一种基于机器学习的四川烟叶品质评价方法、系统及其应用
本发明属于作物质量评价和机器学习,具体涉及一种基于机器学习的四川烟叶品质评价方法、系统及其应用。
背景技术:
1、公开该背景技术部分的信息仅仅旨在增加对本发明的总体背景的理解,而不必然被视为承认或以任何形式暗示该信息构成已经成为本领域一般技术人员所公知的现有技术。
2、四川省是我国重要的优质烟叶生产基地、卷烟工业原料核心产区,烟叶产量连续多年位居全国第三位,生态决定特色,正由于其特殊的生态环境造就了独特的优质烟叶风格特征。机器学习(machine learning,ml)作为一种人工智能的实现方式,正如其名,就是脱离人工干预让机器进行自动学习,通过不断尝试、调整,最终选择趋近于目标最大回报的实现路径。在寻找共性、区分差异问题上,机器学习具有传统手段难以比拟的优势,积极应用机器学习算法客观地、因地制宜地评价四川烟叶质量特性,对烟叶产区改进生产技术措施、工业企业合理利用烟叶原料具有重要的指导意义。
3、近年来,随着科学技术的飞速发展,不同的机器学习算法已被积极的应用在烟草行业的各个领域,例如产地识别、烟叶分级、霉病判定等。xu等收集9类11849标记烟叶图像数据集,通过卷积神经网络平均分类准确率达到98.4%。jiang等借助随机森林算法构建烟草霉病快速识别模型,独立检验的准确率为94.84%。marcelo等结合近红外成像和支持向量机判别分析,按叶位建立分类模型,烤烟弗吉尼亚的全球预测准确率为80.4%,按颜色建立分类模型预,测准确率为95.9%。liu等结合近红外光谱、电子鼻与支持向量机,预测60个来自烟叶不同部位的未知烟草样品,其测试准确率为81.67%。
4、作为人工智能的热门领域之一,机器学习算法善于通过不同方法分析处理多维数据去除冗余信息,进一步提取事物的本质规律及维度间的复杂联系,全过程无主观因素介入,与卷烟传统感官、化学成分质量评价方法相比,将会更客观、更直接、更准确的反映烟叶品质优劣。但多数高效准确的机器学习模型由于其结构复杂,往往具有透明度欠缺等“黑盒”特性,难以揭示模型内在预测路径、鉴定关键预测因子。
技术实现思路
1、针对上述现有技术的不足,本发明提供一种基于机器学习的四川烟叶品质评价方法、系统及其应用。本发明对比rf、knn、svm、gbc等4种机器学习算法在四川烟叶品质评价上的性能表现,并利用ga对最佳模型超参数进行调整优化,确定最优超参数组合,建立四川烟叶品质评价预测模型。并引入shap value解释框架积极打破“黑盒模型”,科学认知重要特征成分,增强预测数据可解释性,进一步提升评价结果与感官品质的一致性,为机器学习算法在烟草领域的应用以及烟叶质量评价工作提供新思路和数据支持。基于上述研究成果,从而完成本发明。
2、本发明是通过如下技术方案实现的:
3、本发明的第一个方面,提供一种基于机器学习的四川烟叶品质评价方法,包括:
4、获取烤烟原始化学特性信息,对其进行衍生化、标准化处理,构建数据集;
5、将所述数据集分为训练集数据和测试集数据;
6、基于训练集数据构建四川烟叶品质评价机器学习模型;
7、对所述机器学习模型输入测试集数据,获取四川烟叶的品质评价结果;
