一种随机性在线云边端协同的数据存储方法及系统与流程
本发明属于云边端协同、云存储,特别是一种随机性在线云边端协同的数据存储方法及系统。
背景技术:
1、近年来,伴随着数字经济的飞速发展,云计算一直保持着迅猛的发展势头,同时也是当今i t技术发展领域的热点话题之一。云计算作为计算技术和生产实践长期演变的产物,不仅可以有效降低服务的成本,也可以大幅提升资源的利用率。此外,云计算还具备着弹性扩展、容灾恢复、按需获取等诸多优点。
2、随着云计算在i aas、paas、saas领域不断深耕并逐步发展壮大,数据量的激增给各大云服务提供商带来了前所未有的存储压力。相比于自建存储服务器所造成的硬件资源成本高、维护开销大等缺点,更多的互联网企业选择了存储成本低、更加智能化的云存储系统。得益于云存储的高效率、低成本、智能化、高可靠等特点,云存储被广泛地应用到各生产环境中,如:通用存储、大数据分析、数据库服务、微服务等领域,并发挥着关键的作用。
3、现如今,随着智能设备越来越多的接入网络,传统云计算范式中的数据存储、工作负载以及带宽资源等方面将面临巨大挑战,使得在车联网、智能监控等低延迟、高带宽需求的应用场景面临着诸多问题。对于存储在云端的数据,通过云边端协同可以更加高效的将需要实时计算和分析的数据存放到靠近终端设备的地方,以保证数据处理的实时性。在“云-边-端”架构中,“云”是中心节点,负责对边缘计算的管控,“边”是云计算的边缘侧,负责局部的数据分析,“端”是终端设备,负责数据的采集、感知等操作。云边端协同的机制,不仅可以有效降低云用户的存储成本,还可以在时空的维度为云用户提供更加优质的服务。
4、对于云服务提供商而言,相较于在边缘端设立大量的存储服务器来进行数据存储,在云端存储数据往往会节省更多的成本。在一段时间内,如果某些数据在边缘侧被频繁访问,显然这些数据存放到边缘端更加合适,一方面可以尽可能地保证数据在传输过程中的实时性,另一方面可以有效降低数据在传输过程中带宽的开销。相反,如果某些数据一段时间内在边缘侧被访问的频次很低,显然这些数据存储在云端更加合适,这样不仅可以有效降低数据存储的成本,也可以有效缓解边缘侧数据存储的压力。
5、在现有的云边协同方案中,专利cn111800486a提供了一种云边协同的资源调度方法及系统。该发明在执行的过程中根据用户各地区带宽的实际占用情况实时地做出预留决策,从而有效减少由于访问人数短时间内的激增而导致的带宽费用的激增。该发明从访问带宽出发,通过实时监测各mec服务器服务范围内客户对每一个资源的访问热度,来判断某地区某资源客户的访问带宽达到所设定的阈值,进而判断在该地区应当租用mec服务器还是在所述租用mec服务器的预留期内,协同使用mec服务器和云服务器提供访问。然而,该发明没有充分考虑用户在使用云存储服务的qos,其应用场景具有一定的局限性。同时,该发明提出的云边协同资源调度方法较为简单,在算法设计上有着很大的优化空间,以节约更多的存储成本。
6、专利cn113157446a提供了一种云边协同的资源分配方法、装置、设备及介质。该发明通过区块链和云边协同方案对资源进行限定控制,根据耦合规则逻辑启动所有子任务,最终根据所有的子任务执行成果聚合完成总任务。首先通过云边协同平台对需要分配资源的任务进行分析,确定所述待分配资源的任务参数以及最小拆分子集,并根据所述待分配资源的任务参数结合任务资源协同算法,确定云边协同方案,最终根据所述区块链以及所述云边协同方案,对所述待分配资源的任务进行资源分配。然而,该发明引入了区块链技术,会造成能源的大量消耗,伴随着数据量的激增,会衍生出不同程度的性能问题。此外,该发明没有考虑降低数据存储的成本,仅是单一的提出了一种理想化的云边协同资源分配策略。
