一种基于Cycle-GAN的图像加雾方法
本发明涉及计算机视觉的图像分析,特别是涉及一种基于cycle-gan的图像加雾方法。
背景技术:
1、随着计算机视觉技术的发展,图像处理技术也得到了广泛的关注和研究。其中,图像去雾和图像加雾技术是图像处理领域中的热门研究方向之一。在实际应用中,由于环境、气候等因素的影响,很多场景中的图像都存在雾气干扰,这些图像可能会失去很多细节信息,降低图像的质量和可读性,因此需要图像去雾技术。而与此相反,图像加雾技术则可以在没有实际的雾气存在的情况下合成一些看起来有雾气的图像,可以为实际场景中的图像处理提供更多的样本数据。
2、目前,去雾技术已经得到了广泛应用和研究。常见的去雾方法包括单幅图像去雾、多幅图像去雾和视频去雾等。这些方法主要基于先验知识和物理模型,如大气光照模型和图像统计特征等。同时,还有一些基于深度学习的去雾方法也得到了广泛关注,如基于卷积神经网络的去雾方法和基于生成对抗网络的去雾方法等。
3、相比之下,加雾技术的研究和应用相对较少,传统的图像加雾技术是通过模拟真实环境中的光线传播过程来产生雾的效果,其中比较常用的方法包括:基于深度图的方法、基于天空盒的方法和基于模型的方法,这些方法存在如下缺点:(1)无法根据场景和光照自适应地添加雾气,因此难以得到高质量的结果;(2)通常是基于一些简单的假设,比如场景中的雾是均匀的或者是单一的,这可能导致一些不真实的结果;(3)加雾的同时也会使得图像的细节模糊,降低图像质量;(4)通常需要对整个图像进行处理,这可能导致处理时间过长;(5)通常是单向的,即只能将清晰图像转化为雾化图像,而无法将雾化图像还原为清晰图像。
4、总体而言,加雾技术还有更多的发展空间和研究方向,有更过需要解决的技术问题,因此,亟需一种基于cycle-gan的图像加雾方法。
技术实现思路
1、本发明的目的是提供一种基于cycle-gan的图像加雾方法,通过输入待处理的图像,将图像与文本信息特征融合,输入在多模态扩散文本语义约束下的cycle-gan网络中生成目标图像,提升图像雾气效果,生成更符合实际效果和目标需求的图像。
2、为实现上述目的,本发明提供了如下方案:
3、一种基于cycle-gan的图像加雾方法,包括:
4、获取待加雾图像;
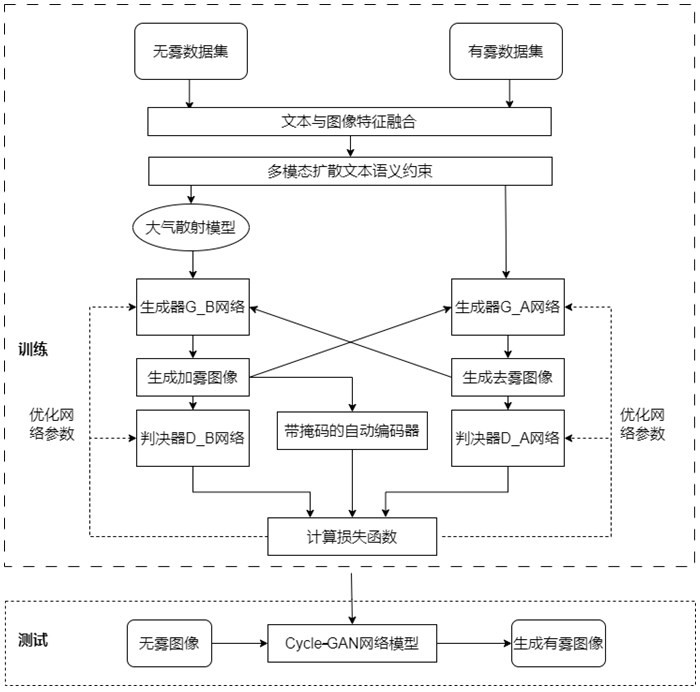
5、将所述待加雾图像输入预设的图像生成模型中,输出加雾后的目标图像,其中,所述图像生成模型由训练集训练获得,所述训练集包括无雾的图像数据和文本数据、有雾的图像数据和文本数据,所述图像生成模型采用cycle-gan网络构建。
6、进一步地,构建所述图像生成模型包括:
7、采集所述无雾的图像数据和文本数据、有雾的图像数据和文本数据,将所述无雾的图像数据和文本数据、有雾的图像数据和文本数据分别进行特征融合;
8、获取目标雾气生成效果,基于所述目标雾气生成效果构建文本语义约束;
9、引入大气散射模型对特征融合后的数据进行先验约束,然后输入以所述文本语义约束作为条件输入的生成器,生成图像;
10、将所述图像输入判决器中进行判决,获取符合预设条件的图像,并将符合预设条件的图像输入带掩码的自动编码器中进行图像去噪,获取最终图像,完成所述图像生成模型的构建。
11、进一步地,采集所述无雾的图像数据和文本数据、有雾的图像数据和文本数据包括:
12、采集有雾的图像数据、无雾的图像数据,并将一张无雾图像对应四张不同程度的有雾图像;收集与所述图像数据相关的文本数据,包括图像的标签、描述、评论;将所述图像数据与所述文本数据进行数据对齐。
13、进一步地,将所述图像数据和所述文本数据进行特征融合包括:
14、将所述图像数据和文本数据输入预设的clip模型中,获取图像编码和文本编码;
15、在共同编码空间中,将所述图像编码和所述文本编码进行比较,计算所述图像编码与所述文本编码之间的相似度,构建特征矩阵,完成所述图像数据和所述文本数据的特征融合。
