本发明涉及电力语言文本的识别,具体地涉及一种顾及电力特征的地址分词深度学习模型构建方法及系统。
背景技术:
1、在电力行业中,不同电力系统中的配电节点位置通常采用系统内的规定命名。这些规定命名在系统外并没有与通用地址建立统一的对应联系,只能依靠工作人员的人为经验来进行区域划分,人工对地址的归属进行分类。这样的方式会导致电力系统的信息对接不畅,从而降低整体的工作效率。
技术实现思路
1、本发明实施例的目的是提供一种顾及电力特征的地址分词深度学习模型构建方法及系统,该构建方法及系统能够将通用地址高效转换为电力地址。
2、为了实现上述目的,本发明实施例提供一种顾及电力特征的地址分词深度学习模型构建方法,包括:
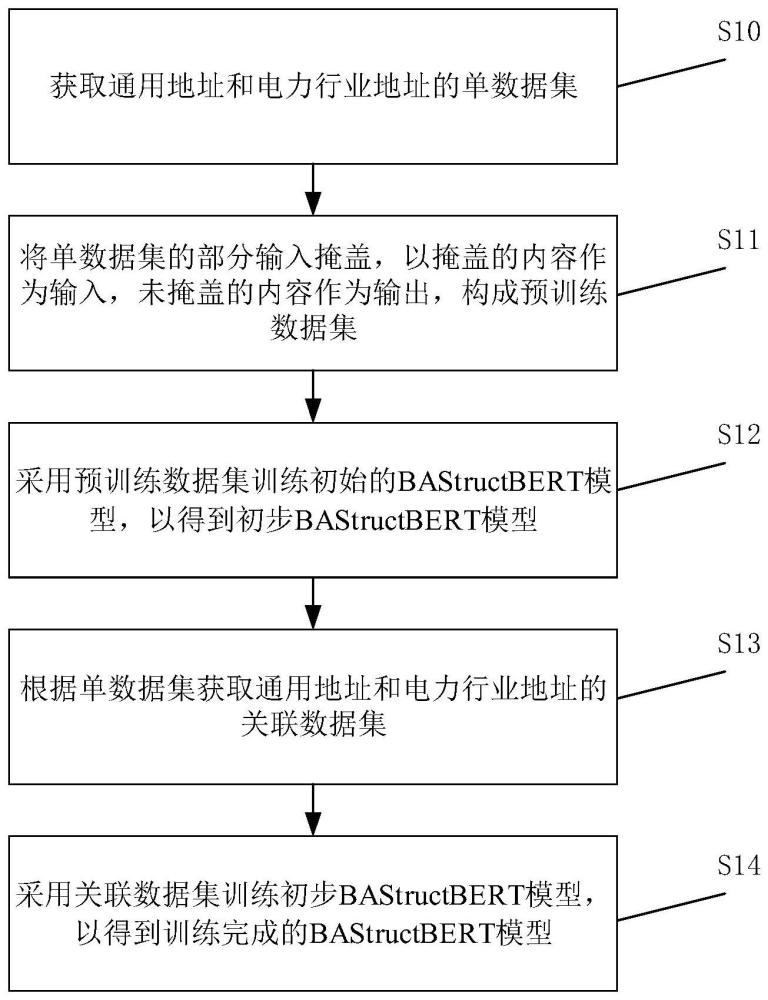
3、获取通用地址和电力行业地址的单数据集;
4、将所述单数据集的部分输入掩盖,以掩盖的内容作为输入,未掩盖的内容作为输出,构成预训练数据集;
5、采用所述预训练数据集训练初始的bastructbert模型,以得到初步bastructbert模型;
6、根据所述单数据集获取通用地址和电力行业地址的关联数据集;
7、采用所述关联数据集训练所述初步bastructbert模型,以得到训练完成的所述bastructbert模型。
8、可选地,根据所述单数据集获取通用地址和电力行业地址的关联数据集,包括:
9、获取通用地址的大数据样本;
10、采用bastructbert模型对所述大数据样本进行分词和编码,以得到对应的通用编码向量;
11、对电力文本进行特征提取,以得到电力编码向量;
12、将所述通用编码向量和电力编码向量关联,以得到所述关联数据集。
13、可选地,采用所述预训练数据集训练初始的bastructbert模型,以得到初步bastructbert模型,包括:
14、采用公式(1)至公式(3)作为训练初始的bastructbert模型的损失函数,
15、l(θ,θ1,θ2)=l1(θ,θ1)+l2(θ,θ2), (1)
16、
17、
18、其中,l(θ,θ1,θ2)为所述损失函数,θ为所述bastructbert模型的encoder部分的参数,θ1为mlm任务在encoder上所接的输出层中的参数,θ2为句子预测任务中在encoder接上的分类器参数,m为预训练数据集的数据量,m表示被掩盖的词集合,p为句向量,|v|表示词典大小,mi、mj表示第i个和第j个词向量,isnext、notnext表示分类标签;
19、采用公式(4)更新初始的初步bastructbert模型的权重参数,
20、arg maxθ∑log p(pos1=t1,pos2=t2,...,posk=tk|t1,t2,...,tk,θ),(4)
21、其中,p为句向量,pos1、pos2、posk表示token的位置,t1、t2、tk为表示单词。
22、可选地,采用所述关联数据集训练所述初步bastructbert模型,以得到训练完成的所述bastructbert模型,包括:
23、根据预设的电力地址要求对所述初步bastructbert模型的输出层前的层级进行微调;
24、固定所述输出层前的层级的权重,采用所述关联数据集训练调参所述输出层,以得到训练完成的所述bastructbert模型。
25、可选地,固定所述输出层前的层级的权重,采用所述关联数据集训练调参所述输出层,以得到训练完成的所述bastructbert模型,包括:
26、采用公式(5)和公式(6)作为所述输出层的输出,
