一种基于自适应样本生成的教材版面分析方法和装置与流程
本发明属于智能教育领域,尤其涉及一种基于自适应样本生成的教材版面分析方法和装置。
背景技术:
1、智能教育是将人工智能技术应用在教育中,以教育的数字化、智能化支撑和引领现代化教育。教材中信息的表现形式主要包括文本和图像,构建教材的文本-图像多模态知识图谱可以更加全面地表达并关联教材中的知识点信息,在知识点的智能搜索和个性化学习路径的推荐中具有重要作用。
2、教材的版面分析是构建教材文本-图片多模态知识图谱的基础。文本模态的知识点主要位于教材的标题、正文、表格、注释等文字信息中,图像模态的知识点主要存在于教材的图片中,此外,教材中还有页眉、页脚、公式、参考文献、目录等版面元素。版面分析可以识别出教材中版面元素的位置和类别,分割不同类别的版面元素,并排除图片、公式对ocr识别文本信息的干扰。
3、在基于深度学习的版面分析方法中,生成样本的交并比阈值会影响模型的性能,教材排版的多样性和复杂性增加了交并比阈值设定的难度。因此,模型在训练过程中以自适应方式设定交并比阈值并生成样本,可以提高教材版面分析的效果。
技术实现思路
1、本发明的目的在于针对现有技术的不足,提供了一种基于自适应样本生成的教材版面分析方法和装置,用于教材的版面分析,准确识别教材中版面元素的位置和类别。
2、本发明的目的是通过以下技术方案来实现的:一种基于自适应样本生成的教材版面分析方法,包括以下步骤:
3、(1)获取教材数据,将教材数据转化为图片格式,并将图片数据分为训练集和测试集;
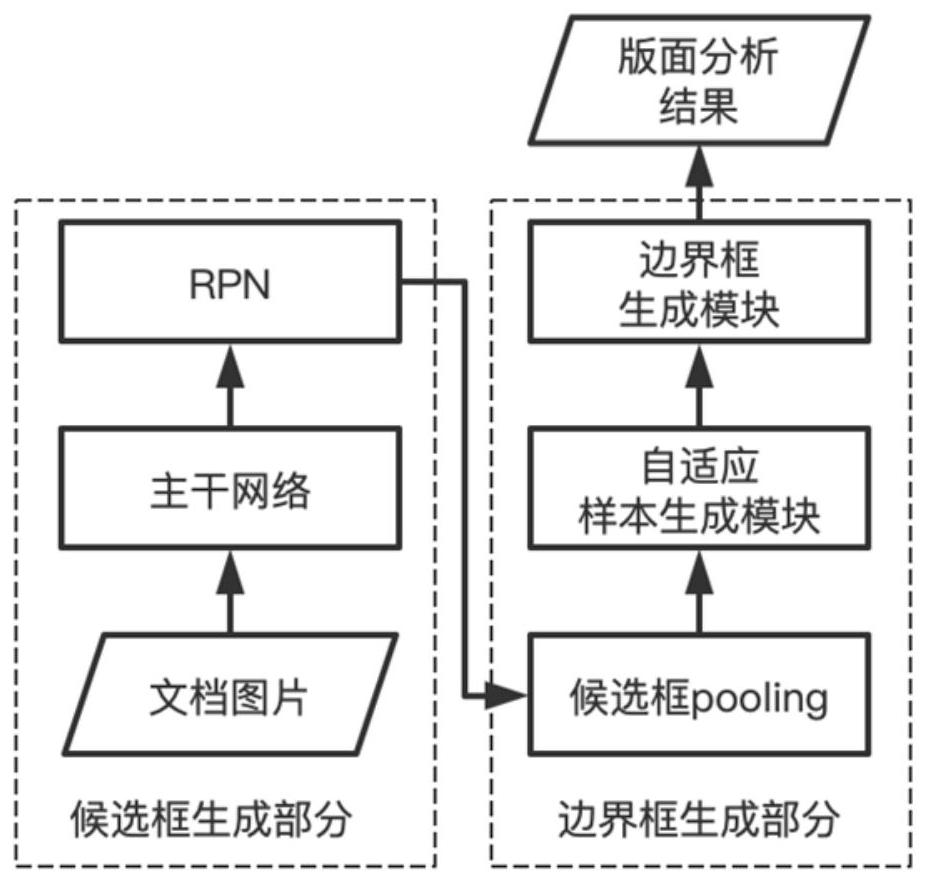
4、(2)构建tala模型,并用训练集数据训练tala模型,得到训练好的tala模型;所述构建tala模型,具体为:构建tala模型的候选框生成部分和边界框生成部分;
5、所述候选框生成部分用于生成候选框并预测所述候选框是否包含版面元素;
6、所述边界框生成部分用于判断所述候选框是否包含版面元素;若包含,则生成对应的边界框并预测边界框对应的版面元素类别;所述版面元素类别分为:书名、一级标题、二级标题、三级标题、图、表、公式、正文、页眉、页脚、参考文献、目录和注释;
7、(3)用训练好的tala模型对测试集进行版面分析,得到边界框的左上角坐标、宽、高和类别。
8、进一步地,所述步骤(2)中,构建tala模型的候选框生成部分,具体为:tala模型通过主干网络和rpn来获得候选框;候选框由其左上角xy轴坐标、框宽、框高和类别表示,根据候选框中是否包含版面元素将类别分为两类;首先,tala模型用transformer作为主干网络来计算图片的特征图,将图片输入transformer中,输出为图片的特征图;然后,tala模型用rpn生成特征图中的候选框;其中,版面元素包括书名、一级标题、二级标题、三级标题、图、表、公式、正文、页眉、页脚、参考文献、目录和注释。
9、进一步地,所述rpn由两层全连接层和左右两个分支构成,其中第1个全连接层将特征图做为输入,第2个全连接层将第1个全连接层的输出分别输入到左右两个分支,左分支为包含4个节点的单层神经网络,用于预测候选框左上角xy轴坐标、框宽和框高,右分支由包含2个节点的单层神经网络+softmax构成,用于预测候选框中是否包含版面元素。
10、进一步地,所述候选框的左上角xy轴坐标、框宽和框高的初始值设定,具体为:特征图中每个像素点对应9个候选框,像素点为9个候选框的共同中心点,按照不同的高宽比例,将这9个候选框宽和高的初始值分别设定为(128,128)、(64,128)、(128,64)、(256,256)、(128,256)、(256,128)、(512,512)、(256,512)和(512,256),其单位为图片中的像素,框左上角xy轴坐标根据x=xc-w/2,y=yc-h/2计算得到,其中x、y、xc、yc、w和h分别为框左上角xy轴坐标、中心点xy轴坐标、框宽和框高;所述预测候选框中是否包含版面元素,具体为:根据候选框与标注框的交并比大于或等于0.5的定为包含版面元素的样本,交并比大于0并小于0.3的候选框定为不包含版面元素的样本,将交并比在0.3-0.5之间的样本舍弃;候选框与标注框的交并比的计算方法为:交并比=候选框与标注框交集的面积/候选框与标注框并集的面积;所述标注框是通过人工标注的方式标注训练集中的每一张图片的版面元素得到。