8、其中,机器学习算法包括随机森林(random forest classifier,rf)、支持向量机(support vector machine,svm)、最近邻(k nearest neighbor classifier,knn)和梯度提升(gradient boosting classifier,gbc);
9、所述四川烟叶的品质评价结果分为三个质量档次,即第1质量档次(好)、第2质量档次(中)、第3质量档次(一般)。
10、具体的,所述衍生化处理的具体处理过程中,选择总糖、还原糖、总植物碱、总氮、淀粉、蛋白质6项常规化学指标,以及多酚总量、高级脂肪酸总量、多元酸总量、生物碱总量、单双糖总量、多元醇总量、游离氨基酸总量7项总量指标,共计13项烤烟化学指标作为初始衍生指标,将原始数据量纲统一转换为mg/g,此外,由于烤烟化学信息为连续型变量,为保证数据间关系可解释性,选择“divide_numeric”、“add_numeric”、“subtract_numeric”等3种聚合关系进行批量自动化交叉衍生,交叉深度为2层,生成除法复合指标156项、加减法复合指标156项,共计构建新型衍生特征312项;
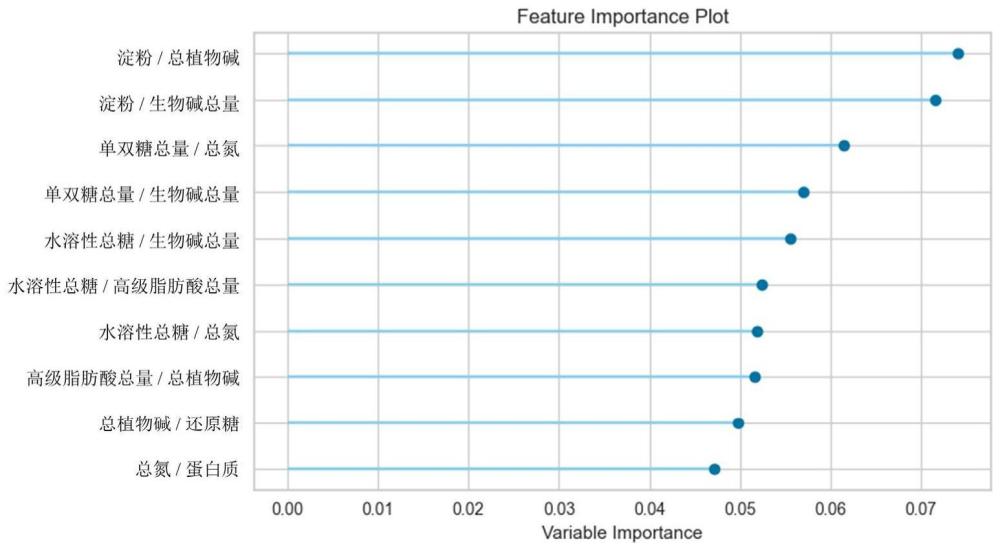
11、进一步的,基于机器学习rf算法筛选获得衍生特征数据集,所述衍生特征数据集包括7项除法复合指标及8项加减法复合指标;其中,7项除法复合指标包括:淀粉/总植物碱、单双糖总量/总氮、单双糖总量/生物碱总量、水溶性总糖/高级脂肪酸总量、高级脂肪酸总量/总植物碱、总植物碱/还原糖和总氮/蛋白质;所述8项加减法复合指标包括水溶性总糖+蛋白质、淀粉+还原糖、水溶性总糖+还原糖、多元酸总量+水溶性总糖、多元醇总量+总植物碱、淀粉-生物碱总量、水溶性总糖-单双糖总量和水溶性总糖-淀粉。
12、进一步的,所述数据集中还包括关键化学指标,所述关键化学指标则是基于mantel检验获得,具体的,将感官多元变量组作为一个距离矩阵,每个化学变量作为另一个矩阵,实现2个距离矩阵形式间的回归性分析;
13、所述关键化学指标包括总糖、还原糖、总植物碱、淀粉、丙二酸、丁二酸、棕榈酸、亚油酸、亚麻酸、高级脂肪酸总量、烟碱、降烟碱、假木贼碱、麦斯明、生物碱总量、葡萄糖、蔗糖、单双糖总量、精氨酸、组氨酸、碱性氨基酸总量、苯丙氨酸和缬氨酸。
14、进一步的,所述机器学习算法为rf,进一步为基于遗传算法(genetic algorithm,ga)优化的rf模型,ga是一类通过模拟自然界生物优胜劣汰进化原则的随机搜索算法,对于高度复杂的非线性问题有较好的表现,可以实现从局部最优到全局最优的跨越,极大程度的发挥模型算法优秀性能,因此选择利用ga高效空间搜索能力确定最优rf模型及最优超参数组合。ga设置初始种群为100,最大迭代次数为50次,误差精度为1*10-6,编码方式为实整数编码(ri)。影响rf模型的超参数有十余种,仅考虑单独某个参数难以确定模型最优参数组合。因此,经前期调试后,选取较为重要的6个超参数(树木数量、最大特征数、最大深度、分枝最小样本量、叶节点最小样本量和信息增益限制)进行全局寻优,ga寻找优结果分别为21、27、13、11、2和0.00,其余超参数均设置为默认值。