7、近年来云服务提供商日益重视优化云成本、控制云浪费和提高云部署效率,加之越来越多的智能设备接入网络,边缘侧对数据的感知需求愈发强烈,因此如何从云边端协同的角度来充分降低云存储的成本,提高云存储服务的部署效率,具有重要的研究意义与价值。当前的云边协同资源调度机制已难以满足当前应用场景对任务处理的需求。
技术实现思路
1、本发明的目的是提供一种随机性在线云边端协同的数据存储方法及系统,以解决现有技术中的不足,它根据数据的历史存储行为以及云、边两侧对数据的处理频次,来实时提供一种智能、灵活、高效的数据存储策略,在保证数据存储性能的同时极大地降低云存储服务的部署成本,提高云存储服务的部署效率。
2、本技术的一个实施例提供了一种随机性在线云边端协同的数据存储方法,所述方法包括:
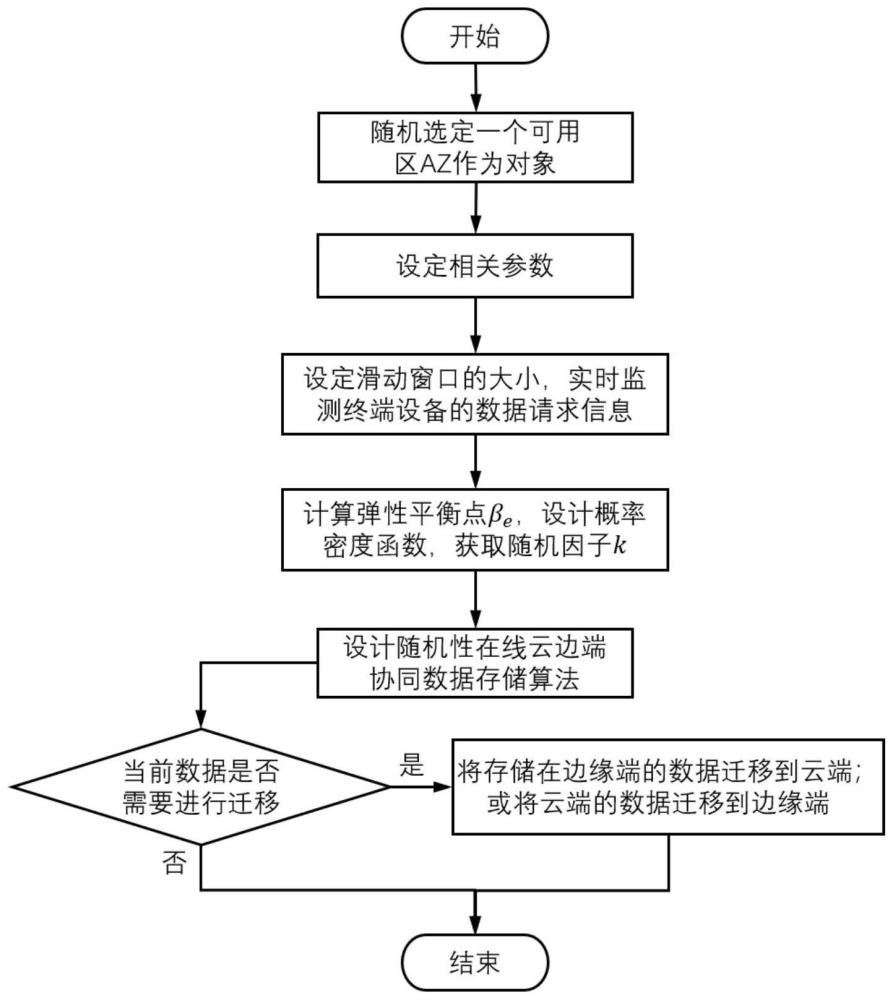
3、步骤1:开始选取研究对象,在一个地域范围内,随机选取一个可用区作为对象,统计该可用区az中边缘端节点的数量n。
4、步骤2:设定相关参数,令bcenter为云端存储的数据量,令为边缘端存储的数据量,令pcenter为数据在云端存储的单价,令为数据在边缘端存储的单价,其中i∈[1,n],令q为数据存取的单价,令t为数据的存储时长,令t为存储计费的周期。假设在过去一个存储周期中数据存放在云端,令其存储成本为ccenter,假设在过去一个存储周期中数据存放在边缘端,令其存储成本为cedge。
5、步骤3:设定滑动窗口尺寸大小并统计相关数据,设定滑动窗口的尺寸大小z,实时监测终端设备的数据请求情况,记录并统计滑动窗口范围内云用户在终端发起的数据存取请求次数m,统计这些数据在云端和边缘端进行处理的次数,其中将在云端进行数据处理的次数记作hcenter,将在边缘端进行数据处理的次数记作hedge。
6、步骤4:计算弹性平衡点βe,构造概率密度函数,获取随机因子k;
7、步骤5:设计随机性在线云边端协同数据存储算法;
8、步骤6:通过所述机性在线云边端协同数据存储算法判断当前数据是否需要进行迁移。
9、可选的,所述随机性在线云边端协同的数据存储方法还包括:
10、若所述当前数据需要迁移,则将存储在边缘端的数据迁移到云端,或将云端的数据迁移到边缘端,在当前存储周期t,随机性在线云边端协同的数据存储方法执行完毕,在下一存储周期t',重复执行该方法,若所述当前数据不需要迁移,则直接结束进程。
11、进一步的,所述计算弹性平衡点βe是为提出随机性在线云边端协同数据存储算法做前期准备,所述弹性平衡点βe通过步骤1-3中设定的相关参数,得出在过去一个存储计费周期t中,数据存储在云端的成本为ccenter=bcenter·pcenter·t+z·hcenter/t·q,数据存储在边缘端的成本为
12、进一步的,所述计算弹性平衡点βe中将云端数据的存储成本ccenter和边缘端数据的存储成本cedge建立关联,并设定弹性区间s为[l,r],其中l=min(z/t·hcenter,m),r=max(z/t·hedge,m)。
13、进一步的,所述弹性平衡点βe通过计算得出:
14、
15、进一步的,在步骤4中,所述构造概率密度函数通过结合数据存储成本的计算公式以及设定的相关参数再结合计算得出的弹性平衡点βe,其中令所述构造概率密度函数如下:
16、
17、其中,e为自然指数,δ(·)为狄拉克δ函数,k为随机因子。
18、进一步的,所述构造的概率密度函数,通过计算其反函数来获取随机因子k,其中令函数f(y)的数学期望计算f(k)的反函数得到随机因子k,其随机因子k的计算公式为:
