基于数值模拟和深度学习的叶绿素遥感数据重构方法
本发明属于海洋观测,具体地说,尤其涉及一种基于数值模拟和深度学习的卫星遥感叶绿素a浓度数据重构方法。
背景技术:
1、卫星遥感反射率数据由于受到气溶胶、云、沙尘、海冰等现象以及大气校正失败的影响,容易造成海表温度、悬浮泥沙浓度、叶绿素a(chl-a)浓度等逐日的三级产品出现大面积数据缺失的现象。以欧空局(esa)气候变化倡议(cci)下海洋水色项目(oc-cci)产生的chl-a浓度数据为例,这是目前精度最高的开源产品之一,该项目从2010年开始生产数据,将众多在轨运行卫星传感器的原始数据集进行大气校正和误差控制,并对其进行波段的统一调整,从而得到综合的遥感反射率数据。项目根据不同地区的水体光学特性进行分类,以像素为单位对其应用不同的chl-a浓度算法,最终得到基于多个水色传感器融合的网格化chl-a产品。目前数据已更新到5.0版本,可提供时间分辨率为1天、空间分辨率为4km的chl-a浓度数据。以我国渤海地区为例,统计了2018年4月1日至2021年10月31日期间oc-cci的逐日chl-a浓度数据的缺失率。其中,最小日缺失率约为3%,最大日缺失率可达到100%,缺失率在75%以上的天数约占65%,在25%以下的天数约占31%,季节变化显著,春秋季缺失率低,夏冬季缺失率高。渤海海域按照4km的空间分辨率计算共有4530个网格点,每幅日分辨率chl-a浓度图像中网格点数据的平均缺失概率约为73%。数据缺失率较高的区域是渤海湾、莱州湾和辽东湾顶区域,平均数据缺失率高于90%;数据缺失率最低的区域是渤海中部和辽东湾南部区域,缺失率在65%到75%之间。
2、解决大范围数据缺失的方法是数据重构,目前常用的技术是利用数学方法,比如:经验正交函数(empirical orthogonal functions,eof),分析目标数据的时空演变规律,进而利用插值函数进行数据重构。例如美国海洋大气局(noaa)发布的基于数据插值经验正交函数(data interpolating empirical orthogonal functions,dineof)算法的无缺失海洋水色产品数据集。但此类利用数学方法重构的数据要求其数据本身具有较好的规律性或者周期性变化,高频变化常常因为会降低计算效率而被作为噪音去掉。因此,利用数学方法重构的数据对于天气尺度过程(如降雨、台风)引起的chl-a浓度快速变化并不敏感。此外,利用数学方法重构的数据由于缺少生物地球化学过程的约束,对于大范围的缺失值而言相当于一种外插,因而其准确度并不高,甚至会产生虚假的高值。因此,利用数学方法重构的chl-a浓度数据难以用于近海赤潮等灾害的研究。
技术实现思路
1、本发明的目的是一种基于数值模拟和深度学习的卫星遥感叶绿素a浓度数据重构方法,以弥补现有技术的不足。
2、本发明利用数值模拟数据时空连续、无缺失的优势,以及卷积神经网络方法对空间信息的捕获能力和深度学习模型的数据关联能力,重新建立了一种数据重构的新方法,以提高重构数据对天气尺度过程的敏感度与准确度。
3、为达到上述目的,本发明是通过以下技术方案实现的:
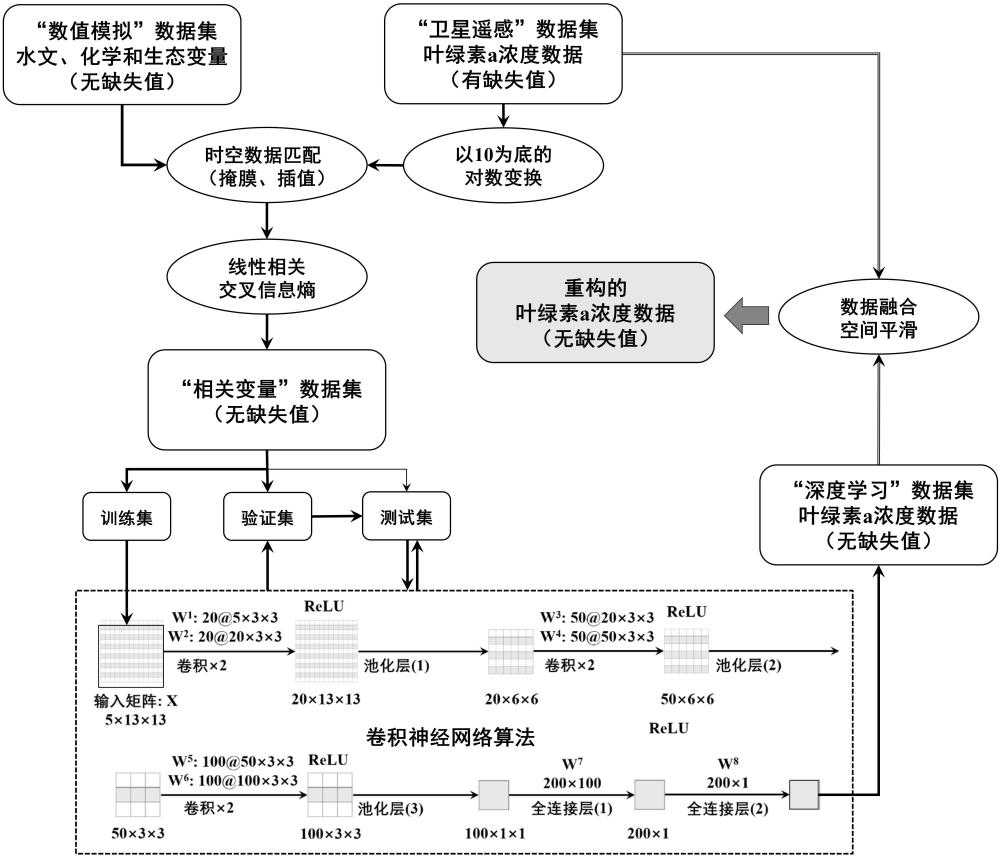
4、一种基于数值模拟和深度学习的卫星遥感叶绿素a浓度(chl-a)数据重构方法,包括以下步骤:
5、(1)建立“数值模拟”数据集和“卫星遥感”数据集,由于实际海域的chl-a浓度往往集中在0~10mg/m3的区间内,在整个浓度范围内属于重尾分布,为了提高计算效率,将“卫星遥感”数据进行以10为底的对数变换;
6、(2)将“数值模拟”数据集与“卫星遥感”数据集进行时空匹配;
7、(3)采用线性相关和交叉信息熵度量方法,从“数值模拟”数据集中选择有效的输入变量,构建“相关变量”数据集;