11、进一步地,tala模型采用多任务学习方式进行候选框左上角xy轴坐标、框宽和框高的预测,以及对候选框中是否包含版面元素进行分类,损失函数如下:
12、lossrpn=rloc+rcls
13、
14、
15、其中,lossrpn为rpn中多任务学习的总损失函数,rloc为预测候选框位置的损失函数,rcls为候选框类别分类的损失函数,xri、yri、wri和hri分别表示第i个候选框左上角xy轴坐标、框宽、框高的预测值,xti、yti、wti、hti分别表示对应标注框左上角xy轴坐标、框宽、框高的预测值,n为标注框总数;ai为调节因子,当第i个候选框对应包含版面元素的样本时ai=1,否则ai=0;cross_entropy表示交叉熵,cri、cti分别表示候选框和对应标注框的类别。
16、进一步地,所述步骤(2)中,构建tala模型的边界框生成部分,具体为:tala模型通过候选框pooling、自适应样本生成模块和边界框生成模块来生成边界框;边界框由其左上角xy轴坐标、框宽、框高和类别表示;
17、在候选框pooling中,tala模型在特征图中找出候选框对应的子特征图,并将候选框对应的子特征图的维度下采样为固定维度;
18、在自适应样本生成模块中,根据候选框与标注框的交并比阈值来判断候选框中是否包含版面元素,并输出包含版面元素的候选框,自适应样本生成模块中的交并比阈值根据训练过程中每轮迭代的结果计算得到的,即每轮迭代时使用的交并比阈值不同,计算方法为:所述交并比阈值=(numfirst-numsecond)/numsecond×ioufirst,其中,numfirst表示在上一轮迭代中包含版面元素的候选框数量,numsecond表示在本轮迭代中包含版面元素的候选框数量,ioufirst表示上一轮迭代中采用的交并比阈值,在第一轮迭代中,交并比阈值为0.5;候选框与标注框的交并比大于等于所述交并比阈值的候选框定为包含版面元素的样本,否则定为不包含版面元素的样本;
19、在边界框生成模块中,边界框的初始值为自适应样本生成模块输出的候选框;边界框生成模块由两层全连接层和左右两个分支构成,其中第1个全连接层将自适应样本生成模块输出的包含版面元素的候选框做为输入;第2个全连接层将第1个全连接层的输出分别输入到左右两个分支,左分支为包含52个节点的单层神经网络,用于预测边界框左上角xy轴坐标、框宽和框高,右分支由包含13个节点的单层神经网络+softmax构成,用于预测边界框对应的版面元素类别。
20、进一步地,tala模型采用多任务学习方式进行边界框左上角xy轴坐标、框宽和框高的预测,以及对边界框中包含的版面元素进行分类,损失函数如下:
21、lossbbox=lossloc+losscls
22、
23、
24、其中,lossbbox为边界框生成模块中多任务学习的总损失函数,lossloc为预测边界框位置的损失函数,losscls为边界框类别分类的损失函数,xbi、ybi、wbi和hbi分别表示第i个边界框左上角xy轴坐标、框宽、框高的预测值,xti、yti、wti、hti分别表示对应标注框左上角xy轴坐标、框宽、框高的预测值,cbi、cti分别表示边界框和对应标注框的类别。
25、进一步地,所述候选框、标注框和边界框的形状均为矩形。
26、一种基于自适应样本生成的教材版面分析的装置,包括一个或多个处理器,用于实现上述的一种基于自适应样本生成的教材版面分析方法。
27、一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,用于实现上述的一种基于自适应样本生成的教材版面分析方法。
28、本发明的有益效果为:在模型训练中,与固定的交并比阈值相比,通过自适应方式计算阈值可以提高模型效果,使模型更加准确地识别教材中版面元素的位置和类别;与多边形框相比,候选框、标注框和边界框采用矩形框时,模型仅需要预测左上角xy轴坐标、框宽、框高和类别,共5种信息,降低了模型中全连接层的节点数,减少了模型参数,进而减少模型在训练和预测时的时间复杂度,提高运算速度,且可应用于智能教育中教材文档图片的版面分析、文本-图像多模态知识图谱的构建等等。
- 还没有人留言评论。精彩留言会获得点赞!