19、
20、进一步的,在步骤5中,所述设计随机性在线云边端协同数据存储算法,包括如下步骤:
21、在当前时刻t0,分别统计从t0-z+1时刻到t0时刻期间数据在云端和边缘端被访问的次数hcenter和hedge,并由此计算出这段时间数据的存储成本其为
22、
23、如果当前的数据存储在边缘端,在当前时刻t0比较数据的存储成本和随机因子k的大小;
24、如果当前的数据存储在云端,在当前时刻t0比较数据的存储成本和随机因子k的大小;
25、设置多级队列协调机制,创建n级存储队列,在当前时刻t0,通过比较数据的存储成本和随机因子k的大小,确定数据应当存储在云端还是边缘端,对于需要进行物理迁移的数据,基于局部性原理首先将其存放到队列ni中进行缓存,然后完成数据的迁移。
26、本技术的又一实施例提供了一种随机性在线云边端协同的数据存储系统,所述系统包括:
27、数据采集模块,获取云端、边缘端和终端的资源请求信息,并接收与服务器连接的数据存取记录信息;
28、实时监控模块,实时监控云端、边缘端和终端的数据存取请求,包括请求时间、数据量大小等参数;
29、数据存储模块,对采集的数据、设定的参数以及实时监控的信息进行存储;
30、计算模块,计算弹性平衡点、构造概率密度函数、获取随机因子、计算反函数、计算数学期望等关键数据;
31、算法生成模块,生成随机性在线云边端协同数据存储算法,判断当前数据应当存储在云端还是边缘端;
32、协同调度模块,将存储在云端的数据迁移到边缘端,或将存储在边缘端的数据迁移到云端;
33、日志模块,记录终端用户资源请求情况以及数据获取情况等信息,并对云端和边缘端两侧数据的迁移情况进行记录。
34、本技术的又一实施例提供了一种存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成随机性在线云边端协同的数据存储方法。
35、本技术的又一实施例提供了一种终端设备,包括存储器、处理器和计算机程序,所述存储器中存储有计算机程序,所述处理器被设置为运行所述计算机程序以实现上述任一项中所述的方法。
36、与现有技术相比,本发明可以实时地为数据应当存储在边缘端还是云端做出合理的决策,并尽可能降低云存储服务的部署成本,提高云存储服务的部署效率,同时能够保证用户在使用云存储服务时的qos。提出了一种随机性在线云边端协同数据存储算法,通过将随机性在线云边端协同数据存储算法与概率分布、数学期望相结合,可以尽可能地降低云存储服务的部署成本,随机性在线云边端协同数据存储算法产生的随机因子可以实时地为数据应当存储在边缘端还是云端做出更加合理的决策。引入“滑动窗口”的概念,实现对存储在云端和边缘端的数据实时监控,并支持自定义滑动窗口的尺寸大小,可以自适应地调整云端和边缘端对所存储数据的感知范围,通过将随机性在线云边端协同数据存储算法与滑动窗口相结合,可以有效提升随机性在线云边端协同数据存储算法预测结果的准确性与灵活性,并能够轻松应对不同的生产环境需求,提高云存储服务的部署效率,提出“弹性平衡点”(elastic-break-even-points)的概念,通常情况下,平衡点都是基于某一等式计算得出的定值,这样可以简化研究模型。然而,在一些对时延感知较为敏感的应用场景,设计一个具有弹性区间的平衡点,能够为数据应当存储在边缘端还是云端做出更加合理的决策,并在保证数据存储性能的同时极大地降低数据存储成本。引入多级队列协调机制,通过设定多级队列,基于局部性原理实现对云端和边缘端所存储数据的优先级缓存,从而在数据存取、使用的过程中更加稳定,以充分保证用户在使用云存储服务时的qos。
- 还没有人留言评论。精彩留言会获得点赞!