8、(4)基于卷积神经网络(cnn)算法,采用基于空间窗口扫描的样本构建方法、连续卷积以及最大池化方法建立深度学习模型,该模型包含四个主层,其中前三个主层分别由连续的两个卷积层和一个池化层构成,卷积核数量依次为20、50和100,第四个主层则由两个全连接层构成,在卷积层与池化层之间添加批归一化计算和非线性激活函数relu;将时空匹配的两类数据集分别划分为训练集、验证集与测试集;以“相关变量”训练集为深度学习模型的输入值,以“卫星遥感”训练集的chl-a浓度作为该组数据对应的输出值,进行训练;
9、(5)基于训练好的深度学习模型,对全部的“相关变量”数据集进行计算,得到无缺失的“深度学习”chl-a数据集,再与有缺失的“卫星遥感”chl-a数据集进行数据融合与空间平滑,即可得到无缺失的chl-a数据集,完成了数据重构过程。
10、进一步的,所述步骤(1)中,利用经过验证的海洋数值模拟输出的水文变量、化学变量和生态变量,选择所有可能与叶绿素a浓度相关的变量构建“数值模拟”数据集;同时选择同期卫星遥感chl-a浓度产品构建“卫星遥感”数据集;两类数据集均应包含经度、纬度和时间三个维度。
11、更进一步的,所述步骤(1)中,水文变量包括风速、风向、水温、盐度、流速等,化学变量包括溶解态无机氮、活性磷酸盐、溶解态有机氮、溶解态有机磷、化学需氧量、溶解氧等,生态变量包括浮游植物生物量、浮游动物生物量、碎屑量等。
12、进一步的,所述步骤(2)中,对“卫星遥感”数据集进行掩膜,对陆地、异常值和缺失值取0处理;利用自然临近插值方法将“数值模拟”数据集与“卫星遥感”数据集进行时空匹配,保证“数值模拟”数据与“卫星遥感”数据在时空维度上的一一对应。
13、进一步的,所述步骤(3)中,采用线性相关和交叉信息熵度量方法,从“数值模拟”数据集中选择与“卫星遥感”chl-a数据相关性强的变量作为输入变量;定义相关强度i,i值越大,则代表两个变量之间的相关性越强,具体计算公式为:
14、
15、i=0.5×(|c|+ami)
16、其中,ami(x;y)∈[0,1],为离散变量x、y的交叉信息熵;p(x,y)是离散变量x、y的联合概率密度函数;p(x)和p(y)分别是离散变量x和y的概率密度函数;c为皮尔逊相关系数。若i=0,则变量x和y是相互独立的;若i=1,变量x和y是完全相关的;
17、计算得到“数值模拟”数据集中各变量与“卫星遥感”chl-a浓度的相关强度,选择相关强度高的变量作为输入变量,构建“相关变量”数据集。
18、进一步的,所述步骤(4)中,利用卷积神经网络(cnn)算法建立深度学习模型,以“相关变量”训练集为深度学习模型的输入值,采用基于空间窗口扫描的样本构建方法,对逐日的输入场进行三维扫描输入,以空间窗口中心位置的“卫星遥感”训练集的chl-a浓度作为该组数据对应的输出值,进行训练。当训练轮数达到设定的总次数或者“相关变量”验证集经训练后的损失连续多次不再下降时停止训练。
19、进一步是,所述步骤(5)中数据融合算法可以是加权平均算法,也可以采用其他融合算法,空间平滑算法可以是空间九点平滑,也可以采用其他平滑算法。
20、进一步的,上述方法中还包括:训练完成后,再利用“相关变量”测试集对深度学习模型的泛化能力进行检验,以确定深度学习模型的有效性。
21、与现有技术相比,本发明优点和的有益效果是:
22、本发明能够克服目前单纯依赖数学算法重构数据的准确度问题:①对于天气尺度过程的不敏感性;②缺少生物地球化学过程约束而造成的偏离值。本发明结合数值模拟数据的无缺失特性以及cnn深度学习算法对于空间信息的识别能力,能够有效提高卫星遥感近海逐日chl-a浓度数据的时空连续性,并能准确反映天气尺度过程引起的chl-a浓度变化。
23、本发明基于能够描绘水动力-生物地球化学过程的数值模拟技术,通过深度学习建立数值模拟结果与卫星遥感chl-a浓度数据间的变换规律,进而重构逐日的chl-a浓度数据,在保证时空连续性的基础上,提高了重构数据的准确度。
- 还没有人留言评论。精彩留言会获得点赞!