大模型的参数调整方法、装置、电子设备和存储介质与流程
本公开涉及计算机,尤其涉及一种大模型的参数调整方法、大模型的参数调整装置、电子设备和存储介质。
背景技术:
1、在需要将源数据处理模型迁移到目标域的情况下,我们需要采用目标域的训练样本集对源数据处理模型进行参数调整。我们发现,若目标域的训练样本集中的训练样本的数量过大,则会增加数据处理模型的遗忘性;若目标域的训练样本集中的训练样本的数量过小,则将导致数据处理模型的泛化能力不足。
技术实现思路
1、本公开提供了一种大模型的参数调整技术方案。
2、根据本公开的一方面,提供了一种大模型的参数调整方法,包括:
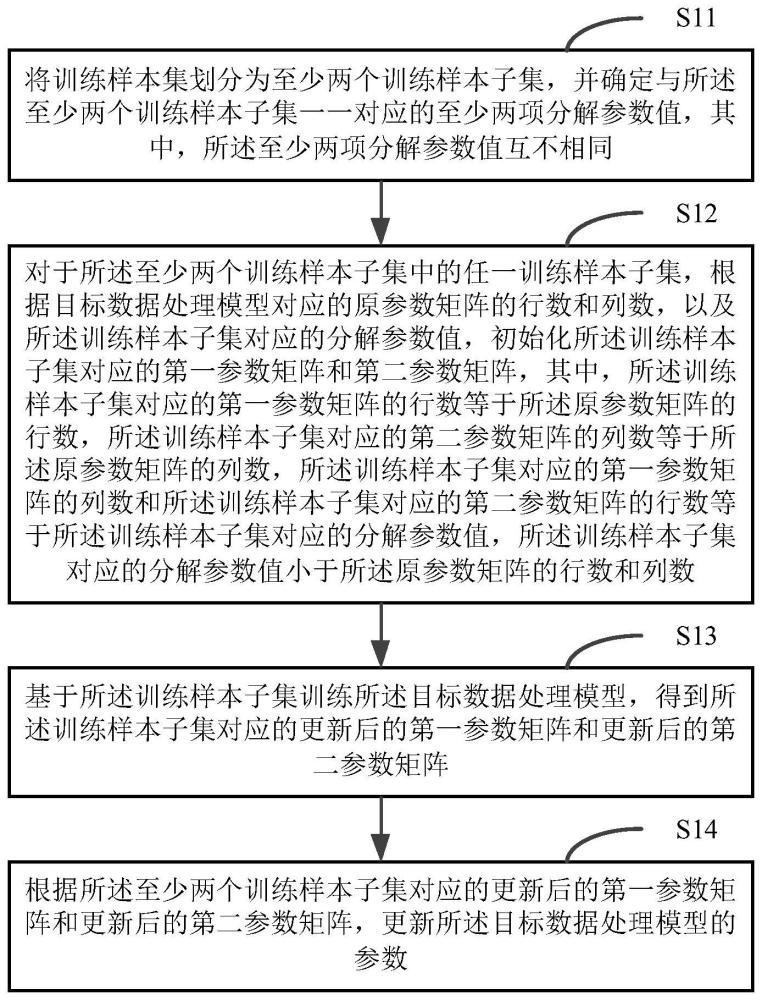
3、将训练样本集划分为至少两个训练样本子集,并确定与所述至少两个训练样本子集一一对应的至少两项分解参数值,其中,所述至少两项分解参数值互不相同;
4、对于所述至少两个训练样本子集中的任一训练样本子集,根据所述目标数据处理模型对应的原参数矩阵的行数和列数,以及所述训练样本子集对应的分解参数值,初始化所述训练样本子集对应的第一参数矩阵和第二参数矩阵,其中,所述训练样本子集对应的第一参数矩阵的行数等于所述原参数矩阵的行数,所述训练样本子集对应的第二参数矩阵的列数等于所述原参数矩阵的列数,所述训练样本子集对应的第一参数矩阵的列数和所述训练样本子集对应的第二参数矩阵的行数等于所述训练样本子集对应的分解参数值,所述训练样本子集对应的分解参数值小于所述原参数矩阵的行数和列数;
5、基于所述训练样本子集训练所述目标数据处理模型,得到所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵;
6、根据所述至少两个训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,更新所述目标数据处理模型的参数。
7、在一种可能的实现方式中,所述训练样本子集对应的分解参数值比所述原参数矩阵的行数和列数小至少一个数量级。
8、在一种可能的实现方式中,在所述目标数据处理模型的参数调整过程中,所述原参数矩阵保持固定。
9、在一种可能的实现方式中,所述基于所述训练样本子集训练所述目标数据处理模型,得到所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,包括:
10、对于所述训练样本子集中的任一训练样本,将所述训练样本输入所述目标数据处理模型,通过所述目标数据处理模型输出所述训练样本对应的预测结果;
11、根据所述训练样本子集中的训练样本对应的预测结果和标签,确定所述训练样本子集对应的损失函数的值;
12、根据所述训练样本子集对应的损失函数的值,确定所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵。
13、在一种可能的实现方式中,所述将所述训练样本输入所述目标数据处理模型,通过所述目标数据处理模型输出所述训练样本对应的预测结果,包括:
14、计算所述训练样本子集对应的最新的第一参数矩阵与最新的第二参数矩阵的乘积,得到所述训练样本子集对应的第一乘积;
15、将所述原参数矩阵与所述训练样本子集对应的第一乘积之和,确定为所述训练样本子集对应的最新总参数矩阵;
16、将所述训练样本输入所述目标数据处理模型,基于所述训练样本子集对应的最新总参数矩阵,得到所述训练样本对应的预测结果。
17、在一种可能的实现方式中,所述根据所述训练样本子集对应的损失函数的值,确定所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,包括:
18、根据所述训练样本子集对应的损失函数的值,确定所述训练样本子集对应的第一参数矩阵的第一梯度以及所述训练样本子集对应的第二参数矩阵的第二梯度;
19、根据所述训练样本子集对应的第一参数矩阵的第一梯度,确定所述训练样本子集对应的更新后的第一参数矩阵;
20、根据所述训练样本子集对应的第二参数矩阵的第二梯度,确定所述训练样本子集对应的更新后的第二参数矩阵。
21、在一种可能的实现方式中,所述方法还包括:
22、在显存中,保存所述训练样本子集对应的第一参数矩阵的第一梯度和所述训练样本子集对应的第二参数矩阵的第二梯度。
23、在一种可能的实现方式中,所述方法还包括:
24、在显存中,保存所述训练样本子集对应的第一参数矩阵的第一优化器状态信息和所述训练样本子集对应的第二参数矩阵的第二优化器状态信息。
25、在一种可能的实现方式中,所述根据所述至少两个训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,更新所述目标数据处理模型的参数,包括:
26、对于所述至少两个训练样本子集中的任一训练样本子集,计算所述训练样本子集对应的最新的第一参数矩阵与最新的第二参数矩阵的乘积,得到所述训练样本子集对应的第二乘积;
27、根据所述至少两个训练样本子集对应的第二乘积,以及所述原参数矩阵,确定所述目标数据处理模型的更新后的参数矩阵。
28、在一种可能的实现方式中,所述损失函数包括预测下一个字的任务对应的第一损失函数。
29、在一种可能的实现方式中,所述损失函数包括强化学习任务对应的第二损失函数。
30、在一种可能的实现方式中,所述目标数据处理模型为文本处理模型,所述训练样本为训练文本。
31、根据本公开的一方面,提供了一种数据处理方法,包括:
32、获取所述大模型的参数调整方法训练得到的目标数据处理模型;
33、将待处理数据输入所述目标数据处理模型,通过所述目标数据处理模型输出所述待处理数据对应的数据处理结果。
34、在一种可能的实现方式中,所述待处理数据为待处理文本。
35、根据本公开的一方面,提供了一种大模型的参数调整装置,包括:
36、划分模块,用于将训练样本集划分为至少两个训练样本子集,并确定与所述至少两个训练样本子集一一对应的至少两项分解参数值,其中,所述至少两项分解参数值互不相同;
37、初始化模块,用于对于所述至少两个训练样本子集中的任一训练样本子集,根据所述目标数据处理模型对应的原参数矩阵的行数和列数,以及所述训练样本子集对应的分解参数值,初始化所述训练样本子集对应的第一参数矩阵和第二参数矩阵,其中,所述训练样本子集对应的第一参数矩阵的行数等于所述原参数矩阵的行数,所述训练样本子集对应的第二参数矩阵的列数等于所述原参数矩阵的列数,所述训练样本子集对应的第一参数矩阵的列数和所述训练样本子集对应的第二参数矩阵的行数等于所述训练样本子集对应的分解参数值,所述训练样本子集对应的分解参数值小于所述原参数矩阵的行数和列数;
38、第一更新模块,用于基于所述训练样本子集训练所述目标数据处理模型,得到所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵;
39、第二更新模块,用于根据所述至少两个训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,更新所述目标数据处理模型的参数。
40、在一种可能的实现方式中,所述训练样本子集对应的分解参数值比所述原参数矩阵的行数和列数小至少一个数量级。
41、在一种可能的实现方式中,在所述目标数据处理模型的参数调整过程中,所述原参数矩阵保持固定。
42、在一种可能的实现方式中,所述第一更新模块用于:
43、对于所述训练样本子集中的任一训练样本,将所述训练样本输入所述目标数据处理模型,通过所述目标数据处理模型输出所述训练样本对应的预测结果;
44、根据所述训练样本子集中的训练样本对应的预测结果和标签,确定所述训练样本子集对应的损失函数的值;
45、根据所述训练样本子集对应的损失函数的值,确定所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵。
46、在一种可能的实现方式中,所述第一更新模块用于:
47、计算所述训练样本子集对应的最新的第一参数矩阵与最新的第二参数矩阵的乘积,得到所述训练样本子集对应的第一乘积;
48、将所述原参数矩阵与所述训练样本子集对应的第一乘积之和,确定为所述训练样本子集对应的最新总参数矩阵;
49、将所述训练样本输入所述目标数据处理模型,基于所述训练样本子集对应的最新总参数矩阵,得到所述训练样本对应的预测结果。
50、在一种可能的实现方式中,所述第一更新模块用于:
51、根据所述训练样本子集对应的损失函数的值,确定所述训练样本子集对应的第一参数矩阵的第一梯度以及所述训练样本子集对应的第二参数矩阵的第二梯度;
52、根据所述训练样本子集对应的第一参数矩阵的第一梯度,确定所述训练样本子集对应的更新后的第一参数矩阵;
53、根据所述训练样本子集对应的第二参数矩阵的第二梯度,确定所述训练样本子集对应的更新后的第二参数矩阵。
54、在一种可能的实现方式中,所述装置还包括:
55、第一保存模块,用于在显存中,保存所述训练样本子集对应的第一参数矩阵的第一梯度和所述训练样本子集对应的第二参数矩阵的第二梯度。
56、在一种可能的实现方式中,所述方法还包括:
57、第二保存模块,用于在显存中,保存所述训练样本子集对应的第一参数矩阵的第一优化器状态信息和所述训练样本子集对应的第二参数矩阵的第二优化器状态信息。
58、在一种可能的实现方式中,所述第二更新模块用于:
59、对于所述至少两个训练样本子集中的任一训练样本子集,计算所述训练样本子集对应的最新的第一参数矩阵与最新的第二参数矩阵的乘积,得到所述训练样本子集对应的第二乘积;
60、根据所述至少两个训练样本子集对应的第二乘积,以及所述原参数矩阵,确定所述目标数据处理模型的更新后的参数矩阵。
61、在一种可能的实现方式中,所述损失函数包括预测下一个字的任务对应的第一损失函数。
62、在一种可能的实现方式中,所述损失函数包括强化学习任务对应的第二损失函数。
63、在一种可能的实现方式中,所述目标数据处理模型为文本处理模型,所述训练样本为训练文本。
64、根据本公开的一方面,提供了一种数据处理装置,包括:
65、第一获取模块,用于获取所述大模型的参数调整装置训练得到的目标数据处理模型;
66、数据处理模块,用于将待处理数据输入所述目标数据处理模型,通过所述目标数据处理模型输出所述待处理数据对应的数据处理结果。
67、在一种可能的实现方式中,所述待处理数据为待处理文本。
68、根据本公开的一方面,提供了一种电子设备,包括:一个或多个处理器;用于存储可执行指令的存储器;其中,所述一个或多个处理器被配置为调用所述存储器存储的可执行指令,以执行上述方法。
69、根据本公开的一方面,提供了一种计算机可读存储介质,其上存储有计算机程序指令,所述计算机程序指令被处理器执行时实现上述方法。
70、根据本公开的一方面,提供了一种计算机程序产品,包括计算机可读代码,或者承载有计算机可读代码的非易失性计算机可读存储介质,当所述计算机可读代码在电子设备中运行时,所述电子设备中的处理器执行上述方法。
71、在本公开实施例中,通过将训练样本集划分为至少两个训练样本子集,并确定与所述至少两个训练样本子集一一对应的至少两项分解参数值,其中,所述至少两项分解参数值互不相同,对于所述至少两个训练样本子集中的任一训练样本子集,根据所述目标数据处理模型对应的原参数矩阵的行数和列数,以及所述训练样本子集对应的分解参数值,初始化所述训练样本子集对应的第一参数矩阵和第二参数矩阵,其中,所述训练样本子集对应的第一参数矩阵的行数等于所述原参数矩阵的行数,所述训练样本子集对应的第二参数矩阵的列数等于所述原参数矩阵的列数,所述训练样本子集对应的第一参数矩阵的列数和所述训练样本子集对应的第二参数矩阵的行数等于所述训练样本子集对应的分解参数值,所述训练样本子集对应的分解参数值小于所述原参数矩阵的行数和列数,基于所述训练样本子集训练所述目标数据处理模型,得到所述训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,并根据所述至少两个训练样本子集对应的更新后的第一参数矩阵和更新后的第二参数矩阵,更新所述目标数据处理模型的参数,由此在不增加训练样本的总量从而不增加目标数据处理模型的遗忘性的前提下,利用分解参数值互不相同的至少两个训练样本子集对目标数据处理模型进行参数调整,从而能够增强目标数据处理模型的泛化能力,以及提高目标数据处理模型进行数据处理的准确性。
72、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,而非限制本公开。
73、根据下面参考附图对示例性实施例的详细说明,本公开的其它特征及方面将变得清楚。
- 还没有人留言评论。精彩留言会获得点赞!