27、p=softmax(cwt), (5)
28、其中,c为最终隐藏层向量,wt为分类层权重,p为分类结果的概率;
29、
30、其中,pi为分类至第i个类别的概率,v为输出向量,cj为第j个类别的最终隐藏层向量。
31、另一方面,本发明还提供一种顾及电力特征的地址分词深度学习模型构建系统,所述构建系统包括处理器,所述处理器被配置成用于:
32、获取通用地址和电力行业地址的单数据集;
33、将所述单数据集的部分输入掩盖,以掩盖的内容作为输入,未掩盖的内容作为输出,构成预训练数据集;
34、采用所述预训练数据集训练初始的bastructbert模型,以得到初步bastructbert模型;
35、根据所述单数据集获取通用地址和电力行业地址的关联数据集;
36、采用所述关联数据集训练所述初步bastructbert模型,以得到训练完成的所述bastructbert模型。
37、可选地,所述处理器用于:
38、获取通用地址的大数据样本;
39、采用bastructbert模型对所述大数据样本进行分词和编码,以得到对应的通用编码向量;
40、对电力文本进行特征提取,以得到电力编码向量;
41、将所述通用编码向量和电力编码向量关联,以得到所述关联数据集。
42、可选地,所述处理器用于:
43、采用公式(1)至公式(3)作为训练初始的bastructbert模型的损失函数,
44、l(θ,θ1,θ2)=l1(θ,θ1)+l2(θ,θ2), (1)
45、
46、
47、其中,l(θ,θ1,θ2)为所述损失函数,θ为所述bastructbert模型的encoder部分的参数,θ1为mlm任务在encoder上所接的输出层中的参数,θ2为句子预测任务中在encoder接上的分类器参数,m为预训练数据集的数据量,m表示被掩盖的词集合,p为句向量,|v|表示词典大小,mi、mj表示第i个和第j个词向量,isnext、notnext表示分类标签;
48、采用公式(4)更新初始的初步bastructbert模型的权重参数,
49、arg maxθ∑logb(pos1=t1,pos2=t2,...,posk=tk|t1,t2,...,tk,θ),(4)
50、其中,b为句向量,pos1、pos2、posk表示token的位置,t1、t2、tk为表示单词。
51、可选地,所述处理器用于:
52、根据预设的电力地址要求对所述初步bastructbert模型的输出层前的层级进行微调;
53、固定所述输出层前的层级的权重,采用所述关联数据集训练调参所述输出层,以得到训练完成的所述bastructbert模型。
54、可选地,所述处理器用于:
55、采用公式(5)和公式(6)作为所述输出层的输出,
56、p=softmax(cwt), (5)
57、其中,c为最终隐藏层向量,wt为分类层权重,p为分类结果的概率;
58、
59、其中,pi为分类至第i个类别的概率,v为输出向量,cj为第j个类别的最终隐藏层向量。
60、通过上述技术方案,本发明提供了一种顾及电力特征的地址分词深度学习模型构建方法及系统,该构建方法及系统通过结合通用地址和电力行业地址的单数据集、将单数据集的部分输入掩盖得到的预训练数据集,分别对bastructbert模型进行固定部分权重的两步训练,使得生成的bastructbert模型既具备较高的地址输入的识别能力,也具备完成的电力行业地址的转换能力。
61、本发明实施例的其它特征和优点将在随后的具体实施方式部分予以详细说明。