15、进一步的,所述方法还包括使用shap value对四川烟叶品质评价机器学习模型进行关键特征解析,增强预测数据可解释性,进一步提升评价结果与感官品质的一致性;
16、进一步的,所述关键特征包括:淀粉+还原糖、组氨酸、碱性氨基酸、单双糖总量/总氮、淀粉/总植物碱、总植物碱/还原糖和蔗糖。
17、进一步的,所述四川烟叶的品质评价的结果是选用层次聚类(hierarchicalclustering)对试样材料类别进行客观划分的,其依据感官多元变量组判定试样品质的亲疏情况,使所得各质量档次更加合理和准确。
18、本发明的第二个方面,提供一种基于机器学习的四川烟叶品质评价系统,所述系统包括:
19、烤烟化学信息获取模块,其被配置为:获取烤烟原始化学信息数据;
20、烤烟化学信息预处理模块,其被配置为:对获取的烤烟原始化学信息数据进行衍生化及标准化处理获得数据集;
21、机器学习模型模块,其被配置为:提取训练集和测试集数据,基于训练集数据构建四川烟叶品质评价机器学习模型;机器学习算法包括随机森林、支持向量机、最近邻和梯度提升;
22、输出模块,其被配置为:基于上述建立的机器学习模型模块,输入测试集数据,输出待测四川烟叶的品质评价结果;其中,所述四川烟叶的品质评价结果分为三个质量档次,即第1质量档次(好)、第2质量档次(中)、第3质量档次(一般)。
23、进一步的,所述系统运行时执行上述基于机器学习的四川烟叶品质评价方法所进行的步骤。
24、本发明的第三个方面,提供一种非暂态计算机程序产品,所述非暂态计算机程序产品包括存储在计算机能够读的介质上的计算机能够执行的代码段,所述计算机能够执行的代码段用于执行上述基于机器学习的四川烟叶品质评价方法所进行的步骤。
25、本发明的第四个方面,提供一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成上述基于机器学习的四川烟叶品质评价方法所进行的步骤。
26、本发明的第五个方面,提供上述方法、系统、非暂态计算机程序产品以及计算机可读存储介质在烟草质量评价领域中的应用。
27、上述一个或多个技术方案的有益技术效果:
28、上述技术方案以四川烤烟为主体研究对象,对比rf、knn、svm、gbc等4种机器学习算法在四川烤烟品质预测的性能差异,采用ga超参数寻优进一步探索模型预测上限,并创新性地引入shap value模型解释框架进行全局解释与特征依赖分析。结果表明,模型预测accuracy表现为:rf>gbc>knn>svm,所建ga-rf机器学习模型预测准确率达86.8%,同时shap value识别到7个影响四川烟叶质量的重要特征指标。
29、综上,rf是四川烤烟品质预测最佳模型分类器,上述技术方案提出的ga-rf可实现四川烟叶品质的有效识别,研究结果以期为机器学习算法在烟草领域的应用以及烟叶质量评价工作提供新思路和数据支持,因此具有良好的实际应用之价值。
- 还没有人留言评论。精彩留言会获得点赞!