16、进一步地,所述预设的clip模型包括:图片编码器和文本编码器,所述图片编码器采用卷积神经网络,为基于transformer的图像分类模型,用于将输入的图像转换为特征向量;所述文本编码器为基于transformer-based的语言模型,用于将输入的文本描述转换为文本向量。
17、进一步地,获取所述图像编码的方法为:
18、
19、其中,为待编码图像,为图像编码函数,为图像编码,为实数集合,为样本数量,为图像特征维度;
20、获取所述文本编码的方法为:
21、
22、其中,为待编码文本,为文本编码函数,为文本编码,为文本特征维度;
23、计算所述图像编码与所述文本编码之间的相似度的方法为:
24、
25、其中,为经过 l2标准化后的图像编码,为经过 l2标准化后的文本编码,)为 l2标准化函数,为余弦相似度计算函数。
26、进一步地,基于所述目标雾气生成效果构建文本语义约束包括:
27、获取所述目标雾气生成效果,对所述目标雾气生成效果的文本进行预处理,将处理后的文本输入预设的clip模型中,获取所述文本的文本编码,将所述文本的文本编码作为文本约束语句;
28、将所述文本约束语句加入生成器和判别器中构建所述文本语义约束。
29、进一步地,将所述文本约束语句加入生成器和判别器中构建所述文本语义约束包括:
30、将所述文本约束语句通过文本编码器生成文本特征,将所述文本特征作为条件输入到生成器中生成约束雾图,将所述约束雾图通过图像编码器生成图像特征,比较所述文本特征和所述图像特征,计算所述文本特征和所述图像特征的语义相似度,将所述语义相似度与所述约束雾图送入判决器中进行判别,根据所述语义相似度是否在预设范围内判断所述约束雾图的真实性。
31、进一步地,获取所述最终图像具体包括:
32、基于所述大气散射模型对特征融合后的数据进行先验约束,然后将数据输入以所述文本语义约束作为条件输入的生成器,输出图像;
33、将所述图像输入所述判决器中进行判决,并计算所述图像的文本特征与所述文本语义约束的相似度,根据所述相似度是否在预设范围内判断所述图像的真实性;
34、将判断为真的图像输入带掩码的所述自动编码器中进行图像去噪,获取所述最终图像。
35、进一步地,所述图像生成模型的构建中还包括损失函数的计算,通过所述损失函数对所述生成器和判决器进行优化,所述损失函数的计算方法为:
36、
37、其中,g为域x到域y的生成器,f为域y到域x的生成器,为生成域x图像的判决器,为生成域y图像的判决器,i为大气散射模型生成图,为清晰图像转换成有雾图像的对抗性损失,为有雾图像转换成清晰图像的对抗性损失,为循环一致性损失,为大气散射模型约束的损失。
38、本发明的有益效果为:
39、(1)本发明通过引入clip模型,图像的加雾和去雾过程可以更加注重图像中的语义内容,确保加雾和去雾后的图像在语义上与原始图像保持一致,从而避免破坏图像的真实性和含义,更加语义感知的加雾与去雾。
40、(2)本发明结合大气散射模型的先验约束,加雾和去雾过程可以更符合实际物理情况,加雾时,考虑大气散射模型可以更准确地模拟雾气的形成过程,去雾时,结合大气散射模型可以更好地还原原始场景。
41、(3)本发明加入自动编码器去噪可以减轻生成图像中的噪声,提升图像质量,这对于去雾效果尤为重要,因为去雾后图像可能受到雾气和降噪引入的噪声影响。
42、(4)本发明结合多种先验信息可以提供更多的约束,减少生成图像的不确定性,这有助于提高算法在不同场景和条件下的通用性和稳定性。
43、(5)本发明通过引入先验信息,生成模型可能需要更少的训练数据就能获得更好的性能,这对于数据稀缺或难以获得大规模训练数据的情况尤其有益。
44、(6)本发明结合多种约束和先验信息,生成的图像更具有创造性,提供多种场景下的不同视角和效果,有助于创造独特的图像效果。
45、(7)本发明将深度学习技术与物理模型相结合,充分利用了两者的优势,为图像处理任务提供了更丰富的信息和更强的约束。
- 还没有人留言评论。精彩留言会获得点赞!