词向量矩阵,通过对降维词向量矩阵进行索引化,得到索引向量;
42、将待回答问题进行预处理,得到问题向量,基于问题向量结合索引向量检索降维词向量矩阵,得到答案向量,将问题向量及答案向量输入至知识问答模型得到问题答案。
43、作为一种可实施方式,所述通过初始词向量库构建初始词向量矩阵,对初始词向量矩阵进行均值中心化及降维处理,得到降维词向量矩阵,包括以下步骤:
44、获取初始词向量知识库中所有词向量,基于所述词向量构成初始词向量矩阵,其中,每一行代表一个词的词向量,每一列代表词向量的维度;
45、对初始词向量矩阵进行均值中心化操作,得到标准向量矩阵,其中,所述标准词向量矩阵服从标准正态分布;
46、采用降维算法对标准词向量矩阵进行降维操作,降低标准词向量矩阵维度且保留标准词向量矩阵的表达内容,得到降维词向量矩阵;
47、所述对初始词向量矩阵进行均值中心化操作,得到标准向量矩阵,表示如下:
48、
49、
50、
51、其中,xij表示第i个样本的第j列向量,μj表示每一列特征的均值,m表示行数,σj表示每一列特征的标准差,zij表示标准向量矩阵中第i个样本的第j列向量;
52、所述采用降维算法对标准词向量矩阵进行降维操作,表示如下:
53、
54、cijvn=λnvn
55、y=x·vl
56、vl={v1,v2,...,vl}
57、其中,cij表示协方差矩阵,zki表示正态向量矩阵中第k个样本的第i列向量,zkj表示正态向量矩阵中第k个样本的第j列向量,表示正态向量矩阵中第i行特征的均值,表示正态向量矩阵中第j行特征的均值,λn表示特征值,vn表示对应的特征向量,y表示降维词向量矩阵,vl表示v1,v2,...,vl构成的特征向量矩阵,l表示预设阈值。
58、本发明由于采用了以上的技术方案,具有显著的技术效果:
59、通过本发明的方法,解决了农业领域专业知识库的搭建问题,通过批处理解决知识库问答系统对计算机运行内存要求极高的问题,采用建立索引的方法避免直接通过问句对知识库进行检索匹配,降低知识库的检索压力,同时检索得到的答案更加精准,结合大语言模型,避免输出答案过于直板,无法被用户直接接收。
- 还没有人留言评论。精彩留言会获得点赞!